Checkpoints
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
Como explorar a otimização de custos para máquinas virtuais do GKE
GSP767

Visão geral
A infraestrutura de um cluster do Google Kubernetes Engine é composta de nós que são instâncias individuais de VMs do Compute. Neste laboratório, vamos examinar como a otimização da infraestrutura do seu cluster pode ajudar a poupar custos e resultar em uma arquitetura mais eficiente para seus aplicativos.
Você vai aprender a estratégia para ajudar a maximizar a utilização e evitar a subutilização dos seus valiosos recursos de infraestrutura, selecionando tipos de máquina com formato adequado para uma carga de trabalho de exemplo. Além do tipo de infraestrutura que você usa, a localização geográfica física dela também afeta o custo. Nesse exercício, vamos explorar como criar uma estratégia econômica para gerenciar clusters regionais de maior disponibilidade.
Atividades deste laboratório
- Examinar o uso de recursos de uma implantação
- Escalonar verticalmente uma implantação
- Migrar sua carga de trabalho para um pool de nós com um tipo de máquina otimizado
- Explorar as opções de locais para seu cluster
- Monitorar registros de fluxo entre pods em diferentes zonas
- Mover um pod de alto tráfego para minimizar os custos de tráfego entre zonas
Pré-requisitos
- Ter familiaridade com máquinas virtuais pode ajudar
Configuração
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Este laboratório gera um pequeno cluster para você usar. O provisionamento do cluster leva de 2 a 5 minutos.
Se você apertou o botão Começar o laboratório e uma mensagem em azul resources being provisioned com um círculo de carregamento foi exibida, seu cluster ainda está sendo criado.
Você já pode conferir as próximas instruções e explicações enquanto espera, mas nenhum comando shell vai funcionar até que seus recursos tenham sido provisionados.
Tarefa 1: como reconhecer tipos de máquinas de nós
Aspectos gerais
Um tipo de máquina é um conjunto de recursos de hardware virtualizados disponíveis para uma instância de máquina virtual (VM), incluindo o tamanho da memória do sistema, a contagem de CPUs virtuais (vCPUs) e os limites de discos permanentes. Os tipos de máquinas são agrupados e selecionados por famílias em diferentes cargas de trabalho.
Ao escolher um tipo de máquina para seu pool de nós, a família de tipos de máquinas de uso geral normalmente oferece a melhor relação entre preço e desempenho para uma variedade de cargas de trabalho. Os tipos de máquinas de uso geral consistem nas séries N e E2:
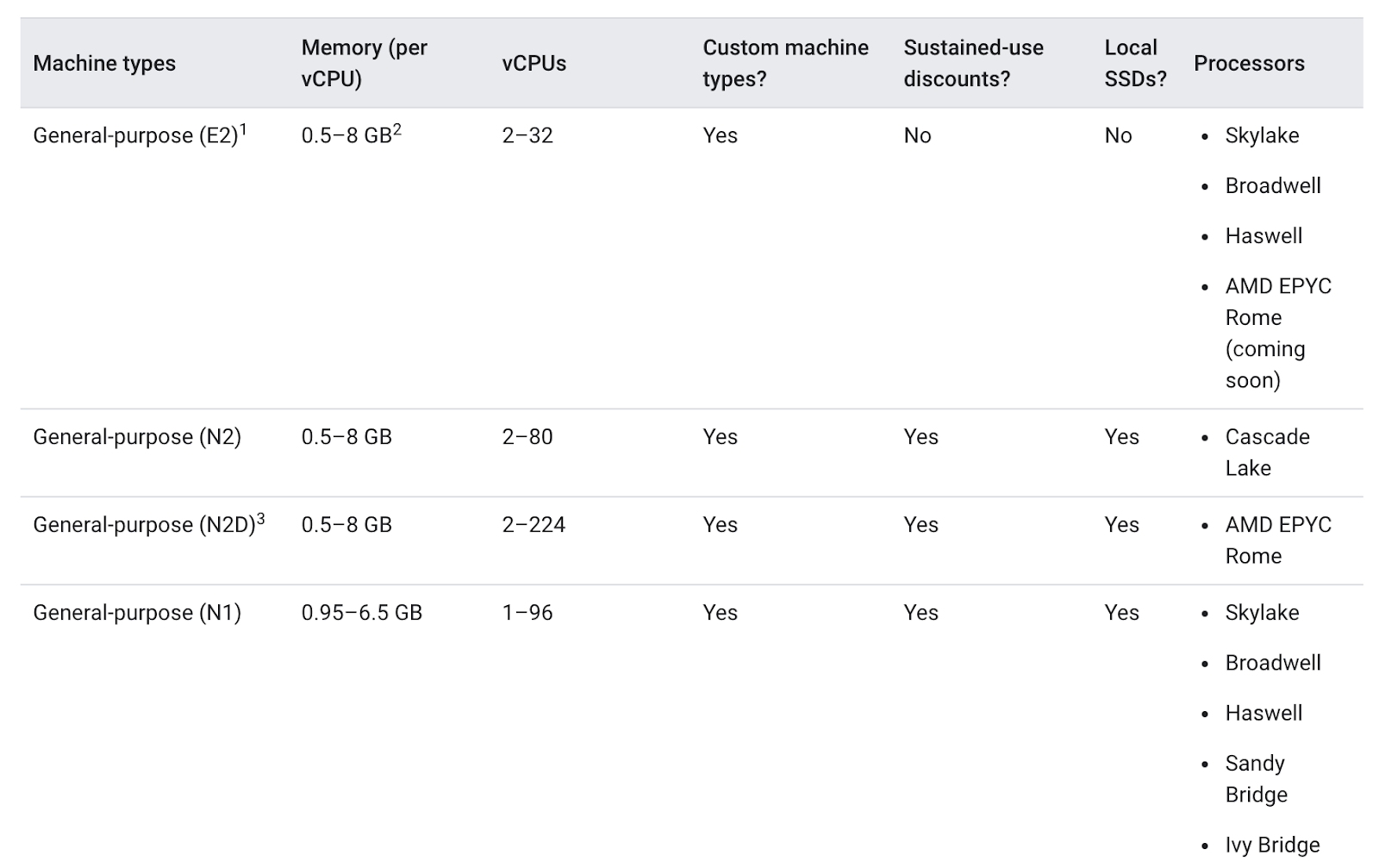
As diferenças entre os tipos de máquinas podem, ou não, ajudar seu app. Em geral, E2s têm desempenho semelhante aos N1s, mas são otimizados em termos de custo. Usar apenas o tipo de máquina E2 pode ajudar a poupar custos.
