Checkpoints
Enable the Data Catalog API
/ 10
Create the SQLServer Database
/ 10
Set Up the Service Account for SQLServer
/ 10
Execute SQLServer to Data Catalog connector
/ 10
Create the PostgreSQL Database
/ 10
Create a Service Account for postgresql
/ 10
Execute PostgreSQL to Data Catalog connector
/ 10
Create the MySQL Database
/ 10
Create a Service Account for MySQL
/ 10
Execute MySQL to Data Catalog connector
/ 10
Build and Execute MySQL, PostgreSQL, and SQLServer to Data Catalog Connectors
GSP814

Overview
Dataplex is an intelligent data fabric that enables organizations to centrally discover, manage, monitor, and govern their data across data lakes, data warehouses, and data marts to power analytics at scale.
Data Catalog is a fully managed, scalable metadata management service within Dataplex. It offers a simple and easy-to-use search interface for data discovery, a flexible and powerful cataloging system for capturing both technical and business metadata, and a strong security and compliance foundation with Cloud Data Loss Prevention (DLP) and Cloud Identity and Access Management (IAM) integrations.
Using Data Catalog
Using Data Catalog within Dataplex, you can search for assets to which you have access, and you can tag data assets to support discovery and access control. Tags allow you to attach custom metadata fields to specific data assets for easy identification and retrieval (such as tagging certain assets as containing protected or sensitive data); you can also create reusable tag templates to rapidly assign the same tags to different data assets.
Objectives
In this lab, you will learn how to:
- Enable the Data Catalog API.
- Configure Dataplex connectors for SQL Server, PostgreSQL, and MySQL.
- Search for SQL Server, PostgreSQL, and MySQL entries in Data Catalog within Dataplex.
Prerequisites
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Task 1. Enable the Data Catalog API
-
Open the Navigation menu and select APIs and Services > Library.
-
In the search bar, enter in "Data Catalog" and select the
Google Cloud Data Catalog API. -
Then click Enable.
Click Check my progress to verify the objective.
Task 2. SQL Server to Dataplex
Start by setting up your environment.
-
Open a new Cloud Shell session by clicking the Activate Cloud Shell icon in the top right of the console:
-
Run the following command to set your Project ID as an environment variable:
Create the SQL Server database
- In your Cloud Shell session, run the following command to download the scripts to create and populate your SQL Server instance:
- Now change your current working directory to the downloaded directory:
- Run the following command to change the region from
us-central1to your default assigned region:
- Now run the
init-db.shscript.
This will create your SQL Server instance and populate it with a random schema.
Error: Failed to load "tfplan" as a plan file, re-run the init-db script.
This will take around 5 to 10 minutes to complete. You can move on when you receive the following output:
Click Check my progress to verify the objective.
Set up the Service Account
- Run the following command to create a Service Account:
- Now create and download the Service Account Key.
- Add the Data Catalog admin role to the Service Account:
Click Check my progress to verify the objective.
Execute SQL Server to Dataplex connector
You can build the SQL Server connector yourself by going to this GitHub repository.
To facilitate its usage, we are going to use a docker image.
The variables needed were output by the Terraform config.
- Change directories into the location of the Terraform scripts:
- Grab the environment variables:
- Change back to the root directory for the example code:
- Run the following command to execute the connector:
Soon after you should receive the following output:
Click Check my progress to verify the objective.
Search for the SQL Server Entries in Dataplex
-
After the script finishes, open the navigation menu and select Dataplex from the list of services.
-
In the the Dataplex page, click on Tag Templates.
You should see your sqlserver Tag Templates listed.
- Next, select Entry Groups.
