Points de contrôle
Create a cloud storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25
Présentation de SQL pour BigQuery et Cloud SQL
GSP281

Présentation
SQL (Structured Query Language) est un langage standard de manipulation des données permettant d'interroger des ensembles structurés pour en retirer des insights exploitables. Fréquemment utilisé pour gérer des bases de données, ce langage vous permet par exemple de saisir des enregistrements de transactions dans des bases de données relationnelles et d'analyser des pétaoctets de données.
Il se divise en deux parties. La première présente les principaux mots clés utilisés dans les requêtes SQL ; à titre d'exemple, vous exécuterez des requêtes dans BigQuery sur un ensemble de données public portant sur le système de vélos en libre-service à Londres.
La seconde vous montre comment exporter des sous-ensembles de cet ensemble de données dans des fichiers CSV pour les importer ensuite dans Cloud SQL. Puis, vous apprendrez à créer et gérer des bases de données et des tables à l'aide de Cloud SQL. À la fin de l'atelier, vous vous entraînerez à utiliser d'autres mots clés SQL pour manipuler et modifier des données.
Points abordés
Dans cet atelier, vous allez apprendre à :
- charger des bases de données et des tables dans BigQuery ;
- exécuter des requêtes simples sur des tables pour extraire des données pertinentes d'ensembles de données ;
- exporter un sous-ensemble de données sous forme de fichier CSV et stocker ce fichier dans un nouveau bucket Cloud Storage ;
- créer une instance Cloud SQL et charger le fichier CSV exporté en tant que nouvelle table.
Prérequis
Très important : Avant de commencer cet atelier, déconnectez-vous de votre compte Gmail personnel ou professionnel.
Cet atelier s'adresse aux débutants. Il ne nécessite aucune connaissance particulière du langage SQL. Une connaissance préalable de Cloud Storage et de Cloud Shell est recommandée, mais pas indispensable. Dans cet atelier, vous apprendrez les principes de base permettant d'interpréter et de rédiger des requêtes SQL. Vous mettrez ensuite en pratique vos connaissances dans BigQuery et Cloud SQL.
Avant de commencer cet atelier, évaluez vos compétences en programmation SQL. Les ateliers suivants, plus complexes, vous permettront d'appliquer votre savoir à des cas d'utilisation plus avancés :
- Données météorologiques dans BigQuery
- Analyser les données relatives à la natalité à l'aide de Vertex AI et BigQuery
Lorsque vous êtes prêt, faites défiler la page vers le bas pour passer à la configuration de l'atelier.
Prérequis
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Tâche 1 : Principes de base de SQL
Bases de données et tables
Comme expliqué précédemment, SQL vous permet d'extraire des informations provenant d'ensembles de données structurés. Ces ensembles suivent des règles et une mise en forme spécifiques, et sont très souvent composés de tables (données organisées en lignes et en colonnes).
Les fichiers image constituent un exemple de données non structurées. Les données non structurées ne peuvent ni être utilisées avec SQL, ni être stockées dans des ensembles de données ou tables BigQuery, du moins pas de manière native. Pour travailler sur des données d'images (par exemple), vous pouvez utiliser un service tel que Cloud Vision, qui propose aussi une API pour un accès direct.
Voici un exemple d'ensemble de données structuré, ici un simple tableau :
|
Utilisateur |
Prix |
Expédié |
|
Alexandre |
35 € |
Oui |
|
Théo |
50 € |
Non |
Si vous avez déjà utilisé Google Sheets, la présentation du tableau ci-dessus doit vous paraître familière. Il comprend des colonnes "Utilisateur", "Prix" et "Expédié", et deux lignes avec des valeurs dans ces colonnes.
Une base de données se compose essentiellement d'un ou de plusieurs tableaux, appelés tables. SQL est un outil de gestion de bases de données structurées. Toutefois, dans de nombreux cas (par exemple, dans cet atelier), les requêtes ne sont pas exécutées sur des bases de données complètes, mais sur une table ou un petit nombre de tables associées.
SELECT et FROM
La syntaxe de SQL est phonétique par nature. Commencez toujours par formuler la question à laquelle vous souhaitez répondre avant d'interroger les données à l'aide d'une requête, sauf si vous explorez sans but précis.