No entanto, com um cluster, é mais importante que os recursos utilizados sejam otimizados com base nas necessidades do seu aplicativo. Para aplicativos ou implantações maiores que precisam de grande escalabilidade, pode ser mais barato agrupar suas cargas de trabalho em poucas máquinas otimizadas em vez de espalhá-las em muitas máquinas de uso geral.
Entender os detalhes do seu aplicativo é importante para o progresso dessa tomada de decisão, porque se o app tiver requisitos específicos, você vai poder garantir que o tipo de máquina será adaptado para se adequar a ele.
Na seção a seguir, vamos examinar um app de demonstração e fazer a migração dele para um pool de nós com um tipo de máquina bem modelado.
Tarefa 2: como escolher o tipo de máquina certo para o app Hello
Verifique os requisitos do cluster de demonstração do Hello
Na inicialização, seu laboratório gerou um cluster de demonstração do Hello com dois nós E2 médios (2 vCPUs, 4 GB de memória). Este cluster implanta uma réplica de um web app simples chamado App Hello, um servidor da Web escrito em Go que responde a todas as solicitações com a mensagem "Hello, World!".
- Depois que o laboratório concluir o provisionamento, no console do Cloud, clique no menu de navegação e depois em Kubernetes Engine.
-
Na janela Clusters do Kubernetes, selecione seu hello-demo-cluster.
-
Na janela seguinte, selecione a guia Nós:
Uma lista com os nós do cluster vai aparecer:

Confira como o GKE utilizou os recursos do seu cluster. É possível ver os volumes de CPU e de memória que estão sendo solicitados por cada nó, bem como quanto os nós podem alocar.
- Clique no primeiro nó do seu cluster.
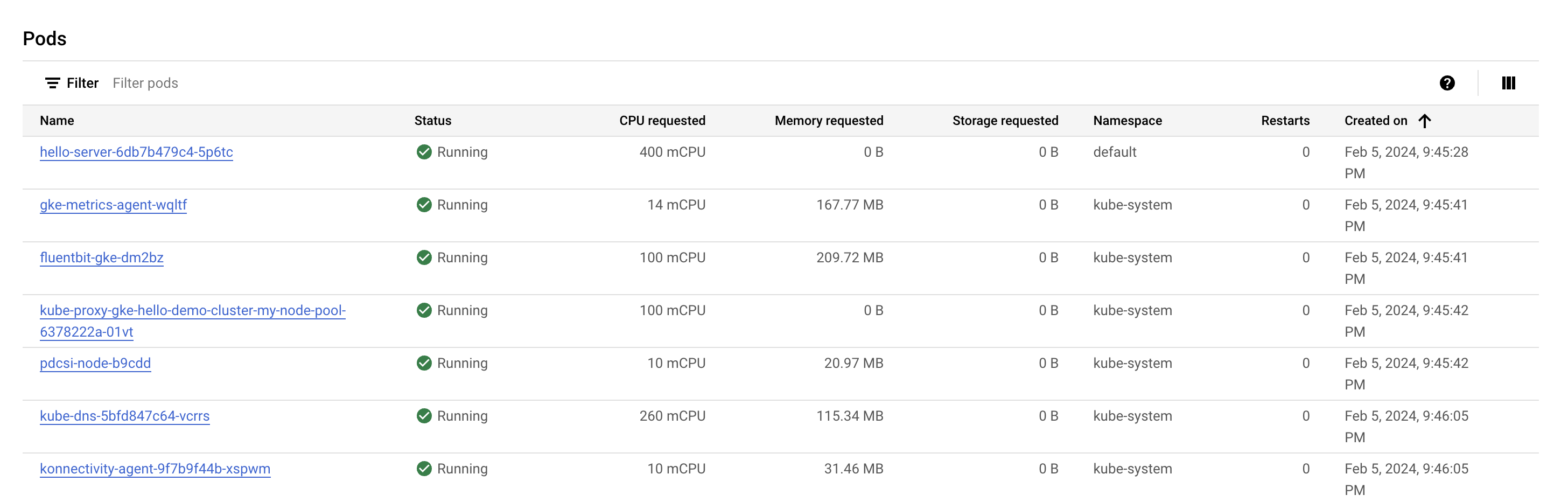
Confira a seção Pods. Seu pod hello-server deve aparecer no namespace default. Se você não vir um pod hello-server, volte e selecione o segundo nó do seu cluster.
