检查点
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
使用 Natural Language API 進行實體和情緒分析
GSP038

總覽
Cloud Natural Language API 可讓您從文字中擷取實體、執行情緒和語法分析,並將文字分類。
在這個研究室中,您會瞭解如何運用 Natural Language API 分析實體、情緒和語法。
課程內容
- 建立 Natural Language API 要求並使用 curl 呼叫 API
- 使用 Natural Language API 擷取實體並對文字執行情緒分析
- 透過 Natural Language API 對文字執行語言分析
- 建立不同語言的 Natural Language API 要求
設定和需求
點選「Start Lab」按鈕前的須知事項
請詳閱以下操作說明。研究室活動會計時,而且中途無法暫停。點選「Start Lab」 後就會開始計時,讓您瞭解有多少時間可以使用 Google Cloud 資源。
您將在真正的雲端環境中完成實作研究室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
- 您可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
- 是時候完成研究室活動了!別忘了,活動一開始將無法暫停。
如何開始研究室及登入 Google Cloud 控制台
-
按一下「Start Lab」(開始研究室) 按鈕。如果研究室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。左側的「Lab Details」(研究室詳細資料) 面板會顯示下列項目:
- 「Open Google Console」(開啟 Google 控制台) 按鈕
- 剩餘時間
- 必須在這個研究室中使用的暫時憑證
- 完成這個研究室所需的其他資訊 (如有)
-
按一下「Open Google Console」(開啟 Google 控制台)。接著,研究室會啟動相關資源並開啟另一個分頁,當中會顯示「Sign in」(登入) 頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意事項:如果頁面中顯示了「Choose an account」(選擇帳戶) 對話方塊,請按一下「Use Another Account」(使用其他帳戶)。 -
如有必要,請複製「Lab Details」(研究室詳細資料) 面板中的使用者名稱,然後貼到「Sign in」(登入) 對話方塊。按一下「Next」(下一步)。
-
複製「Lab Details」(研究室詳細資料) 面板中的密碼,然後貼到「Welcome」(歡迎使用) 對話方塊。按一下「Next」(下一步)。
重要注意事項:請務必使用左側面板中的憑證,而非 Google Cloud 技能重點加強的憑證。 注意事項:如果使用自己的 Google Cloud 帳戶來進行這個研究室,可能會產生額外費用。 -
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Cloud 控制台稍後會在這個分頁中開啟。

工作 1:建立 API 金鑰
因為您使用 curl 傳送要求至 Natural Language API,您必須產生 API 金鑰以傳送要求網址。
-
如要建立 API 金鑰,請依序選取 Cloud 控制台中的「導覽選單」圖示 >「API 和服務」>「憑證」。
-
按一下「建立憑證」並選取「API 金鑰」。
-
複製系統產生的 API 金鑰,然後按一下「關閉」。
點選「Check my progress」,確認工作已完成。
為執行下一個步驟,請透過 SSH 連線至為您佈建的執行個體。
-
依序點選「導覽選單」圖示 >「Compute Engine」。VM 執行個體清單中會顯示佈建的 Linux 執行個體
linux-instance。 -
按一下「SSH」按鈕,系統會將您帶往互動式殼層。
-
請在指令列中輸入下列指令,並將
<YOUR_API_KEY>替換成剛剛複製的金鑰。
工作 2:建立實體分析要求