SQL dispose de mots clés anglais prédéfinis permettant de traduire votre question en code SQL, afin que le moteur de base de données vous communique la réponse.
Les premiers mots clés à connaître sont SELECT et FROM :
-
SELECTpermet de spécifier les champs que vous souhaitez extraire de l'ensemble de données. -
FROMpermet de spécifier la ou les tables contenant les données à extraire.
Voici un exemple pour illustrer ce propos. Imaginez que vous disposez de la table suivante, appelée example_table, qui contient les colonnes USER (Utilisateur), PRICE (Prix) et SHIPPED (Expédié) :
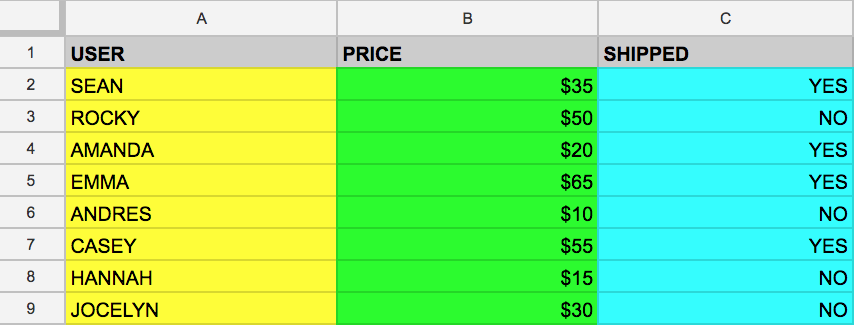
À présent, supposons que vous souhaitiez extraire uniquement les données de la colonne USER (Utilisateur). Pour ce faire, exécutez la requête suivante, qui utilise SELECT et FROM :
L'exécution de la commande ci-dessus sélectionne tous les noms de la colonne USER (Utilisateur) figurant dans la table example_table.
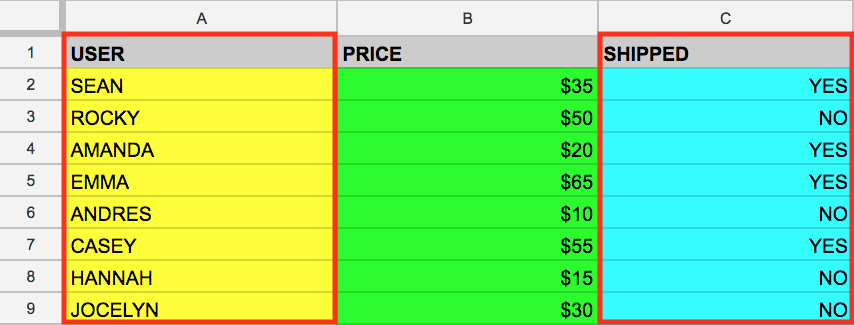
Vous pouvez aussi sélectionner plusieurs colonnes avec le mot clé SQL SELECT. Supposons que vous souhaitiez extraire les données situées dans les colonnes USER (Utilisateur) et SHIPPED (Expédié). Pour ce faire, ajoutez une valeur de colonne à la précédente requête SELECT (séparez-la de l'autre valeur avec une virgule) :
L'exécution de cette requête récupère les données USER (Utilisateur) et SHIPPED (Expédié) de la mémoire :
Vous venez d'apprendre à utiliser deux des principaux mots clés SQL. Voyons à présent une syntaxe un peu plus avancée.