Você vai notar que o pod hello-server está solicitando 400 mcpu. Também devem aparecer alguns outros pods kube-system em execução. Eles são carregados para ajudar a ativar os serviços de clusters do GKE, como monitoramento.
- Aperte o botão Voltar para retornar à página de Nós anterior.
Nesse ponto você vai notar que precisa de dois nós médios E2 para executar uma réplica do seu Hello-App junto com os serviços kube-system essenciais. Além disso, embora você esteja usando a maior parte dos recursos de CPU do cluster, isso corresponde a apenas cerca de 1/3 da memória alocável dele.
Se a carga de trabalho deste aplicativo fosse completamente estática, você poderia criar um tipo de máquina com uma forma ajustada personalizada que tivesse as quantidades exatas de CPU e de memória necessárias. Dessa forma, você pouparia custos na infraestrutura geral de clusters.
No entanto, muitas vezes os clusters do GKE executam várias cargas de trabalho e essas cargas geralmente precisam ser escalonadas verticalmente, para mais ou para menos.
O que aconteceria se o App Hello fosse escalonado verticalmente?
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Escalone verticalmente o app Hello
- Acesse as credenciais do seu cluster:
- Escalone verticalmente seu
Hello-Server:
Clique em Verificar meu progresso para conferir se você executou a tarefa.
- Depois de voltar para o console, selecione Cargas de trabalho no menu do Kubernetes Engine à esquerda.
O status de erro Não há disponibilidade mínima deve aparecer para seu hello-server.
- Clique na mensagem de erro para conferir os detalhes do status. Você vai ver que o motivo é
Insufficient cpu.
Isso já era esperado. Lembre-se de que o cluster não tinha quase mais nenhum recurso de CPU e você solicitou mais 400m com outra réplica do hello-server.
- Para lidar com a nova solicitação, aumente o pool de nós:
-
Quando for solicitado que você prossiga, pressione
yeenter. -
No console, atualize a página Cargas de trabalho até que o status da carga de trabalho do seu
hello-servermude para OK:

Examine seu cluster
Com a carga de trabalho escalonada verticalmente, volte para a guia de nós do seu cluster.
- Clique em hello-demo-cluster:

- Depois, clique na guia Nós.
O pool de nós maior é capaz de lidar com a carga de trabalho mais pesada, mas verifique como os recursos da sua infraestrutura estão sendo utilizados.

Embora o GKE use os recursos de um cluster da melhor forma possível, há espaço para otimização. É possível ver que um de seus nós está usando a maior parte da sua memória, mas dois dos seus nós têm uma quantidade considerável de memória não utilizada.
Nesse ponto, você começaria a notar um padrão semelhante se continuasse a escalonar verticalmente o app. O Kubernetes tentaria encontrar um nó para cada nova réplica da implantação hello-server, não conseguiria, e depois criaria um novo nó com aproximadamente 600 m de CPU.
Problemas de empacotamento
Problemas de empacotamento ocorrem quando você precisa encaixar itens de volumes/formas diversos em um número finito de “caixas” ou contêineres com formato regular. O desafio consiste em encaixar os itens no menor número de caixas, “empacotando-os” da maneira mais eficiente possível.
Esse desafio é semelhante ao enfrentado ao tentar otimizar os clusters do Kubernetes para os aplicativos que eles executam. Há diversos aplicativos, provavelmente com diferentes requisitos de recursos, como memória e CPU, que você precisa adaptar, da forma mais eficiente possível, aos recursos de infraestrutura que o Kubernetes gerenciar para você (onde provavelmente se concentra a maioria dos custos do cluster).
Seu cluster de demonstração do Hello não usa um empacotamento muito eficiente. Seria mais econômico configurar o Kubernetes para usar um tipo de máquina mais adequado para essa carga de trabalho.
Migre para o pool de nós otimizado
- Crie um novo pool de nós com um tipo de máquina maior:
Clique em Verificar meu progresso para conferir se você executou a tarefa.
Agora é possível migrar pods para o novo pool de nós, basta seguir estes passos:
-
Demarque o pool de nós existente: esta operação sinaliza os nós no pool de nós existente (
node) como não programáveis. O Kubernetes para de programar novos pods para esses nós quando você os sinaliza como não programáveis. -
Esvazie o pool de nós existente: esta operação remove as cargas de trabalho em execução nos nós do pool de nós existente (
node) sem interrupções.
