Checkpoints
Provision Lab Environment
/ 20
Container-native Load Balancing Through Ingress
/ 20
Load Testing an Application
/ 20
Readiness and Liveness Probes
/ 20
Create Pod Disruption Budgets
/ 20
Otimização da carga de trabalho do GKE
GSP769

Visão geral
Um dos muitos benefícios de usar o Google Cloud é o modelo de faturamento que cobra somente os recursos que você usa. Com isso em mente, é essencial alocar uma quantidade razoável de recursos para seus apps e infraestrutura, além de fazer o uso mais eficiente deles. Com o GKE, há várias ferramentas e estratégias disponíveis que podem reduzir o uso de recursos e serviços ao mesmo tempo que melhoram a disponibilidade do seu aplicativo.
Neste laboratório, abordaremos alguns conceitos que ajudarão a aumentar a eficiência e a disponibilidade de recursos das suas cargas de trabalho. Entenda e ajuste a carga de trabalho do cluster para garantir que você use apenas os recursos necessários, otimizando os custos do cluster.
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Provisione o ambiente do laboratório
- Defina a zona padrão como "
":
-
Clique em Autorizar.
-
Crie um cluster de três nós:
A flag --enable-ip-alias está incluída para permitir o uso de IPs de alias para pods que vão ser necessários para o balanceamento de carga nativo de contêiner por uma entrada.
Neste laboratório, você vai usar um app da Web HTTP simples para implantar inicialmente como um único pod.
- Crie um manifesto para o pod
gb-frontend:
- Aplique o manifesto criado ao cluster:
Clique em Verificar meu progresso para conferir o objetivo.
Tarefa 1: balanceamento de carga nativo de contêiner pela entrada
O balanceamento de carga nativo de contêiner permite que os balanceadores de carga segmentem os pods do Kubernetes diretamente e distribuam o tráfego por igual entre eles.
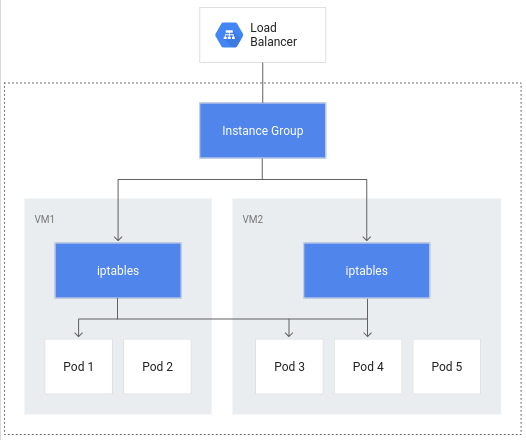
Sem o balanceamento de carga nativo de contêiner, o tráfego do balanceador de carga passaria para grupos de instâncias de nó e seria roteado por meio de regras iptables para pods, que podem ou não estar no mesmo nó:
Com o balanceamento de carga nativo de contêiner, os pods se tornam os objetos principais do balanceamento, reduzindo o número de saltos de rede:
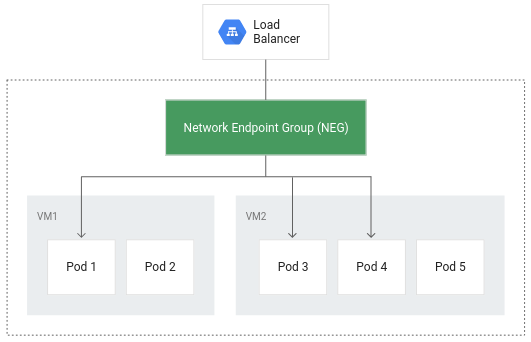
Além do roteamento mais eficiente, o balanceamento de carga nativo de contêiner resulta em uma redução considerável da utilização de rede, melhoria do desempenho, distribuição do tráfego entre os pods e verificações de integridade no nível do aplicativo.
Para aproveitar o balanceamento de carga nativo de contêiner, a configuração nativa de VPC precisa estar ativada no cluster. Isso foi indicado quando você criou o cluster e incluiu a sinalização --enable-ip-alias.