WHERE
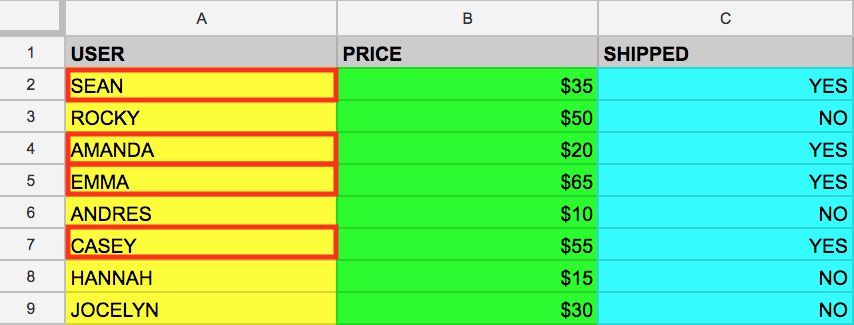
Le mot clé WHERE est une autre commande SQL qui permet de filtrer les tables pour en extraire des valeurs de colonnes spécifiques. Supposons que vous souhaitiez extraire de la table example_table les noms des utilisateurs dont les colis ont été expédiés. Il suffit pour cela d'ajouter une commande WHERE à la requête, comme suit :
Exécuter cette requête renvoie tous les utilisateurs (données USER) de la mémoire dont les colis ont été expédiés (données SHIPPED) :
Maintenant que vous savez comment utiliser les principaux mots clés SQL, vous allez appliquer ce que vous avez appris en exécutant ces types de requêtes dans la console BigQuery.
Tester vos connaissances
Les questions à choix multiples suivantes vous permettront de mieux maîtriser les concepts abordés jusque-là. Répondez-y du mieux que vous le pouvez.
Tâche 2 : Découvrir la console BigQuery
Le paradigme BigQuery
BigQuery est un entrepôt de données entièrement géré à l'échelle du pétaoctet, qui s'exécute sur Google Cloud. Grâce à lui, les analystes de données et les data scientists peuvent interroger et filtrer rapidement de larges ensembles de données, regrouper les résultats et effectuer des opérations complexes, sans avoir à configurer ou à gérer des serveurs. BigQuery se présente sous la forme d'un outil de ligne de commande (préinstallé dans Cloud Shell) ou d'une console Web, et permet de gérer et d'interroger facilement les données contenues dans des projets Google Cloud.
Dans cet atelier, vous allez exécuter des requêtes SQL à l'aide de la console Web.
Ouvrir la console BigQuery
- Dans la console Google Cloud, sélectionnez le menu de navigation > BigQuery.
Le message Bienvenue sur BigQuery dans Cloud Console s'affiche. Il contient un lien vers le guide de démarrage rapide et les notes de version.
- Cliquez sur OK.
La console BigQuery s'ouvre.
Prenez quelques instants pour passer en revue les principales fonctionnalités de l'interface utilisateur. L'éditeur de requête se trouve dans la partie droite de la console. C'est dans cet éditeur que vous saisissez et exécutez des commandes SQL semblables aux exemples décrits plus haut. En dessous se trouve la section "Historique des requêtes", qui répertorie les requêtes précédemment exécutées.
Le volet gauche de la console correspond au menu de navigation. En plus des onglets d'historique des requêtes, de requêtes enregistrées et d'historique des jobs, vous trouverez l'onglet Explorateur.
Dans l'onglet Explorateur, le niveau de ressources le plus élevé contient les projets Google Cloud, semblables aux projets temporaires auxquels vous vous connectez et que vous utilisez dans les ateliers Google Cloud Skills Boost. Comme vous pouvez le constater dans la console et sur la dernière capture d'écran, l'onglet "Explorateur" contient uniquement votre projet. Si vous cliquez sur la flèche située à côté du nom du projet, rien ne s'affiche.
En effet, votre projet ne contient aucun ensemble de données ni aucune table que vous pourriez interroger. Comme indiqué précédemment, les ensembles de données contiennent des tables. Lorsque vous ajoutez des données à votre projet, souvenez-vous que dans BigQuery, les projets contiennent des ensembles de données comprenant eux-mêmes des tables. Maintenant que vous avez compris le paradigme projet > ensemble de données > table, ainsi que les subtilités de la console, vous pouvez charger des données à interroger à l'aide de requêtes.
Importation de données pouvant être interrogées
Dans cette section, vous allez importer des données publiques afin de vous entraîner à exécuter des commandes SQL dans BigQuery.
-
Cliquez sur + AJOUTER.
-
Sélectionnez Ajouter un projet aux favoris en saisissant son nom.
-
Saisissez bigquery-public-data comme nom de projet.
-
Cliquez sur AJOUTER AUX FAVORIS.