- Primeiro, delimite o pool de nós original:
- Depois, esvazie o pool:
Neste ponto, você vai notar que seus pods estão em execução no novo pool de nós larger-pool:
- Depois de migrar os pods, é seguro excluir o antigo pool de nós:
- Quando for solicitado que você prossiga, pressione
yeenter.
A exclusão pode levar cerca de 2 minutos. Confira a seção a seguir enquanto espera.
Análise de custo
A mesma carga de trabalho que exigia três máquinas e2-medium agora está sendo executada em apenas uma máquina e2-standard-2.
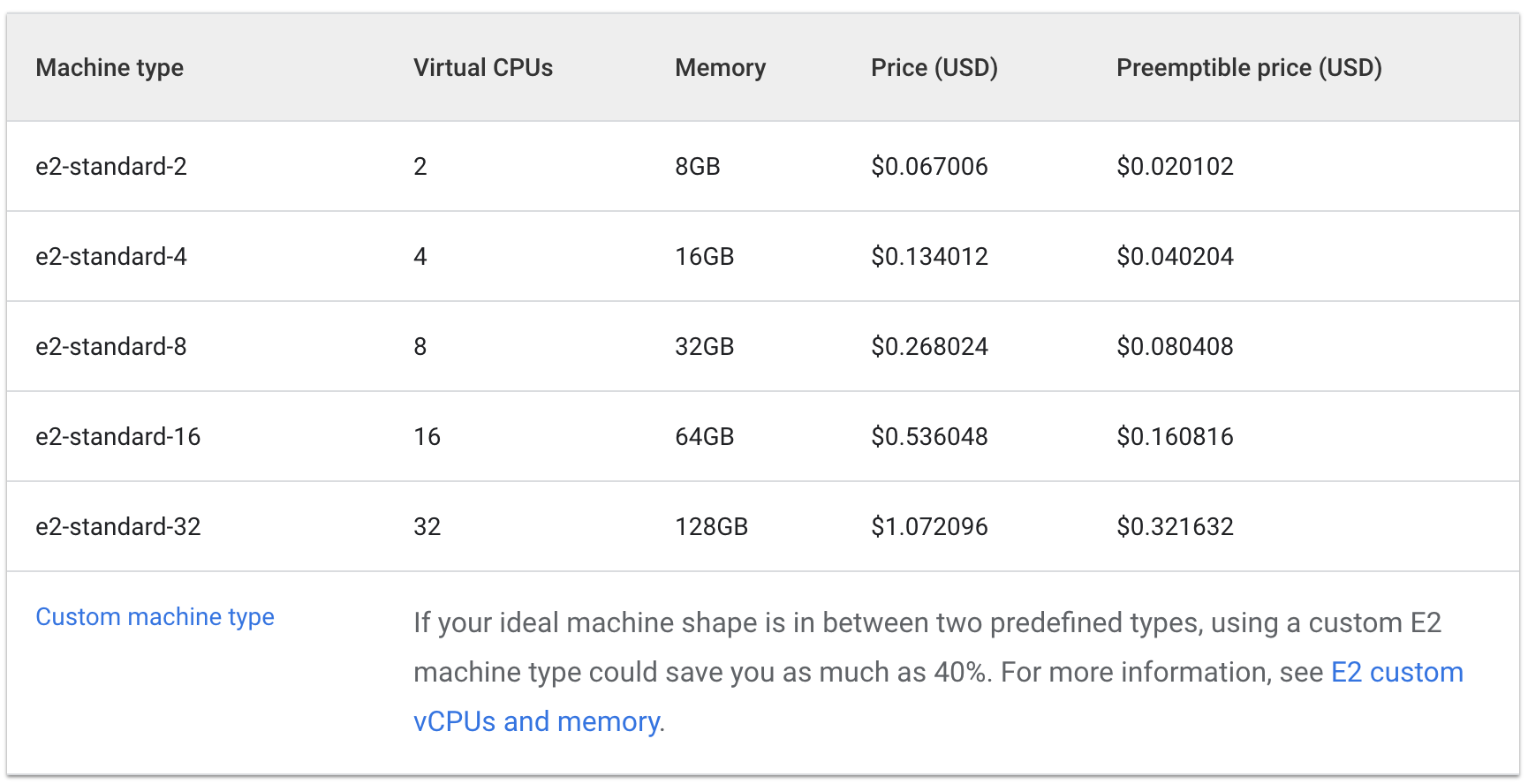
Confira o custo por hora para manter máquinas e2 standard e de núcleo compartilhado:
Standard:
Shared Core:
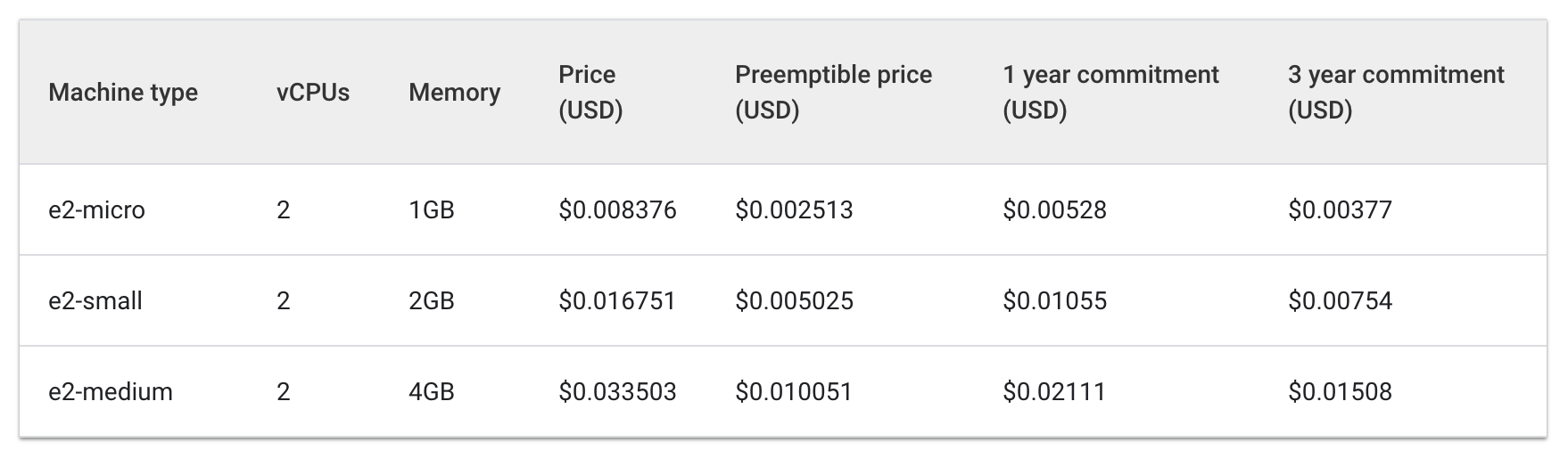
O custo de três máquinas e2-medium seria de aproximadamente US$ 0,10 por hora. Já uma e2-standard-2 custaria cerca de US$ 0,067 por hora.
Poupar US$ 0,04 por hora pode parecer pouco, mas esse custo pode aumentar ao longo da vida útil de um aplicativo em execução. Seria ainda mais perceptível em uma escala maior. Como a máquina e2-standard-2 pode empacotar sua carga de trabalho com mais eficiência e há menos espaço não utilizado, o custo de expansão aumentaria com menos celeridade.
Isso é interessante porque E2-medium é um tipo de máquina com núcleo compartilhado projetado para ser econômico para aplicativos pequenos que não consomem muitos recursos. Porém, para a carga de trabalho atual do Hello-App, você vê que usar um pool de nós com um tipo de máquina maior acaba sendo uma estratégia mais econômica.
No console do Cloud, você ainda deve estar na guia Nós do seu cluster hello-demo. Atualize a guia e examine os campos CPU Requested e CPU Allocatable para seu nó larger-pool.
Veja que é possível otimizar ainda mais. O novo nó pode caber em outra réplica da sua carga de trabalho sem o provisionamento de um outro nó. Ou você pode escolher um tipo de máquina de tamanho personalizado que atenda às necessidades de CPU e memória do aplicativo, economizando ainda mais recursos.