You should see the sqlserver Entry Group in the Entry Groups list:
- Now click on the
sqlserverEntry Group. Your console should resemble the following:
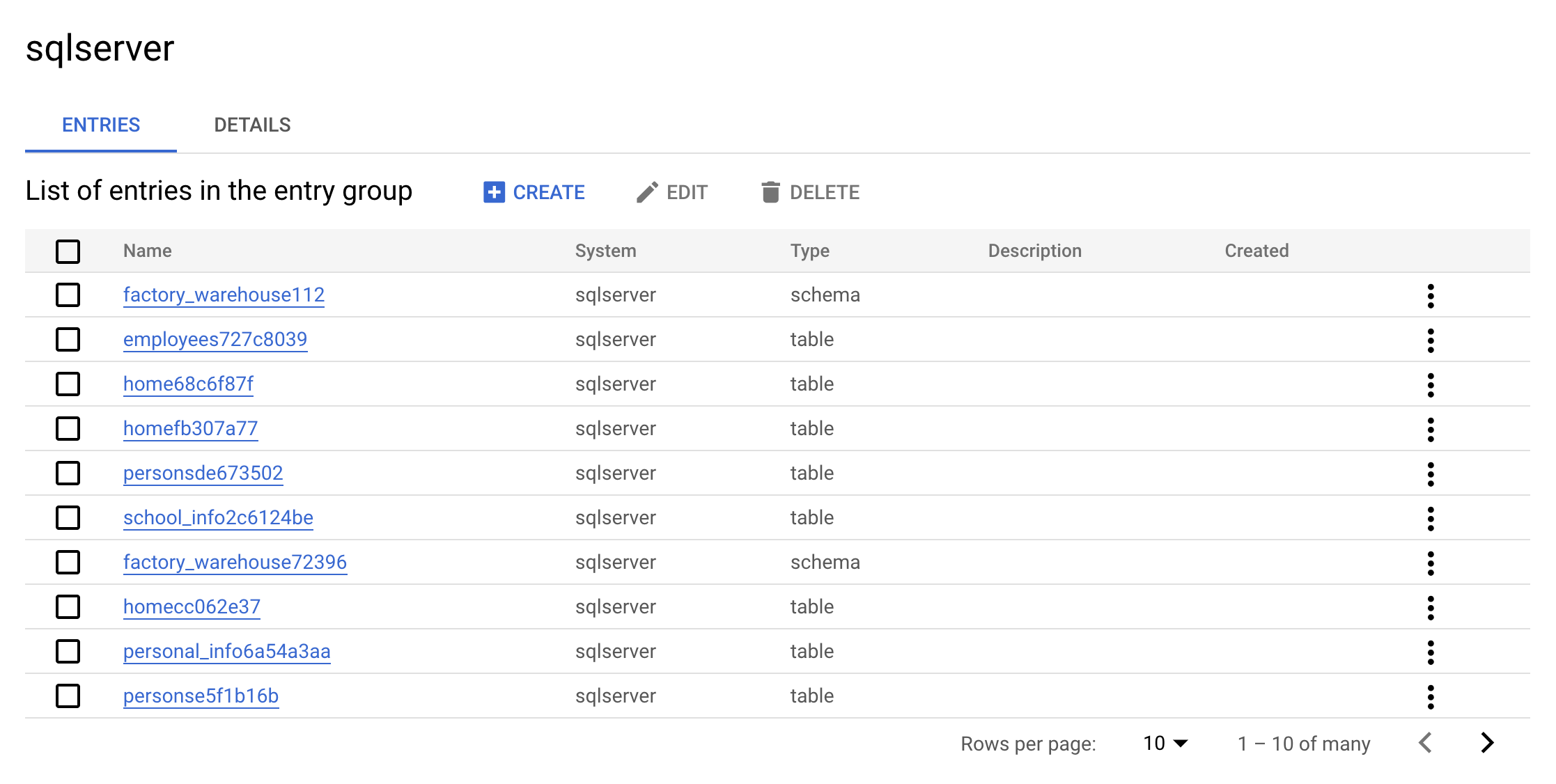
This is the real value of an Entry Group—you can see all entries that belong to sqlserver using the UI.
- Click on one of the
warehouseentries. Look at the Custom entry details and tags.
This is the real value the connector adds — it allows you to have the metadata searchable in Dataplex.