- O manifesto a seguir vai configurar um serviço
ClusterIPque será usado no roteamento do tráfego para o pod de aplicativo, permitindo que o GKE crie um grupo de endpoints de rede:
O manifesto inclui um campo annotations em que a anotação de cloud.google.com/neg vai ativar o balanceamento de carga nativo de contêiner no aplicativo quando uma entrada for criada.
- Aplique a mudança no cluster:
- Em seguida, crie uma entrada para o aplicativo:
- Aplique a mudança no cluster:
Quando a entrada é criada, um balanceador de carga HTTP(S) é criado com um grupo de endpoints de rede (NEG, na sigla em inglês) em cada zona em que o cluster é executado. Após alguns minutos, um IP externo será atribuído à entrada.
O balanceador de carga criado tem um serviço de back-end em execução no projeto que define como o Cloud Load Balancing distribui o tráfego. Esse serviço de back-end está associado a um status de integridade.
- Para verificar o status da integridade do serviço de back-end, primeiro recupere o nome:
- Confira o status de integridade do serviço:
Vai levar uns minutos até que sua verificação de integridade retorne um resultado positivo.
A saída vai ser algo semelhante a esta:
Depois que o estado de integridade de cada instância for relatado como ÍNTEGRA, será possível acessar o aplicativo por meio do IP externo.
- Recupere com:
- Digitar o IP externo em uma janela do navegador vai carregar o aplicativo.
Clique em Verificar meu progresso para conferir o objetivo.
Tarefa 2: teste de carga de um aplicativo
Entender a capacidade do seu aplicativo é importante para escolher solicitações e limites de recursos para os pods do aplicativo e decidir a melhor estratégia de escalonamento automático.
No início do laboratório, você implantou seu aplicativo como um pod único. Ao testar o aplicativo em execução em um pod único sem o escalonamento automático configurado, você vai saber quantas solicitações simultâneas ele pode processar, a quantidade de CPU e memória necessárias e como ele responde sob carga pesada.
Para testar o carregamento do pod, você vai usar o Locust, um framework de teste de carga de código aberto.
- Faça o download dos arquivos de imagem do Docker para o Locust no Cloud Shell:
Os arquivos no diretório locust-image informado incluem arquivos de configuração do Locust.
- Crie a imagem do Docker para o Locust e armazene-a no Container Registry do seu projeto:
- Verifique se a imagem do Docker está no Container Registry do seu projeto:
Saída esperada:

O Locust consiste em uma máquina principal e diversas máquinas de worker para gerar carga.
- Copiar e aplicar o manifesto vai criar uma implantação de pod único para a máquina principal e uma implantação de cinco réplicas para as de worker:
- Para acessar a IU do Locust, recupere o endereço IP externo do serviço LoadBalancer correspondente:
Se o valor do IP externo for <pending>, aguarde um minuto e execute o comando anterior de novo até que um valor válido seja exibido.
- Em uma outra janela do navegador, acesse
[EXTERNAL_IP_ADDRESS]:8089para abrir a página do Locust na Web:
Clique em Verificar meu progresso para conferir o objetivo.
O Locust permite que você faça swarm do seu aplicativo com muitos usuários simultâneos. É possível simular um tráfego ao inserir vários usuários gerados a uma determinada taxa.
-
Neste exemplo, para representar uma carga típica, digite 200 como o número de usuários a serem simulados e 20 como a taxa de geração.
-
Clique em Start swarming.
Após alguns segundos, o status será Running, com 200 usuários e cerca de 150 solicitações por segundo (RPS).
-
Passe para o console do Cloud e clique em Menu de navegação (
) > Kubernetes Engine.
-
Selecione Cargas de trabalho no painel à esquerda.
-
Depois clique no pod gb-frontend implantado.
A página de detalhes do pod vai aparecer. Nela, é possível conferir um gráfico da utilização da CPU e da memória do seu pod. Observe os valores usados e solicitados.