Não esqueça que esses preços variam dependendo da localização do seu cluster. A próxima parte deste laboratório aborda como escolher a melhor região e gerenciar um cluster regional.
Como escolher o local apropriado para um cluster
Aspectos gerais das regiões e zonas
Os recursos do Compute Engine, usados para os nós do seu cluster, são hospedados em lugares diferentes ao redor do mundo, que são compostos por regiões e zonas. As regiões são localizações geográficas específicas em que você pode hospedar recursos e que têm três ou mais zonas.
Os recursos que residem em uma zona, como instâncias de máquinas virtuais ou discos permanentes zonais, são chamados de recursos zonais. Outros recursos, como endereços IP externos estáticos, são regionais. Os recursos regionais podem ser usados por qualquer recurso nessa região, independentemente da zona, enquanto os recursos zonais só podem ser usados por outros recursos na mesma zona.
Ao escolher uma região ou zona, considere:
- Como lidar com falhas: se os recursos do seu app forem distribuídos apenas em uma zona e ela ficar indisponível, ele também vai ficar. Em apps de alta demanda e maior escala, uma prática geralmente recomendada para lidar com falhas é distribuir os recursos entre várias zonas ou regiões.
- Menos latência de rede: para diminuir a latência, escolha uma região ou zona próxima do seu ponto de serviço. Por exemplo, se você tiver mais clientes na Costa Leste dos EUA, convém escolher uma região e uma zona principais próximas a essa área.
Práticas recomendadas para clusters
Os custos variam entre as regiões com base em diversos fatores. Por exemplo, recursos da região us-west2 tendem a ser mais caros que os recursos da região us-central1.
Ao selecionar uma região ou zona para seu cluster, examine o que está acontecendo com seu app. Para um ambiente de produção sensível à latência, posicionar seu app em uma região/zona com latência de rede reduzida e maior eficiência provavelmente vai resultar em uma melhor relação de custo e desempenho.
No entanto, se quiser reduzir custos, um ambiente de desenvolvimento não sensível à latência pode ser posicionado em uma região mais barata.