Il est important de noter que vous travaillez encore sur le projet de l'atelier dans ce nouvel onglet. Vous avez simplement importé dans BigQuery un projet accessible publiquement contenant des ensembles de données et des tables afin de l'analyser. Vous n'avez pas basculé vers ce projet. L'ensemble de vos jobs et services sont encore liés à votre compte Google Cloud Skills Boost. Vous pouvez le constater vous-même en inspectant le champ de projet situé vers le haut de la console :
- Vous avez à présent accès aux données suivantes :
- Projet Google Cloud →
bigquery-public-data - Ensemble de données →
london_bicycles
- Cliquez sur l'ensemble de données london_bicycles pour afficher les tables associées.
- Table →
cycle_hire - Table →
cycle_stations
Dans cet atelier, vous allez utiliser les données de cycle_hire. Ouvrez la table cycle_hire, puis cliquez sur l'onglet Aperçu. La page qui s'affiche doit ressembler à celle-ci :
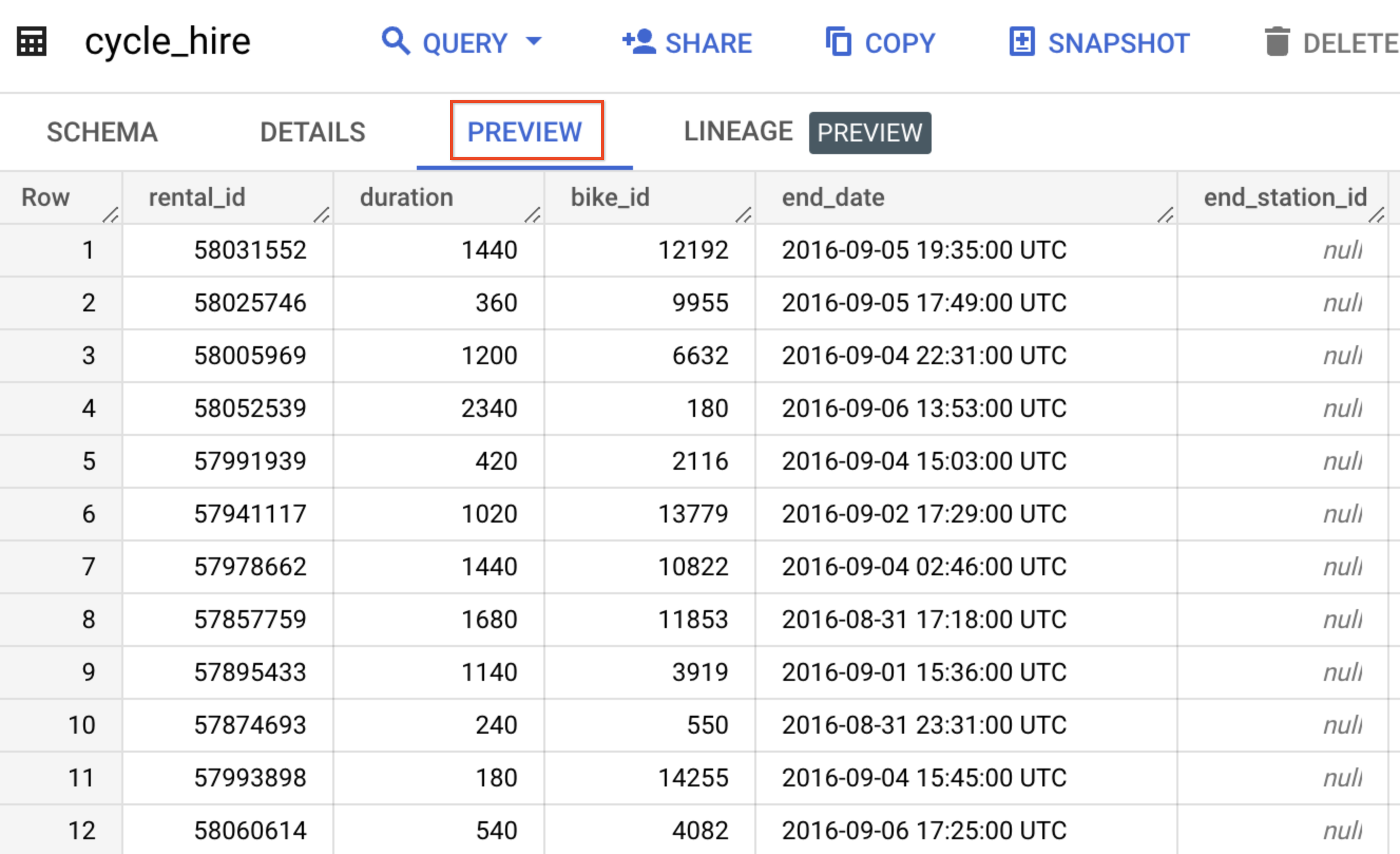
Inspectez les colonnes et les valeurs insérées dans les lignes. Vous êtes prêt à exécuter des requêtes SQL sur la table cycle_hire.