Clean up
- To delete the created resources, run the following command to delete the SQL Server metadata:
- Now execute the cleaner container:
- Now run the following command to delete the SQL Server database:
-
From the Navigation menu click Dataplex.
-
Search for sqlserver.
You will no longer see the SQL Server Tag Templates in the results:
Ensure you see the following output in Cloud Shell before you move on:
You will now learn how to do the same thing with a PostgreSQL instance.
Task 3. PostgreSQL to Dataplex
Create the PostgreSQL Database
- Run the following command in Cloud Shell to return to your home directory:
- Run the following command to clone the Github repository:
- Now change your current working directory to the cloned repo directory:
- Run the following command to change the region from
us-central1to your default assigned region:
- Now execute the
init-db.shscript:
This will create your PostgreSQL instance and populate it with a random schema. This can take around 10 to 15 minutes to complete.
Error: Failed to load "tfplan" as a plan file, re-run the init-db script.
Soon after you should receive the following output:
Click Check my progress to verify the objective.
Set up the Service Account
- Create a Service Account:
- Next create and download the Service Account Key:
- Next add Data Catalog admin role to the Service Account:
Click Check my progress to verify the objective.
Execute PostgreSQL to Dataplex connector
You can build the PostgreSQL connector yourself by going to this GitHub repository.
To facilitate its usage, we are going to use a docker image.
The variables needed were output by the Terraform config.
- Change directories into the location of the Terraform scripts:
- Grab the environment variables:
- Change back to the root directory for the example code:
- Execute the connector:
Soon after you should receive the following output:
Click Check my progress to verify the objective.
Check the results of the script
-
Ensure that you are in the Dataplex home page.
-
Click on Tag Templates.
You should see the following postgresql Tag Templates:

- Click on Entry groups.
You should see the following postgresql Entry Group:

- Now click on the
postgresqlEntry Group. Your console should resemble the following:
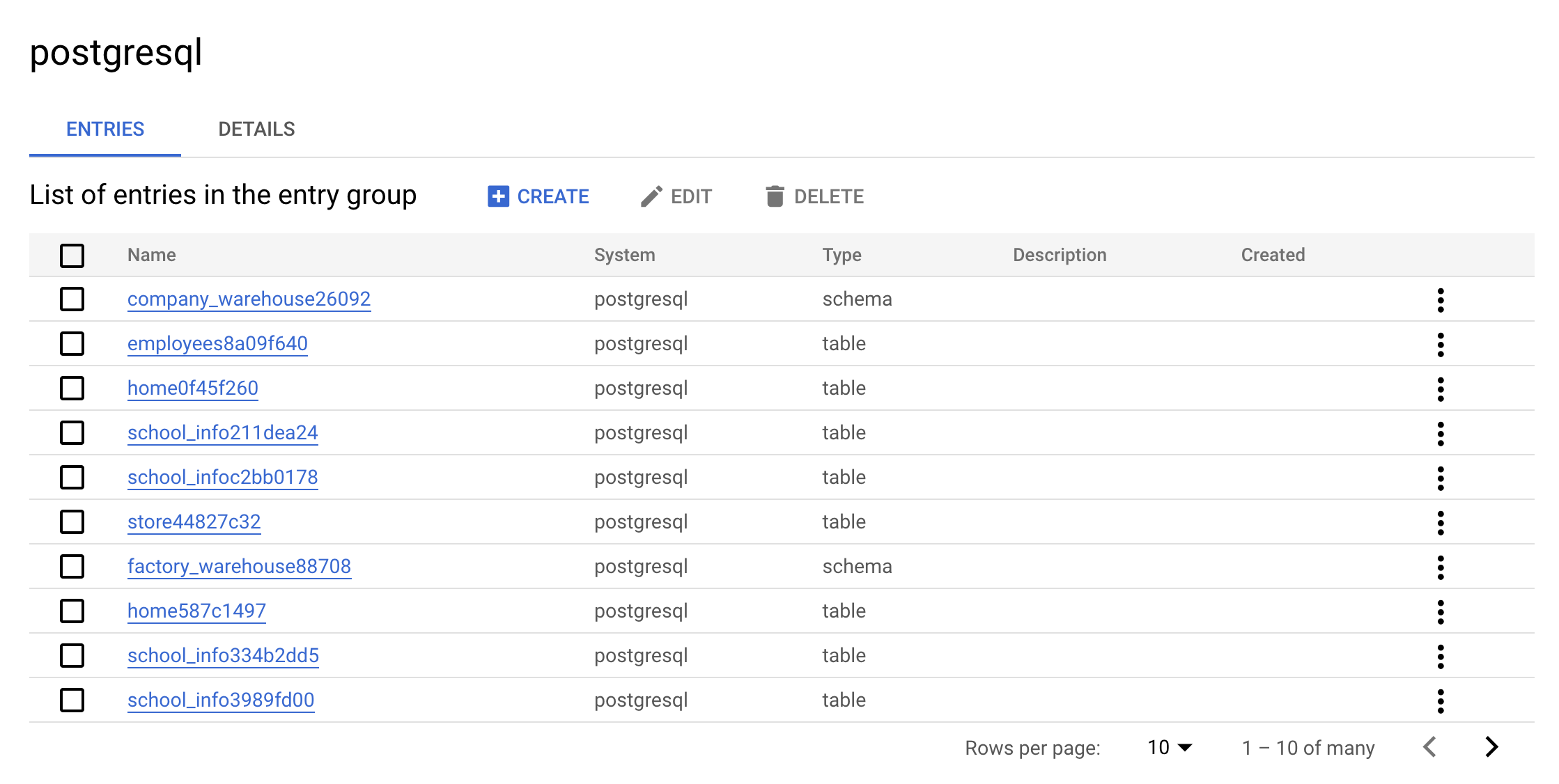
This is the real value of an Entry Group — you can see all entries that belong to postgresql using the UI.
- Click on one of the
warehouseentries. Look at the Custom entry details and tags:
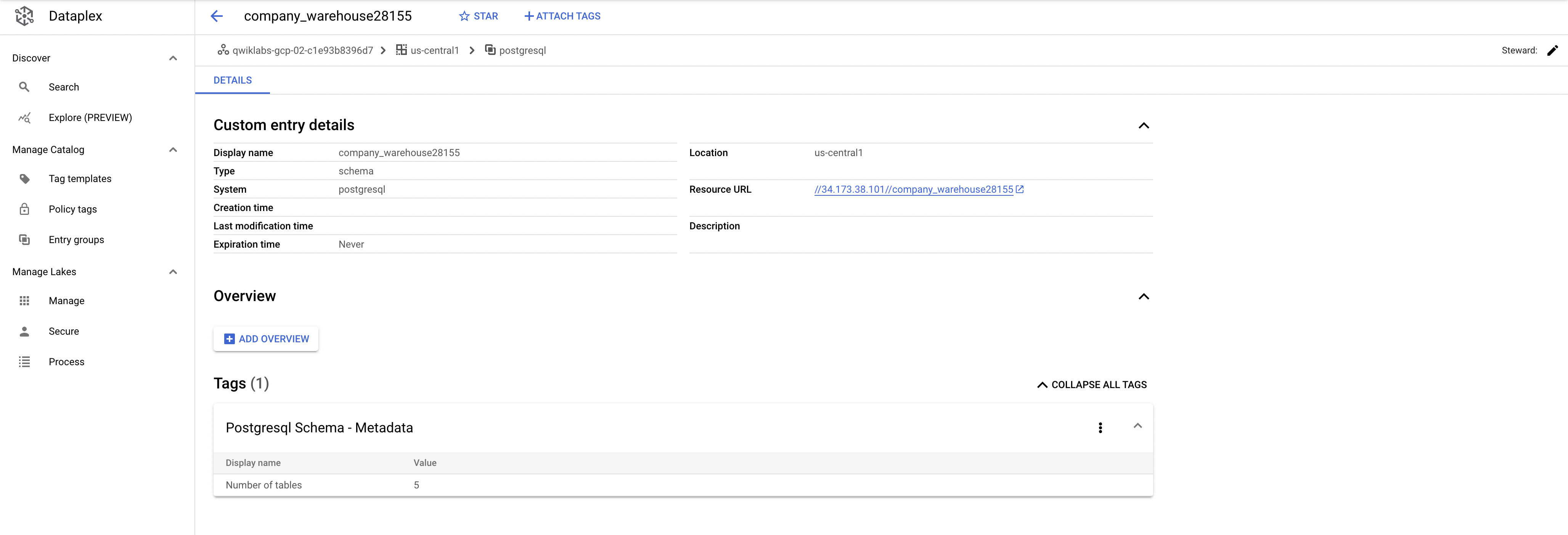
This is the real value the connector adds—it allows you to have the metadata searchable in Dataplex.