Como lidar com a disponibilidade de clusters
Os tipos de clusters disponíveis no GKE incluem zonal (zona única ou multizonal) e regional. Pelo valor em si, um cluster de zona única é a opção menos dispendiosa. No entanto, para que seus aplicativos tenham uma alta disponibilidade, é melhor distribuir os recursos de infraestrutura do cluster entre as zonas.
Em muitos casos, priorizar a disponibilidade no seu cluster com um cluster multizonal ou regional resulta em uma arquitetura de custo-desempenho melhor.
Tarefa 3: como gerenciar um cluster regional
Configuração
Gerenciar os recursos do cluster entre várias zonas é algo um pouco mais complexo. Se não tomar cuidado, pode ocorrer um acúmulo de custos extras de comunicação interzonal desnecessária entre seus pods.
Nesta seção, você vai ver o tráfego de rede do seu cluster e mover dois pods que estão gerando muito tráfego entre si para que fiquem na mesma zona.
- Crie um novo cluster regional na guia Cloud Shell. Este comando leva uns minutos para ser concluído:
Para demonstrar o tráfego entre seus pods e nós, você vai criar dois pods em nós separados no seu cluster regional. Vamos usar ping para gerar tráfego de um pod para o outro e monitorar.
- Execute o comando abaixo e crie um manifesto para seu primeiro pod:
- Crie o primeiro pod no Kubernetes usando este comando:
- Depois, execute o comando a seguir e crie um manifesto para seu segundo pod:
- Crie o segundo pod no Kubernetes:
Clique em Verificar meu progresso para conferir se você executou a tarefa.
Os pods que você criou usam o contêiner node-hello e emitem uma mensagem Hello Kubernetes quando solicitados.
Se você voltar para o arquivo pod-2.yaml, vai perceber que a Antiafinidade de pods é uma regra definida. Isso possibilita que você garanta que o pod não está programado no mesmo nó que o pod-1. Isso é feito fazendo a correspondência de uma expressão baseada no rótulo security: demo do pod-1. A Afinidade de pods é usada para garantir que os pods sejam programados no mesmo nó. Já a Antiafinidade de pods é usada para garantir que os pods não sejam programados no mesmo nó.
Nesse caso, a Antiafinidade de pods é usada para ajudar a ilustrar o tráfego entre os nós, mas o uso inteligente da Antiafinidade de pods e da Afinidade de pods pode melhorar ainda mais o uso dos recursos do seu cluster regional.
- Confira os pods que você criou:
Você vai notar que os dois pods retornaram com um status Running e IPs internos.
Exemplo de saída:
Anote o endereço IP do pod-2. Ele será usado no comando a seguir.
Simule o tráfego
- Abra um shell para o contêiner do seu
pod-1:
- No shell, envie uma solicitação para o
pod-2, substituindo [POD-2-IP] pelo IP interno mostrado para opod-2:
Anote a latência média ao dar ping no pod-2 a partir do pod-1.
Examine os registros de fluxo
Com o pod-1 dando pings no pod-2, é possível habilitar registros de fluxo na sub-rede da VPC em que o cluster foi criado para verificar o tráfego.