Exécution de SELECT, FROM et WHERE dans BigQuery
Vous maîtrisez désormais les fondamentaux de l'utilisation des mots clés de requête SQL et du paradigme de données BigQuery, et vous disposez de données à analyser. Vous pouvez donc exécuter des commandes SQL à l'aide de ce service.
En regardant en bas à droite de la console, vous remarquerez que la table contient 24 369 201 lignes de données, correspondant au nombre (conséquent !) de trajets effectués à vélo en libre-service à Londres entre 2015 et 2017.
Notez le nom de la clé de la septième colonne, end_station_name. Elle spécifie à quelle station les vélos empruntés sont rendus. Avant de passer à des requêtes plus avancées, exécutez une requête simple afin d'isoler la colonne end_station_name.
- Copiez et collez la commande suivante dans l'éditeur de requête :
- Ensuite, cliquez sur Exécuter.
Environ 20 secondes plus tard, la requête doit afficher 24 369 201 lignes contenant uniquement la colonne end_station_name, la seule sur laquelle elle portait.
Déterminez à présent le nombre de trajets à vélo ayant duré 20 minutes ou plus.
- Effacez la précédente requête de l'éditeur, puis exécutez la requête suivante qui utilise le mot clé
WHERE:
Exécuter cette requête peut prendre environ une minute.
La requête SELECT * renvoie toutes les valeurs de colonne de la table. La durée est mesurée en secondes. C'est pourquoi vous avez utilisé la valeur 1 200 (60 x 20).
En regardant en bas à droite, vous constaterez que la requête a renvoyé 7 334 890 lignes. Si l'on compare ce nombre au total de trajets à vélo (7 334 890 ÷ 24 369 201), cela signifie qu'environ 30 % des trajets à vélo en libre-service à Londres ont duré au moins 20 minutes. Les utilisateurs effectuent donc de longs trajets.
Tester vos connaissances
Les questions à choix multiples suivantes vous permettront de mieux maîtriser les concepts abordés jusque-là. Répondez-y du mieux que vous le pouvez.
Tâche 3 : Autres mots clés SQL : GROUP BY, COUNT, AS et ORDER BY
GROUP BY
Le mot clé GROUP BY permet de regrouper les lignes présentant un ensemble de résultats qui partagent des critères communs, comme une valeur de colonne, et d'afficher toutes les entrées uniques déterminées en fonction de ces critères.
Ce mot clé s'utilise souvent pour regrouper par catégorie les informations contenues dans les tables.
- Pour mieux comprendre la fonction de ce mot clé, effacez la précédente requête de l'éditeur, puis copiez et collez la commande suivante :
- Cliquez sur Exécuter.
Les résultats se présentent sous la forme d'une liste de valeurs de colonnes uniques (valeurs non dupliquées).
Sans le mot clé GROUP BY, la requête aurait renvoyé la totalité des 24 369 201 lignes. GROUP BY affiche les valeurs uniques des colonnes de la table. Vous pouvez le constater vous-même en regardant en bas à droite de la console. 880 lignes s'affichent, ce qui signifie qu'il existe 880 stations de retrait de vélos en libre-service à Londres.
COUNT
La fonction COUNT() affiche le nombre de lignes qui partagent les mêmes critères, tels que des valeurs de colonnes. Elle peut être très utile lorsqu'elle est associée au mot clé GROUP BY.