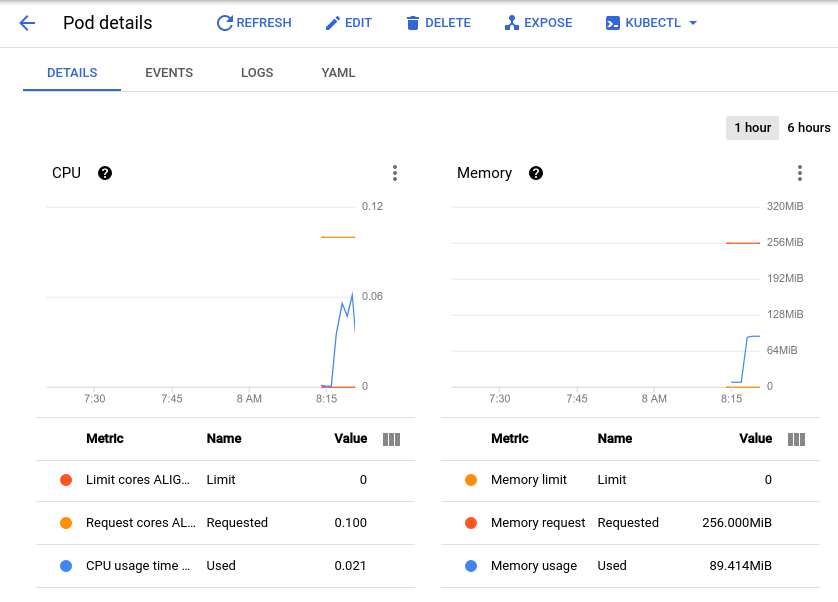
Com o teste de carga atual, que é de cerca de 150 solicitações por segundo, o uso da CPU pode variar de 0,04 a 0,06. Isso representa 40 a 60% da solicitação de CPU de um pod. Por outro lado, a utilização da memória permanece em cerca de 80 Mi, bem abaixo dos 256 Mi solicitados. Essa é sua capacidade por pod. Essas informações serão úteis ao configurar o escalonador automático de cluster, as solicitações e os limites de recursos e escolher se e como implementar um escalonador automático de pods horizontal ou vertical.
Além de um valor de referência, considere o desempenho do aplicativo após bursts ou picos repentinos.
-
Retorne à janela do navegador do Locust e clique em Edit sob o status no topo da página.
-
Desta vez, digite 900 para o número de usuários a simular e 300 para a taxa de geração.
-
Clique em Start swarming.
Seu pod vai receber 700 solicitações adicionais repentinamente dentro de 2 a 3 segundos. Quando o valor do RPS atingir cerca de 150 e o status indicar 900 usuários, mude de volta para a página de detalhes do pod e observe a mudança nos gráficos.
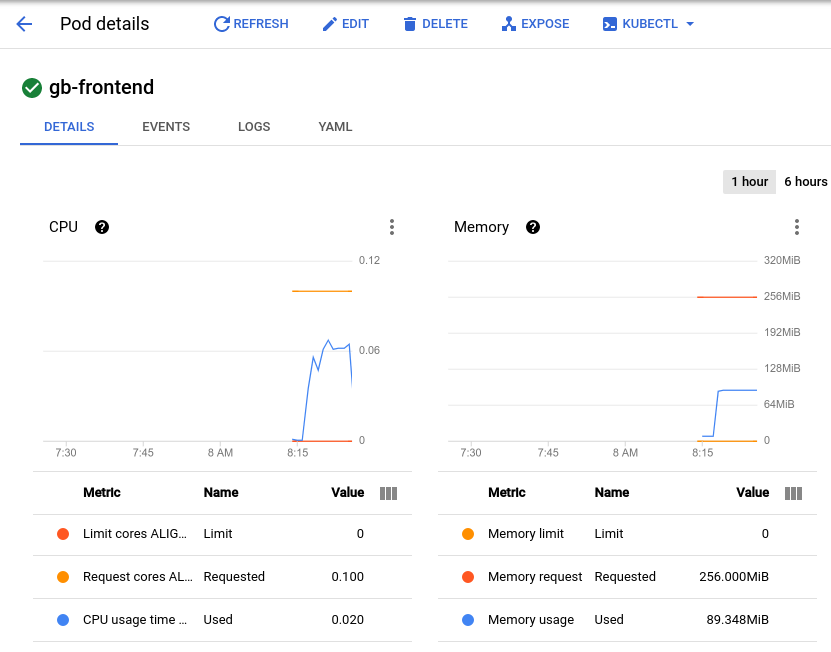
Embora a memória permaneça igual, você vai notar que a CPU atingiu o pico em quase 0,07, ou seja, 70% da solicitação de CPU para o pod. Se o app fosse uma implantação, você poderia reduzir com segurança a solicitação de memória total e configurar o acionamento do escalonador automático horizontal de acordo com a utilização da CPU.
