チェックポイント
Create a Cloud Storage bucket
/ 25
Create Cloud Composer environment
/ 25
Uploading the DAG to Cloud Storage
/ 25
Exploring DAG runs
/ 25
Cloud Composer: Qwik Start - Console
GSP261

概要
ワークフローはデータ分析における一般的なテーマのひとつで、データの取り込み、変換、分析によってデータから有益な情報を見つけるために使用されます。Google Cloud には、ワークフローをホストするためのツールとして Cloud Composer が用意されています。これは、よく利用されているオープンソース ワークフロー ツールの Apache Airflow をホスト型にしたものです。
このラボでは、Cloud コンソールを使用して Cloud Composer 環境を作成し、Cloud Composer を使ってシンプルなワークフローを実行します。このワークフローは、データファイルが存在することを確認し、Cloud Dataproc クラスタを作成して Apache Hadoop ワードカウント ジョブを実行した後、Cloud Dataproc クラスタを削除します。
目標
このラボでは、次のタスクの実行方法について学びます。
- Cloud コンソールを使用して Cloud Composer 環境を作成する
- Airflow ウェブ インターフェースで DAG(有向非巡回グラフ)を表示して実行する
- 保存されたワードカウント ジョブの結果を表示する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
出力:
出力例:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Cloud Composer 環境を作成する
このセクションでは、Cloud Composer 環境を作成します。
-
ナビゲーション メニュー (
) > [Composer] に移動します。
-
[環境の作成] をクリックしてプルダウンから [Composer 1] を選択します。
-
環境を以下のように設定します。
-
名前:
highcpu -
ロケーション:
-
イメージのバージョン: 最新バージョンを選択
-
[ゾーン]:
-
マシンタイプ:
e2-standard-2
-
その他の設定はすべてデフォルトのままにします。
- [作成] をクリックします。
Cloud コンソールの [環境] ページで環境の名前の左側に緑色のチェックマークが表示されると、環境作成プロセスが完了したことを表します。
設定プロセスが完了するまで 10~15 分かかることがあります。その間にラボの作業を進めてください。
Cloud Storage バケットを作成する
プロジェクトの Cloud Storage バケットを作成します。このバケットは、Dataproc の Hadoop ジョブの出力に使用されます。
-
ナビゲーション メニュー > [Cloud Storage] > [バケット] に移動し、[作成] をクリックします。
-
バケットに
という名前を付け、 リージョンに設定して、[作成] をクリックします。
この Cloud Storage バケット名(プロジェクト ID)は後ほど Airflow 変数として使用するため、覚えておいてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 2. Airflow と主要なコンセプト
Composer 環境が作成されるまでの間に、Airflow で使用される用語を確認しましょう。
Airflow とは、ワークフローの作成、スケジューリング、モニタリングをプログラムで行うためのプラットフォームです。