您使用的第一個 Natural Language API 方法是 analyzeEntities。透過這個方法,API 能夠從文字中擷取實體,例如人物、地點和事件。請使用以下語句嘗試執行 API 實體分析:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
在 request.json 檔案中建立要傳送至 Natural Language API 的要求。
- 使用 nano (程式碼編輯器) 建立
request.json檔案:
- 在
request.json中輸入或貼上下列程式碼:
- 按下 CTRL+X 退出 nano 編輯器,再按下 Y 鍵儲存檔案,然後按下 ENTER 鍵來確認操作。
透過要求,您傳送文字資訊至 Natural Language API,支援的類型值為 PLAIN_TEXT 或 HTML。您要在 content 中將文字傳送至 Natural Language API 進行分析。
您也能將儲存在 Cloud Storage 的文字檔案傳送至 Natural Language API 進行處理。如果想傳送 Cloud Storage 中的檔案,請將 content 替換為 gcsContentUri,並將值設為文字檔案在 Cloud Storage 中的 URI。
encodingType 會指示 API 在處理文字時該使用哪種類型的文字編碼。API 會使用該文字編碼計算特定實體在文字中出現的位置。
點選「Check my progress」,確認工作已完成。
工作 3:呼叫 Natural Language API
- 您現在可以使用下列
curl指令,傳送要求主體及稍早儲存的 API 金鑰環境變數至 Natural Language API (請在單一指令列中輸入所有指令):
- 請執行以下指令來查看回應:
回應開頭應如以下所示:
回應中的每個實體都包含實體 type (類型)、相關聯的 Wikipedia 網址 (如有)、salience (顯著性),以及實體在文字內容中出現位置的索引。顯著性是 [0、1] 範圍內的數字,表示實體在整個文字內容中的重要性。
Natural Language API 也能辨識以不同方式提及的同一實體。請查看回應中的 mentions 清單:API 能夠說明「Joanne Rowling」、「Rowling」、「novelist」及「Robert Galbriath」指的都是同一實體。
點選「Check my progress」,確認工作已完成。
工作 4:使用 Natural Language API 進行情緒分析
除了擷取實體外,Natural Language API 也可以讓您對一段文字執行情緒分析。此 JSON 要求必須包含與上方要求相同的參數,但這次請將這段文字改為情緒更強烈的內容。
- 使用 nano 編輯器將
request.json中的程式碼替換為下列程式碼,您也可以將下方的content替換為自己的文字內容。
-
按下 CTRL+X 退出 nano 編輯器,再按下 Y 鍵儲存檔案,然後按下 ENTER 鍵來確認操作。
-
接著將要求傳送至 API 的
analyzeSentiment端點:
回應內容應如下所示:
請注意,您會得到兩種情緒值:整份文件的情緒,以及按語句細分的情緒。此 sentiment 方法會傳回兩個值:
-
score(分數):範圍介於 -1.0 與 1.0 之間的數字,表示這段陳述的情緒正面或負面程度。 -
magnitude(規模):範圍從 0 到無限大的數字,代表這段陳述表達的情緒強度,無論是正面還是負面情緒。
長度較長且含有強烈情緒陳述的文字區塊,得到的規模值也越高。第一句的分數為正面 (0.7),第二句的分數則為中立 (0.1)。
工作 5:分析實體情緒
除了提供整份文字文件的情緒詳細資料外,Natural Language API 也能按照文字內容中的實體細分情緒。請使用以下例句:
I liked the sushi but the service was terrible.
上個工作中的做法,也就是取得整個語句的情緒分數,較不適合用於這個示例。如果這是某間餐廳眾多評論中的一則,您可能會想明確掌握其中顧客表示喜歡與不喜歡的部分。Natural Language API 提供了稱為 analyzeEntitySentiment 的方法,可讓您取得文字內容中每個實體的情緒,來看看運作方式吧!