Clean up
- To delete the created resources, run the following command to delete the PostgreSQL metadata:
- Now execute the cleaner container:
- Finally, delete the PostgreSQL database:
-
Now, from the Navigation menu click on Dataplex.
-
Search for PostgreSQL. You will no longer see the PostgreSQL Tag Templates in the results:
Ensure you see the following output in Cloud Shell before you move on:
You will now learn how to do the same thing with a MySQL instance.
Task 4. MySQL to Dataplex
Create the MySQL database
- Run the following command in Cloud Shell to return to your home directory:
- Run the following command to download the scripts to create and populate your MySQL instance:
- Now change your current working directory to the cloned repo directory:
- Run the following command to change the region from
us-central1to your default assigned region:
- Next execute the
init-db.shscript:
This will create your MySQL instance and populate it with a random schema. After a few minutes, you should receive the following output:
Error: Failed to load "tfplan" as a plan file, re-run the init-db script.
Click Check my progress to verify the objective.
Set up the Service Account
- Run the following to create a Service Account:
- Next, create and download the Service Account Key:
- Next add Data Catalog admin role to the Service Account:
Click Check my progress to verify the objective.
Execute MySQL to Dataplex connector
You can build the MySQL connector yourself by going to this GitHub repository.
To facilitate its usage, this lab uses a docker image.
The variables needed were output by the Terraform config.
- Change directories into the location of the Terraform scripts:
- Grab the environment variables:
- Change back to the root directory for the example code:
- Execute the connector:
Soon after you should receive the following output:
Click Check my progress to verify the objective.