Airflow を使用して、ワークフローをタスクの有向非循環グラフ(DAG)として作成します。Airflow スケジューラは、指定された依存関係に従って一連のワーカーでタスクを実行します。
基本コンセプト
有向非循環グラフとは、実行したいすべてのタスクの集まりであり、それらの関係や依存状態を反映するように編成されます。
単一のタスクを記述したもので、通常はアトミックなタスクです。たとえば、BashOperator は bash コマンドの実行に使用されます。
オペレーターのパラメータ化されたインスタンスであり、DAG 内のノードです。
特定のタスクの実行です。DAG、タスク、ある時点を表し、実行中、成功、失敗、スキップなどの状態を示します。
コンセプトの詳細については、Concepts のドキュメントをご覧ください。
タスク 3. ワークフローの定義
これから使用するワークフローについて説明します。Cloud Composer ワークフローは DAG(有向非巡回グラフ)で構成されます。DAG の定義には標準 Python ファイルを使用し、これらのファイルは Airflow の DAG_FOLDER に配置されます。Airflow では各ファイル内のコードを実行して動的に DAG オブジェクトをビルドします。任意の数のタスクを記述した DAG を必要なだけ作成できます。一般に、DAG と論理ワークフローは 1 対 1 で対応している必要があります。
-
Cloud コンソール の右上にある Cloud Shell をアクティブにするアイコンをクリックして、新しい Cloud Shell ウィンドウを開きます。
-
Cloud Shell で、nano(コードエディタの一種)を使って
hadoop_tutorial.pyというファイルを作成します。
- 次のコードは hadoop_tutorial.py ワークフロー(DAG)です。
hadoop_tutorial.pyファイル内に次のコードを貼り付けます。
- Ctrl+O キー、Enter キー、Ctrl+X キーの順番に押して、編集内容を保存してエディタを終了します。
3 つのワークフロー タスクをオーケストレーションするために、DAG は次のオペレーターをインポートします。
-
DataprocClusterCreateOperator: Cloud Dataproc クラスタを作成します。 -
DataProcHadoopOperator: Hadoop ワードカウント ジョブを送信し、結果を Cloud Storage バケットに書き込みます。 -
DataprocClusterDeleteOperator: クラスタを削除して、Compute Engine の利用料金が発生しないようにします。
タスクは順番に実行されます。ファイルの次の部分で確認できます。
この DAG の名前は hadoop_tutorial で、1 日 1 回実行されます。
default_dag_args に渡される start_date は yesterday に設定されているので、Cloud Composer ではワークフローの開始が DAG のアップロード直後に設定されます。
タスク 4. 環境情報を表示する
-
Composer に戻り、環境のステータスを確認します。
-
環境が作成されたら、環境の名前(highcpu)をクリックして詳細を確認します。
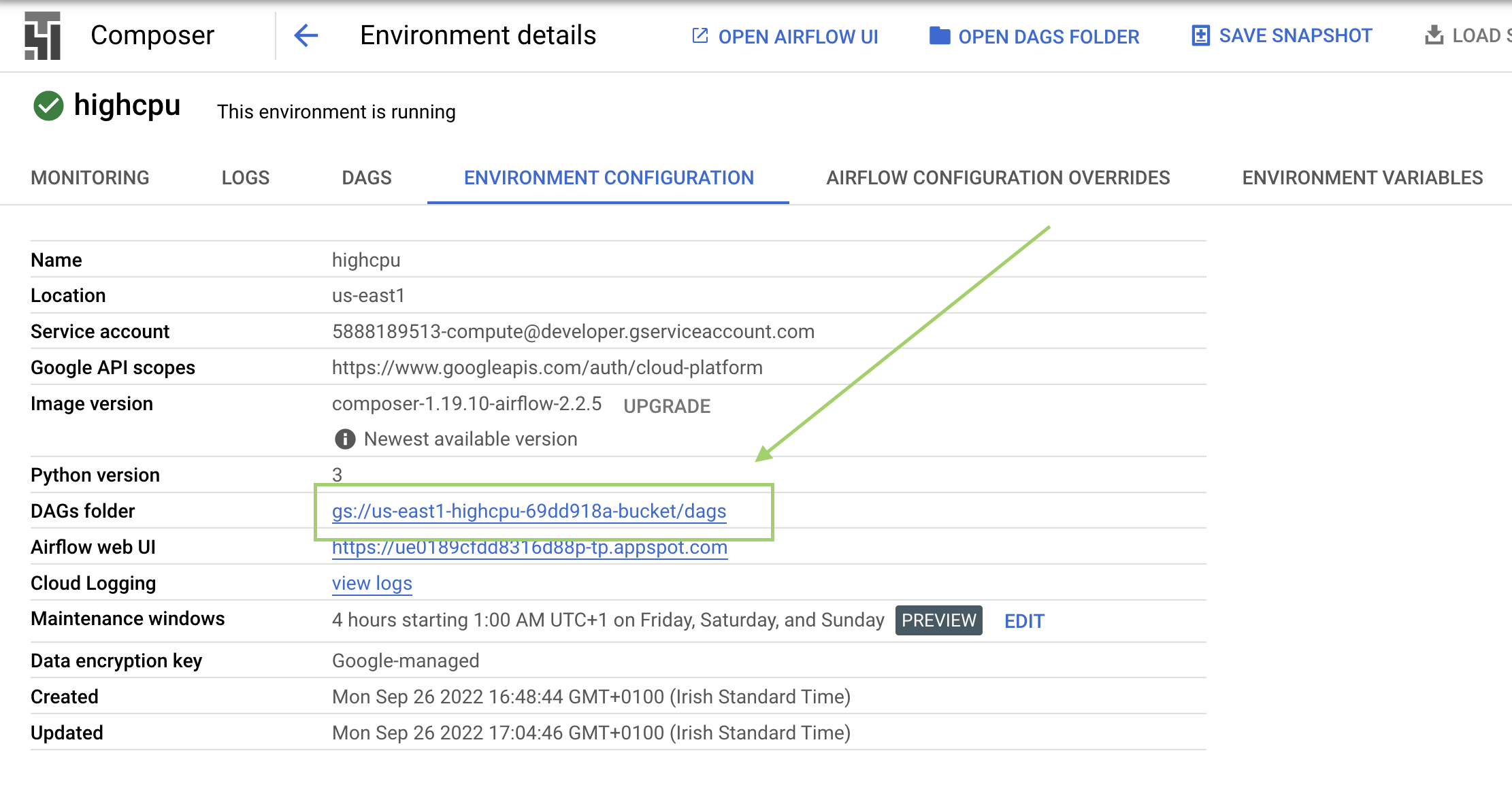
[環境の詳細] で、Airflow ウェブ インターフェース URL、Kubernetes Engine クラスタ ID、バケットに保存されている DAG フォルダへのリンクなどの情報を確認できます。
/dags フォルダ内のワークフローのみです。[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 5. Airflow UI の使用
Cloud コンソールで Airflow ウェブ インターフェースにアクセスするには:
- [環境] ページに戻ります。