Ajoutez la fonction COUNT à la requête précédente afin de déterminer le nombre de vélos empruntés dans chaque station de retrait.
- Effacez la précédente requête de l'éditeur, copiez et collez la commande suivante, puis cliquez sur Exécuter :
Le résultat indique le nombre de vélos en libre-service empruntés dans chaque station de retrait.
AS
Les requêtes SQL peuvent également inclure un mot clé AS, qui crée un alias pour une table ou une colonne. L'alias spécifié par AS est un nouveau nom attribué à la colonne ou à la table renvoyée.
- Ajoutez le mot clé
ASà la dernière requête exécutée pour observer son fonctionnement. Effacez la précédente requête de l'éditeur, puis copiez et collez la commande suivante :
- Cliquez sur Exécuter.
Dans l'onglet "Résultats", la colonne de droite COUNT(*) porte maintenant le nom num_starts.
Comme vous pouvez le voir, la colonne COUNT(*) de la table renvoyée porte maintenant l'alias num_starts. Ce mot clé est utile, en particulier si vous gérez des ensembles de données importants. En effet, il n'est pas rare d'oublier à quoi correspond un nom de colonne ou de table ambigu.
ORDER BY
Le mot clé ORDER BY trie les données affichées par une requête par ordre croissant ou décroissant, en fonction d'un critère ou d'une valeur de colonne donnée. Ajoutez ce mot clé à la précédente requête pour effectuer les opérations suivantes :
- Afficher une table contenant le nombre de vélos en libre-service empruntés dans chaque station de retrait, en triant ces stations par ordre alphabétique
- Afficher une table contenant le nombre de vélos en libre-service empruntés dans chaque station de retrait, en triant les résultats par ordre croissant
- Afficher une table contenant le nombre de vélos en libre-service empruntés dans chaque station de retrait, en triant les résultats par ordre décroissant
Chacune des commandes ci-après est une requête distincte. Pour chaque commande :
- Effacez le contenu de l'éditeur de requête.
- Copiez et collez la commande dans l'éditeur de requête.
- Cliquez sur Exécuter. Parcourez les résultats.
Le résultat de la dernière requête liste les stations de retrait par nombre de retraits effectués dans la station.
Vous pouvez constater que la station "Belgrove Street, King's Cross" a enregistré le plus grand nombre de retraits. Toutefois, en comparant ce nombre au total de retraits de vélos (234 458 ÷ 24 369 201), vous pouvez voir que moins de 1 % des retraits sont effectués dans cette station.
Tester vos connaissances
Les questions à choix multiples suivantes vous permettront de mieux maîtriser les concepts abordés jusque-là. Répondez-y du mieux que vous le pouvez.
Tâche 4 : Utiliser Cloud SQL
Exporter des requêtes en tant que fichiers CSV
Cloud SQL est un service de base de données entièrement géré qui facilite la configuration, la maintenance, la gestion et l'administration de vos bases de données relationnelles PostgreSQL et MySQL dans le cloud. Deux formats de fichiers sont compatibles avec Cloud SQL : les fichiers de dump (.sql) et les fichiers CSV (.csv). Vous allez apprendre à exporter des sous-ensembles de la table cycle_hire sous forme de fichiers CSV et à les importer dans Cloud Storage, qui sert ici d'emplacement intermédiaire.
Revenez à la console BigQuery. La dernière commande exécutée doit être la suivante :
-
Dans la section "Résultats de la requête", cliquez sur ENREGISTRER LES RÉSULTATS > CSV (fichier local). Le téléchargement débute, et la requête est enregistrée sous la forme d'un fichier CSV. Notez l'emplacement et le nom du fichier téléchargé. Vous en aurez besoin prochainement.
-
Effacez le contenu de l'éditeur de requête, copiez-y la commande suivante, puis exécutez-la :
Cette commande renvoie une table contenant le nombre de vélos restitués dans chaque station de dépôt. Les résultats sont triés par ordre décroissant.
- Dans la section "Résultats de la requête", cliquez sur ENREGISTRER LES RÉSULTATS > CSV (fichier local). Le téléchargement débute, et la requête est enregistrée sous la forme d'un fichier CSV. Notez l'emplacement et le nom du fichier téléchargé. Vous en aurez besoin dans la section suivante.