Check the results of the script
-
Ensure that you are in the Dataplex home page.
-
Click on Tag Templates.
You should see the following mysql Tag Templates:

- Click on Entry groups.
You should see the following mysql Entry Group:

- Now click on the
mysqlEntry Group. Your console should resemble the following:
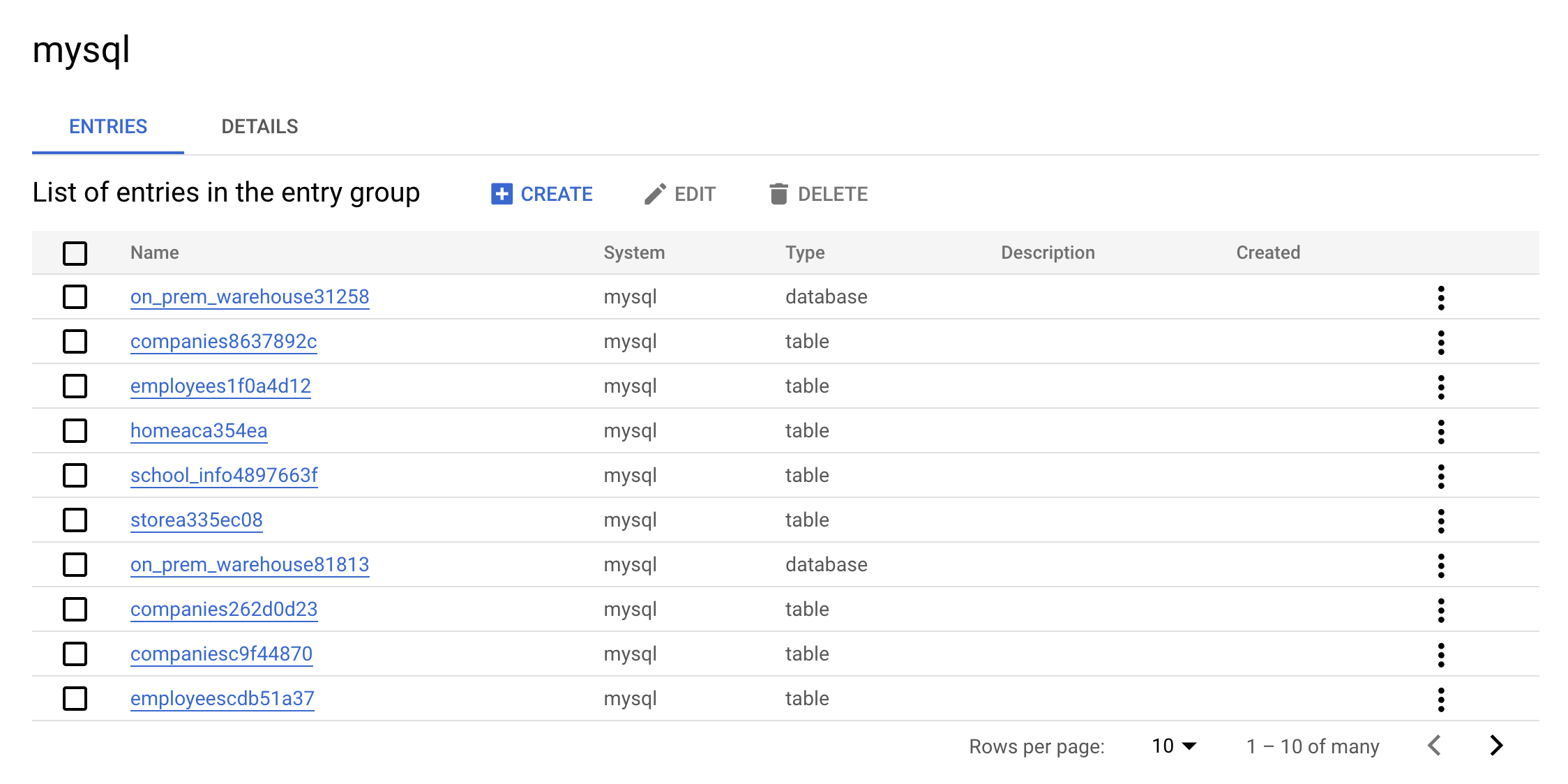
This is the real value of an Entry Group — you can see all entries that belong to MySQL using the UI.
- Click on one of the
warehouseentries. Look at the Custom entry details and tags.
This is the real value the connector adds — it allows you to have the metadata searchable in Dataplex.
Clean up
- To delete the created resources, run the following command to delete the MySQL metadata:
- Now execute the cleaner container:
- Finally, delete the PostgreSQL database:
-
From the Navigation menu click Dataplex.
-
Search for MySQL. You will no longer see the MySQL Tag Templates in the results.
Ensure you see the following output in Cloud Shell before you move on:
Congratulations!
Congratulations! In this lab, you learned how to build and execute MySQL, PostgreSQL, and SQL Server to Dataplex connectors. You also learned how to search for SQL Server, PostgreSQL, and MySQL entries in Data Catalog within Dataplex. You can now use this knowledge to build your own connectors.
Finish your course
This self-paced lab is part of the BigQuery for Data Warehousing, BigQuery for Marketing Analysts, and Data Catalog Fundamentals courses. See the Google Cloud Skills Boost catalog to see all available courses.
Next steps / Learn more
- Read the Data Catalog Overview
- Learn How to search with Data Catalog
- Browse the Overview of APIs and Client Libraries
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated October 17, 2023
Lab Last Tested October 17, 2023
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.