Tarefa 3: sondagens de prontidão e atividade
Como configurar uma sondagem de atividade
Se for configurada na especificação de pod ou na implantação do Kubernetes, uma sondagem de atividade será executada continuamente para detectar se um contêiner precisa de reinicialização e, se for o caso, acioná-la. Elas são úteis para reiniciar automaticamente aplicativos que foram bloqueados e ainda podem estar em execução. Por exemplo, um balanceador de carga gerenciado pelo Kubernetes (como um serviço) só enviaria tráfego para um back-end de pods se todos os contêineres passassem por uma sondagem de prontidão.
- Para demonstrar uma sondagem de atividade, o código abaixo vai gerar um manifesto para um pod que tenha uma sondagem com base na execução do comando cat em um arquivo criado durante a criação:
- Aplique o manifesto ao cluster para criar o pod:
O valor initialDelaySeconds representa o tempo de realização da primeira sondagem depois que o contêiner é iniciado. O valor periodSeconds indica a frequência de realização da sondagem.
startupProbe, que indica se o aplicativo no contêiner foi iniciado. Se um startupProbe estiver presente, nenhuma outra sondagem vai ser executada até retornar um estado Success. Isso é recomendável para aplicativos que podem ter tempos de inicialização variáveis, a fim de evitar interrupções de uma sondagem de atividade.Nesse exemplo, a sondagem de atividade está verificando se o arquivo /tmp/alive existe no sistema de arquivos do contêiner.
- É possível verificar a integridade do contêiner do pod analisando os eventos dele:
Na parte inferior da saída, há uma seção "Eventos" com os últimos cinco eventos do pod. Neste momento, os eventos do pod só podem incluir eventos relacionados à criação e inicialização:
Esse log de eventos vai incluir todas as falhas na sondagem de atividade, bem como as reinicializações acionadas como resultado.
- Faça a exclusão manual do arquivo usado pela sondagem de atividade:
-
Com o arquivo removido, o comando
catusado pela sondagem de atividade deve retornar um código de saída diferente de zero. -
Verifique os eventos do pod mais uma vez:
Quando a sondagem de atividade falhar, eventos serão adicionados ao registro, mostrando a série de etapas iniciadas. Ele vai começar com a falha da sondagem de atividade (Liveness probe failed: cat: /tmp/alive: No such file or directory) e terminar com a reinicialização do contêiner (Started container):
livenessProbe que depende do código de saída de um comando especificado. Além de uma sondagem de comando, um livenessProbe pode ser configurado como uma sondagem HTTP que vai depender da resposta HTTP ou uma sondagem TCP que vai depender de uma conexão TCP poder ser feita em uma porta específica. Como configurar uma sondagem de prontidão
Um pod pode ser iniciado e considerado íntegro por uma sondagem de atividade, mas é provável que ele não esteja pronto para receber tráfego imediatamente. Isso é comum para implantações que servem como back-end para um serviço como um balanceador de carga. Uma sondagem de atividade é usada para determinar quando um pod e os contêineres dele estão prontos para receber tráfego.
- Para demonstrar isso, faça um manifesto para criar um pod único que vai operar como um servidor de teste da Web com um balanceador de carga:
- Aplique o manifesto ao cluster e crie um balanceador de carga com ele:
- Recupere o endereço IP externo atribuído ao balanceador de carga. Pode levar um minuto após o comando anterior para um endereço ser atribuído:
-
Digite o endereço IP em uma janela do navegador. Você vai notar uma mensagem de erro indicando que o site não pode ser acessado.
-
Verifique os eventos do pod:
A saída vai mostrar que a sondagem de prontidão falhou:
Ao contrário da sondagem de atividade, uma sondagem de prontidão que não é íntegra não faz com que o pod seja reinicializado.
- Use o comando a seguir para gerar o arquivo que a sondagem de prontidão está verificando:
Agora a seção Conditions da descrição do pod deve mostrar True como o valor de Ready.