- 環境の [Airflow ウェブサーバー] 列で、[Airflow] をクリックします。
- ラボの認証情報をクリックします。
- 新しいウィンドウに Airflow ウェブ インターフェースが表示されます。
タスク 6. Airflow 変数の設定
Airflow 変数は Airflow 固有の概念であり、環境変数とは異なります。
-
Airflow メニューバーで [Admin] > [Variables] を選択し、+(新しいレコードの追加)をクリックします。
-
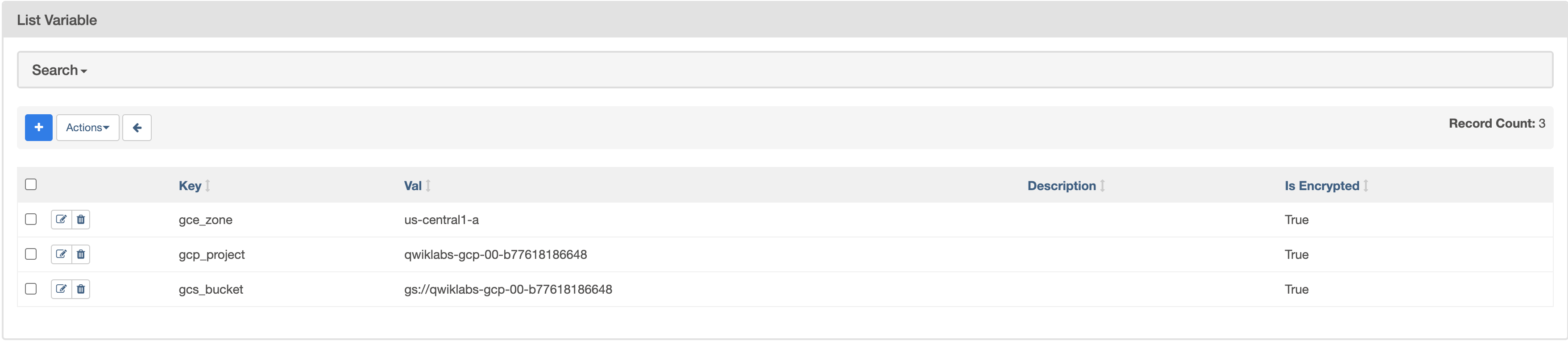
gcp_project、gcs_bucket、gce_zoneの 3 つの Airflow 変数を作成します。
|
キー |
値 |
詳細 |
|
|
|
このクイックスタートで使用する Google Cloud プロジェクトです。 |
|
|
gs:// |
先ほど作成した Cloud Storage バケットの名前。変更していない限りプロジェクト ID と同じになります。このバケットに Dataproc の Hadoop ジョブの出力が保存されます。 |
|
|
|
Cloud Dataproc クラスタを作成する Compute Engine ゾーン。別のゾーンを選択するには、使用可能なリージョンとゾーンをご覧ください。 |
完了すると、Variables のテーブルは次のようになります。
タスク 7. DAG を Cloud Storage にアップロードする
DAG をアップロードするには、hadoop_tutorial.py ファイルのコピーを Cloud Storage バケットにアップロードします。このバケットは、環境を作成したときに自動的に作成されています。
-
これを確認するには、[Composer] > [環境] に移動します。
-
先ほど作成した環境をクリックします。作成した環境の詳細が表示されます。
-
[環境の構成] をクリックします。
-
[
DAG のフォルダ] を見つけて値をコピーし、次のコマンドの<DAGs_folder_path>をその値に置き換え、Cloud Shell でコマンドを実行します。
Cloud Composer により、DAG が Airflow に追加されて自動的にスケジュール設定されます。DAG の変更が 3~5 分で行われます。これ以降、このワークフローを composer_hadoop_tutorial と呼びます。
このタスクのステータスは、Airflow ウェブ インターフェースで確認できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
DAG の実行状況を確認する
DAG ファイルを Cloud Storage の dags フォルダにアップロードすると、ファイルが Cloud Composer によって解析されます。エラーが見つからなければ、このワークフローの名前が DAG のリストに表示され、即時実行されるようキューに登録されます。
Airflow ウェブ インターフェースの [DAGs] タブが表示されていることを確認してください。このプロセスが完了するまで数分かかります。ブラウザの画面を更新して、最新情報を表示してください。
-
Airflow で [composer_hadoop_tutorial] をクリックして DAG の詳細ページを開きます。このページでは、ワークフローのタスクと依存関係が図で示されています。
-
ツールバーの [Graph] をクリックしてグラフを表示します。各タスクのグラフィックにカーソルを合わせると、そのタスクのステータスが表示されます。各タスクを囲む線の色もステータスを表しています(緑は実行中、赤は失敗など)。
-
必要に応じて [Auto refresh] をオンにするか [Refresh] アイコンをクリックして最新の情報に更新します。プロセスを囲む線の色がステータスに応じて変化するのを確認できます。