- No console do Cloud, abra o menu de navegação e selecione Rede VPC na seção Rede.
- Localize a sub-rede
defaultna regiãoe clique nela.
-
Clique em Editar no topo da tela.
-
Selecione Ativado em Registros de fluxo.
-
Depois clique em Salvar.
-
Em seguida, clique em Ver registros de fluxo.
Uma lista de registros com uma grande quantidade de informações vai aparecer sempre que algo for enviado ou recebido por uma das suas instâncias.
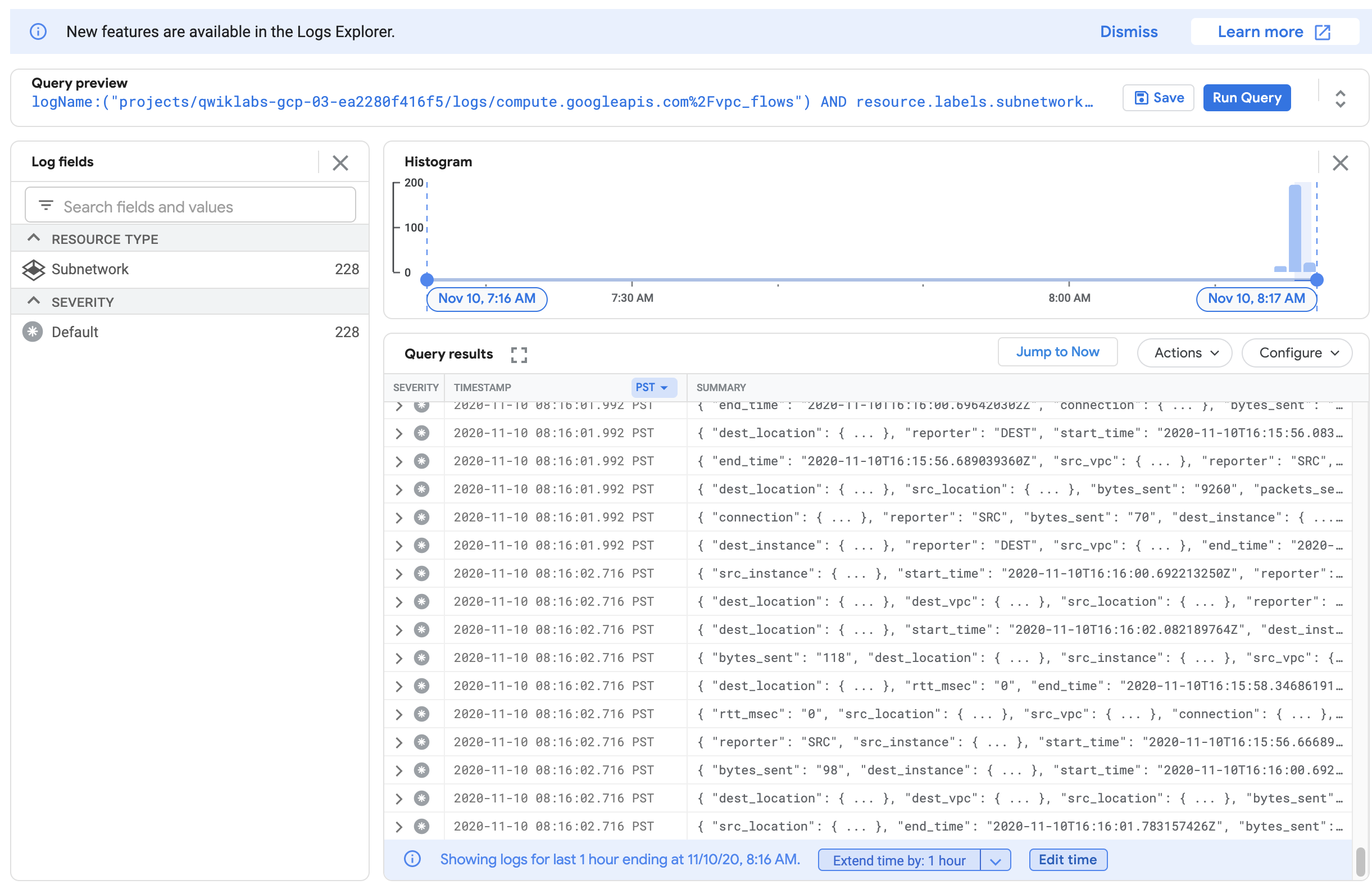
Se os registros não forem gerados, substitua / antes de vpc_flows por %2F, como mostrado na captura de tela acima.
A leitura pode ser um pouco difícil. Depois, faça a exportação para uma tabela do BigQuery para que possa consultar as informações relevantes.
- Clique em Mais ações > Criar coletor.
-
Dê ao coletor o nome
FlowLogsSample. -
Clique em Próxima.
Destino do coletor
- Em Serviço de coletor, selecione o conjunto de dados do BigQuery.
- Para o conjunto de dados do BigQuery, selecioneCriar novo conjunto de dados do BigQuery.
- Dê ao seu conjunto de dados o nome 'us_flow_logs' e clique em CRIAR CONJUNTO DE DADOS.
Todo o resto pode ser deixado como está.
-
Clique em Criar coletor.
-
Inspecione o conjunto de dados recém-criado. No console do Cloud, a partir do Menu de navegação na seção Análise, clique em BigQuery.
-
Clique em Concluído.
-
Para conferir a nova tabela, selecione o nome do seu projeto e depois us_flow_logs. Se nenhuma tabela aparecer, talvez você precise atualizar a página até que ela seja criada.
-
Clique na tabela
compute_googleapis_com_vpc_flows_xxxno seu conjunto de dadosus_flow_logs.
-
Clique em Consulta > Em uma nova guia.
-
No Editor do BigQuery, cole o seguinte entre
SELECTeFROM:
- Clique em Executar.
Você vai notar que os registros de fluxo são os mesmos de antes, mas filtrados por source zone, source vm, destination zone e destination vm.
Localize algumas linhas onde chamadas sejam feitas entre duas zonas diferentes no seu cluster regional-demo.

Monitorando os registros de fluxo, é possível notar que há tráfego frequente entre zonas diferentes.
Em seguida, mova os pods para uma mesma zona e verifique os benefícios.
Mova um pod de alto tráfego para minimizar os custos de tráfego entre zonas
-
Ao voltar para o Cloud Shell, pressione Ctrl + C para cancelar o comando
ping. -
Insira o comando
exitpara sair do shell dopod-1:
- Execute este comando para editar o manifesto do
pod-2:
Isso vai mudar sua regra Pod Anti Affinity para uma regra de Pod Affinity, usando a mesma lógica. Agora o pod-2 vai ser programado no mesmo nó que o pod-1.
- Exclua o
pod-2em execução:
- Depois que o
pod-2é excluído, ele pode ser recriado com o manifesto recém-editado:
Clique em Verificar meu progresso para conferir se você executou a tarefa.
- Confira os pods criados e verifique se ambos estão no estado
Running:
A partir da resposta, é possível notar que o Pod-1 e o Pod-2 estão em execução no mesmo nó.
Anote o endereço IP do pod-2. Ele é usado nas etapas a seguir.