- 使用 nano 編輯器將
request.json更新為以下語句:
-
按下 CTRL+X 退出 nano 編輯器,再按下 Y 鍵儲存檔案,然後按下 ENTER 鍵來確認操作。
-
接著請使用下列 curl 指令呼叫
analyzeEntitySentiment端點:
您會在回應中收到兩個實體物件,分別為「sushi」和「service」。以下是完整的 JSON 回應:
您可以看到系統對「sushi」傳回的分數為中立分數 0,「service」的分數則為 -0.7。分析成效非常出色!您可能也會發現,系統針對每個實體傳回了兩個 sentiment 物件。如果文字內容提及其中一個字詞的次數超過一次,API 就會針對每次提及傳回不同的情緒分數與規模,以及該實體的匯總情緒。
工作 6:分析語法和詞性
語法分析是 Natural Language API 的另一種方法,可讓您進一步瞭解文字內容的語言詳細資訊。analyzeSyntax 會擷取語言資訊,將收到的文字內容拆分為一系列語句和符記 (通常為字詞邊界),以便針對這些符記提供深入分析。API 會針對文字內容中的每個字詞,提供字詞的詞性 (如名詞、動詞和形容詞等) 以及與句子中其他字詞的關係 (例如是根動詞還是修飾語)。
讓我們以簡單的語句試用此方法。接下來的 JSON 要求和目前建立的要求類似,但是多了 features 鍵,指示 API 執行語法註解。
- 使用 nano 編輯器將
request.json中的程式碼替換為下列程式碼:
-
按下 CTRL+X 退出 nano 編輯器,再按下 Y 鍵儲存檔案,然後按下 ENTER 鍵來確認操作。
-
接著呼叫 API 的
analyzeSyntax方法:
系統應會針對語句中的每個符記傳回物件,如下所示:
讓我們進一步瞭解回應內容:
-
partOfSpeech指出「Joanne」為名詞。 -
dependencyEdge包含特定資料,可用來建立文字內容的相依性剖析樹狀結構。基本上,這個圖表會呈現語句中不同字詞之間的關係。上方語句的相依性剖析樹狀結構看起來可能會像這樣:
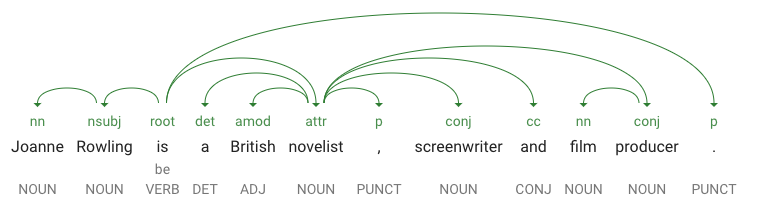
-
headTokenIndex是符記的索引,該符記具有指向「Joanne」的曲線。您可以將語句中的每個符記想像為陣列中的字詞。 - 「Joanne」的
headTokenIndex值 1 指的是「Rowling」這個字詞,「Joanne」在相依性剖析樹狀結構中與此字詞相連。Label 的值NN(「複合名詞修飾語」的縮寫) 說明字詞在語句中的角色:「Joanne」修飾語句的主詞「Rowling」。 -
lemma是字詞的標準格式。舉例來說,run、runs、ran 和 running 這些字詞都以 run 這個詞條為基礎。Lemma 值適合用於持續追蹤特定字詞在一大段文字中的出現次數。
工作 7:多語言自然語言處理
Natural Language API 也支援英語以外的語言 (歡迎前往語言支援指南查看完整清單)。
- 以日文語句修改
request.json中的程式碼:
- 按下 CTRL+X 退出 nano 編輯器,再按下 Y 鍵儲存檔案,然後按下 ENTER 鍵來確認操作。
您會發現,儘管沒有指明文字內容的語言種類,API 也會自動偵測!
- 接著將要求傳送至
analyzeEntities端點:
您會收到以下回應:
Wikipedia 網址甚至會指向日文的 Wikipedia 頁面,是不是非常厲害?
恭喜!
您已瞭解如何使用 Cloud Natural Language API 執行文字分析工作,包括擷取實體、分析情緒及進行語法註解。您已完成以下工作:
- 建立 Natural Language API 要求並使用 curl 呼叫 API
- 使用 Natural Language API 擷取實體並對文字執行情緒分析
- 對文字內容執行語言分析來建立相依性剖析樹狀結構
- 建立日文的 Natural Language API 要求
完成您的任務
這個自修研究室是「機器學習快速入門:語言處理」和「透過 Google Cloud API 執行語言、語音、文字與翻譯相關工作」任務的一部分。「任務」是指一系列相關的研究室課程,藉由課程建立出完整的學習路徑。完成任務後即可獲得徽章,以表彰您的成就。您可以公開展示徽章,並在線上履歷或社群媒體帳戶中加入徽章連結。歡迎報名參加任何包含這個研究室的任務,立即取得完成學分。或是查看其他可開始進行的任務。
挑戰下一個研究室
歡迎嘗試其他機器學習 API 研究室,例如 Vertex AI Workbench 筆記本:Qwik Start 或下列研究室:
後續步驟
- 查看 Natural Language API 說明文件中的教學。
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2023 年 8 月 29 日
研究室上次測試日期:2023 年 8 月 29 日
Copyright 2024 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。