Importer des fichiers CSV dans Cloud Storage
-
Accédez à la console Cloud, où vous créerez un bucket de stockage dans lequel vous pourrez importer les fichiers que vous venez de créer.
-
Dans le menu de navigation, sélectionnez Cloud Storage > Buckets, puis cliquez sur CRÉER UN BUCKET.
-
Saisissez un nom unique pour le bucket, puis, sans modifier les valeurs par défaut de tous les autres paramètres, cliquez sur Créer.
-
Si vous y êtes invité, cliquez sur Confirmer dans la boîte de dialogue
L'accès public sera bloqué.
Tester la tâche terminée
Cliquez sur Vérifier ma progression ci-dessous pour vérifier votre progression dans l'atelier. Si le bucket a bien été créé, vous recevez une note d'évaluation.
Vous devriez à présent vous trouver dans la console Google Cloud, où le bucket Cloud Storage que vous venez de créer est affiché.
-
Cliquez sur IMPORTER DES FICHIERS et sélectionnez le fichier CSV contenant les données
start_station_name. -
Cliquez ensuite sur Ouvrir. Répétez cette opération pour les données
end_station_name. -
Renommez le fichier
start_station_nameen cliquant sur les trois points situés au bout de la ligne correspondante, puis sur Renommer. Attribuez-lui le nomstart_station_data.csv. -
Renommez le fichier
end_station_nameen cliquant sur les trois points situés au bout de la ligne correspondante, puis sur Renommer. Attribuez-lui le nomend_station_data.csv.
start_station_data.csv et end_station_data.csv devraient maintenant figurer dans la liste Objets sur la page Informations sur le bucket.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si vous avez correctement importé des objets CSV dans votre bucket, vous recevez une note d'évaluation.
Tâche 5 : Créer une instance Cloud SQL
Dans le menu de navigation de la console, sélectionnez SQL.
-
Cliquez sur CRÉER UNE INSTANCE > Choose MySQL (Choisir MySQL).
-
Saisissez my-demo comme ID d'instance.
-
Saisissez un mot de passe sécurisé dans le champ Mot de passe (retenez bien ce mot de passe).
-
Sélectionnez MySQL 8 comme version de base de données.
-
Dans Choisir une édition Cloud SQL, sélectionnez Enterprise.
-
Dans Prédéfini, sélectionnez Développement (4 vCPU, 16 Go de RAM, 100 Go de stockage, zone unique).
-
Définissez le champ Multi zones (Highly available) (Zones multiples [disponibilité élevée]) sur
. -
Cliquez sur CRÉER UNE INSTANCE.
- Cliquez sur l'instance Cloud SQL. La page Présentation de SQL s'ouvre.
Tester la tâche terminée
Pour vérifier votre progression dans cet atelier, cliquez sur Vérifier ma progression ci-dessous. Si l'instance Cloud SQL a bien été configurée, vous recevez une note d'évaluation.
Tâche 6 : Nouvelles requêtes dans Cloud SQL
Mot clé CREATE (bases de données et tables)
Maintenant que vous avez une instance Cloud SQL opérationnelle, créez-y une base de données à l'aide de la ligne de commande Cloud Shell.
-
Ouvrez Cloud Shell en cliquant sur l'icône située en haut à droite de la console.
-
Exécutez la commande suivante pour définir votre ID de projet comme variable d'environnement :
Créer une base de données dans Cloud Shell
- Exécutez la commande suivante dans Cloud Shell pour configurer l'authentification sans ouvrir le navigateur.
Vous obtenez alors un lien à ouvrir dans votre navigateur. Ouvrez-le dans le même navigateur que celui où vous êtes connecté à votre compte Qwiklabs. Une fois connecté, copiez le code de validation qui s'affiche. Collez-le ensuite dans Cloud Shell.
- Exécutez la commande suivante afin de vous connecter à l'instance SQL, en remplaçant
my-demosi vous avez attribué un autre nom à l'instance :
- Lorsque vous y êtes invité, saisissez le mot de passe racine que vous avez défini pour l'instance.