create_dataproc_cluster を囲む線の色が変化し、ステータスが「running」(実行中)以外になったら、[Graph] から再度ワークフローを実行します。ステータスが「running」の場合は、以下の 3 つのステップは実行不要です。
- [create_dataproc_cluster] グラフィックをクリックします。
- [Clear] をクリックして 3 つのタスクをリセットします。
- 次に、[OK] をクリックして確定します。
create_dataproc_cluster を囲む線の色が変化し、ステータスが「Running」(実行中)になったことに注目してください。
Cloud コンソール でプロセスをモニタリングすることもできます。
- create_dataproc_cluster のステータスが「Running」に変わったら、ナビゲーション メニュー > [Dataproc] に移動し、次の操作を行います。
- [Clusters] をクリックして、クラスタの作成と削除をモニタリングします。ワークフローによって作成されたクラスタは一時的なものです。ワークフローの実行中にのみ存在し、最後のワークフロー タスクで削除されます。
- [Jobs] をクリックして、Apache Hadoop ワードカウント ジョブをモニタリングします。ジョブ ID をクリックすると、ジョブのログ出力を確認できます。
-
Dataproc のステータスが「Running」になったら Airflow に戻って [Refresh] をクリックすると、クラスタが完成したことを確認できます。
-
run_dataproc_hadoopプロセスが完了したら、ナビゲーション メニュー > [Cloud Storage] > [バケット] に移動し、バケット名をクリックしてwordcountフォルダでワードカウントの結果を確認できます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
理解度テスト
クイズに挑戦して Google Cloud Platform に関するご自分の知識をチェックしましょう。
Cloud Composer 環境を削除する
- [Composer] の [環境] ページに戻ります。
- Composer 環境の横にあるチェックボックスを選択します。
- [削除] をクリックします。
- もう一度 [削除] をクリックして、ポップアップを確認します。
お疲れさまでした
これで完了です。このラボでは、Cloud Composer 環境を作成して Cloud Storage に DAG をアップロードし、ワークフローを実行して、Cloud Dataproc クラスタの作成、Hadoop ワードカウント ジョブの実行、クラスタの削除を行いました。また、Airflow と基本コンセプトについて学び、Airflow ウェブ インターフェースを操作しました。Cloud Composer を使用して、独自のワークフローを作成して管理できるようになりました。
次のステップ
このラボは、Google Cloud の多くの機能を体験できる「Qwik Start」と呼ばれるラボシリーズの一部です。ラボカタログで「Qwik Start」を検索し、興味のあるラボを探してみてください。
- 変数の値を表示するには、Airflow CLI サブコマンド variables に get 引数を指定して実行するか、Airflow ウェブ インターフェースを使用します。
- Airflow ウェブ インターフェースについて詳しくは、ウェブ インターフェースへのアクセスをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 12 月 18 日
ラボの最終テスト日: 2023 年 12 月 18 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。