Saída:
- Atualize a guia do navegador que tinha o IP externo de readiness-demo-svc. Você verá a mensagem Welcome to nginx! exibida corretamente.
Definir sondagens de prontidão significativas para seus contêineres de aplicativos garante que os pods só recebam o tráfego quando estiverem prontos. Um exemplo de uma sondagem de prontidão significativa é verificar se um cache do seu aplicativo é carregado na inicialização.
Clique em Verificar meu progresso para conferir o objetivo.
Tarefa 4: orçamentos de interrupção do pod
Para garantir a confiabilidade e o tempo de atividade para seu aplicativo do GKE, é necessário aproveitar os orçamentos de interrupção do pod (PDB, na sigla em inglês). O PodDisruptionBudget é um recurso do Kubernetes que limita o número de pods de um aplicativo replicado que podem ser desativados de maneira simultânea devido a interrupções voluntárias.
As interrupções voluntárias incluem ações administrativas, como excluir uma implantação, atualizar o modelo de pod de uma implantação e executar uma atualização gradual, drenar nós em que os pods de um aplicativo residem ou mover pods para nós diferentes.
Primeiro, implante o aplicativo como uma implantação.
- Exclua o app de pod único:
- E gere um manifesto que vai criá-lo como uma implantação de cinco réplicas:
- Aplique esta implantação ao cluster:
Clique em Verificar meu progresso para conferir o objetivo.
Antes de criar um PDB, você deve drenar os nós do cluster e observar o comportamento do aplicativo sem um PDB.
- Drene os nós percorrendo a saída dos nós do
default-poole executando o comandokubectl drainem cada um deles:
O comando acima vai remover pods do nó especificado e delimitar o nó para que nenhum pod novo seja criado nele. Se os recursos disponíveis permitirem, os pods serão reimplantados em um nó diferente.
- Depois que o nó for drenado, verifique a contagem de réplicas da implantação
gb-frontend:
A saída vai ser algo semelhante a:
Depois de drenar um nó, sua implantação pode ter até 0 réplicas disponíveis, como indicado pela saída acima. Sem os pods disponíveis, seu aplicativo está desativado. Tente drenar os nós novamente, mas dessa vez com um orçamento de interrupção de pod em vigor para seu aplicativo.
- Primeiro desmarque os nós drenados para recolocá-los. Com o comando abaixo, é possível programar pods em um nó novamente:
- Verifique mais uma vez o status da sua implantação:
A resposta será como esta, com todas as cinco réplicas disponíveis:
- Crie um orçamento de interrupção de pod que vai declarar o número mínimo de pods disponíveis como quatro:
- Drene um dos nós do cluster mais uma vez e observe a saída:
Depois de remover um dos pods do aplicativo, ele vai retornar o seguinte:
-
Pressione CTRL+C para sair do comando.
-
Verifique o status das suas implantações outra vez:
A resposta será:
Até que o Kubernetes consiga implantar um quinto pod em um nó diferente para remover o próximo, os pods restantes vão continuar disponíveis para aderir ao PDB. Neste exemplo, o orçamento de interrupção do pod foi configurado para indicar min-available, mas um PDB também pode ser configurado para definir um max-unavailable. Qualquer um dos valores pode ser expresso como um inteiro que representa uma contagem de pods ou uma porcentagem do total.
Parabéns!
Você aprendeu a criar um balanceador de carga nativo de contêiner pela entrada para aproveitar um balanceamento de carga e um roteamento mais eficientes. Você realizou um teste de carga simples em um aplicativo do GKE e pôde conferir o uso básico de CPU e memória, bem como a resposta do aplicativo a picos de tráfego. Além disso, configurou sondagens de atividade e de prontidão com um orçamento de interrupção de pod para garantir a disponibilidade dos seus aplicativos. Em conjunto, essas ferramentas e técnicas contribuem para a eficiência geral do funcionamento do seu aplicativo no GKE, minimizando o tráfego externo à rede, definindo indicadores significativos de um aplicativo com comportamento adequado e melhorando a disponibilidade do aplicativo.
Próximas etapas/Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 13 de dezembro de 2023
Laboratório testado em 13 de dezembro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.