- Abra um shell para o contêiner do seu
pod-1:
- No seu shell, envie uma solicitação para o
pod-2, substituindo [POD-2-IP] pelo IP interno dopod-2extraído do comando anterior:
Note que o tempo médio dos pings entre esses pods ficou muito menor.
Nesse ponto, é possível retornar ao conjunto de dados do BigQuery dos registros de fluxo e verificar os mais recentes para conferir se não há outras comunicações interzonais indesejadas.
Análise de custo
Confira os Preços de saída VM-VM no Google Cloud:
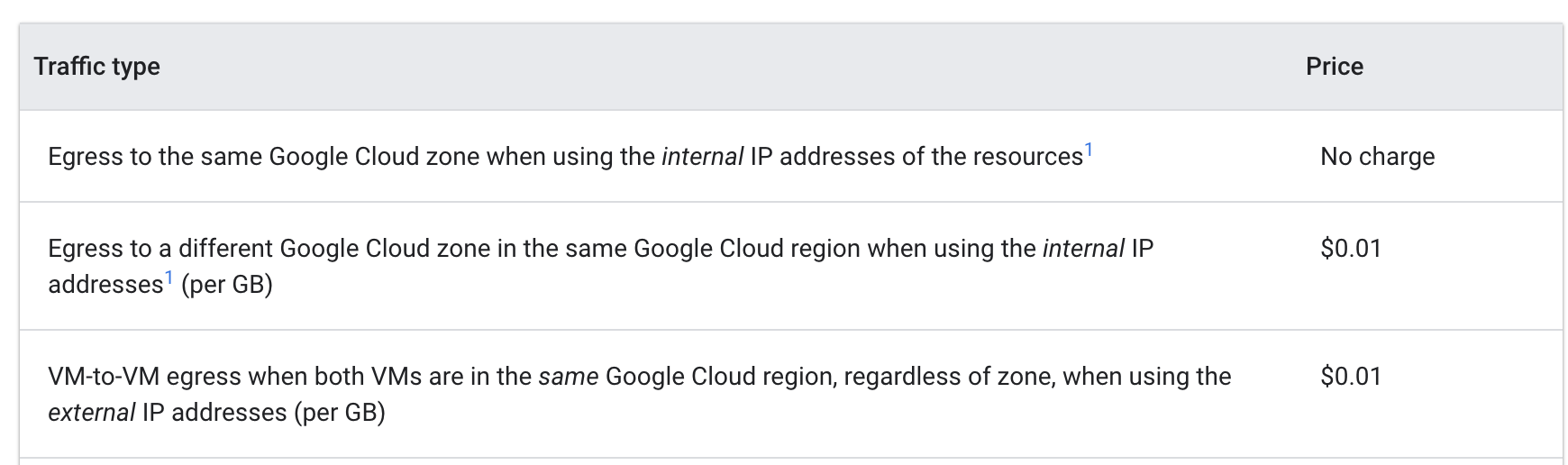
Quando os pods davam pings entre si de zonas diferentes, cada GB custava US$ 0,01. Embora esse valor soe baixo, ele pode aumentar muito rapidamente em um cluster de grande escala, com vários serviços fazendo chamadas frequentes entre as zonas.
Ao mover os pods para a mesma zona, os pings se tornaram livres de custos financeiros.
Parabéns!
Você explorou a otimização de custos para máquinas virtuais que fazem parte de um cluster do GKE. Primeiro, migrando uma carga de trabalho para um pool de nós com um tipo de máquina mais adequado. Depois, ponderando sobre os prós e contras de diferentes regiões. E, por fim, movendo um pod de tráfego intenso dentro de um cluster regional para que ele sempre fique na mesma zona que o pod com que estava se comunicando.
Este laboratório mostrou ferramentas e estratégias econômicas para VMs do GKE, mas para otimizar suas máquinas virtuais você precisa entender seu aplicativo e as necessidades dele. Saber os tipos de cargas de trabalho que você vai executar e estimar as demandas do seu aplicativo quase sempre influencia na decisão sobre qual local e tipo de máquina é mais eficaz para as máquinas virtuais usadas no seu cluster do GKE.
Usar a infraestrutura do seu cluster de forma eficiente ajuda muito a otimizar os custos.
Termine a Quest
Este laboratório autoguiado faz parte da Quest Optimize Costs for Google Kubernetes Engine. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. Torne seus selos públicos incluindo um link para eles no seu currículo on-line ou nas redes sociais.
Inscreva-se nesta Quest e receba o crédito de conclusão imediatamente.
Consulte todas as Quests disponíveis no catálogo do Google Cloud Ensina.
Comece o próximo laboratório
Continue a Quest em Optimize Costs for Google Kubernetes Engine ou confira estas sugestões:
- Como gerenciar um cluster multilocatário do GKE com namespaces
- Otimização de cargas de trabalho do GKE
Próximas etapas / saiba mais
- Documentação sobre tipos de máquinas
- Práticas recomendadas para executar aplicativos econômicos do Kubernetes no GKE: como escolher o tipo de máquina certo
- Práticas recomendadas para executar aplicativos econômicos do Kubernetes no GKE: como selecionar a região apropriada
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 20 de setembro de 2023
Laboratório testado em 20 de setembro de 2023 ![[/fragments/copyright]]