Vous devriez obtenir un résultat semblable à celui-ci :
Bien que les instances Cloud SQL comprennent des bases de données préconfigurées, vous allez créer votre propre base de données afin de stocker les données relatives aux vélos en libre-service à Londres.
- Exécutez la commande suivante dans l'invite de commande du serveur MySQL pour créer une base de données appelée
bike:
Vous devez obtenir le résultat suivant :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si vous avez réussi à créer une base de données dans l'instance Cloud SQL, vous verrez une note d'évaluation s'afficher.
Créer une table dans Cloud Shell
- Créez une table au sein de la base de données "bike" en exécutant la commande suivante :
Cette instruction utilise le mot clé CREATE, mais inclut cette fois-ci la clause TABLE, qui signifie que la commande doit créer une table, et non pas une base de données. Le mot clé USE indique la base de données à laquelle vous voulez vous connecter. Vous disposez désormais d'une table nommée "london1" contenant deux colonnes : "start_station_name" et "num". Le type de données VARCHAR(255) spécifie une limite de 255 caractères pour les colonnes dont la longueur de chaîne est variable, et le mot clé INT indique que les colonnes doivent contenir des nombres entiers.
- Créez une autre table, nommée "london2", en exécutant la commande suivante :
- Vérifiez maintenant que les tables vides ont été créées. Exécutez les commandes suivantes dans l'invite de commande du serveur MySQL :
Vous devez obtenir le résultat suivant pour les deux commandes :
La mention "empty set" (ensemble vide) s'affiche, car vous n'avez encore chargé aucune donnée.
Importer des fichiers CSV dans des tables
Revenez maintenant à la console Cloud SQL. Vous allez à présent importer les fichiers CSV start_station_name et end_station_name dans les tables "london1" et "london2" que vous venez de créer.
- Sur la page de votre instance Cloud SQL, cliquez sur IMPORTER.
- Dans le champ du fichier Cloud Storage, cliquez sur Parcourir, puis sur la flèche à côté du nom du bucket, et pour finir sur
start_station_data.csv. Ensuite, cliquez sur Sélectionner. - Sélectionnez CSV comme format de fichier.
- Sélectionnez la base de données
bikeet renseignezlondon1comme table. - Cliquez sur Importer.
Répétez cette opération pour l'autre fichier CSV.
- Sur la page de votre instance Cloud SQL, cliquez sur IMPORTER.
- Dans le champ du fichier Cloud Storage, cliquez sur Parcourir, puis sur la flèche à côté du nom du bucket, et pour finir sur
end_station_data.csv. Ensuite, cliquez sur Sélectionner. - Sélectionnez CSV comme format de fichier.
- Sélectionnez la base de données "bike" et indiquez la table
london2. - Cliquez sur Importer.
Les deux fichiers CSV devraient désormais avoir été importés dans des tables de la base de données bike.
- Revenez à la session Cloud Shell et exécutez la commande suivante dans l'invite de commande du serveur MySQL pour inspecter le contenu de la table "london1" :
La commande doit renvoyer 955 lignes de résultats, chacune correspondant à un nom de station unique.
- Exécutez la commande suivante pour vous assurer que la table "london2" a bien été remplie :
La commande doit renvoyer 959 lignes de résultats, chacune correspondant à un nom de station unique.
Mot clé DELETE
Voici quelques autres mots clés SQL permettant de gérer des données plus facilement. Le premier est le mot clé DELETE.
- Exécutez les commandes suivantes sur la session MySQL pour supprimer la première ligne des tables "london1" et "london2" :
Vous devez obtenir le résultat suivant après exécution des deux commandes :
Les lignes qui contenaient les en-têtes de colonnes dans les fichiers CSV ont été supprimées. Le mot clé DELETE ne supprime pas la première ligne du fichier en soi, mais toutes les lignes de la table dont le nom de colonne (ici "num") contient une valeur spécifiée (ici "0"). Si vous exécutez les requêtes SELECT * FROM london1; et SELECT * FROM london2; et que vous faites défiler la page jusqu'à atteindre le haut de la table, vous constaterez que ces lignes n'existent plus.
Mot clé INSERT INTO
Vous pouvez également insérer des valeurs dans des tables à l'aide du mot clé INSERT INTO.
- Exécutez la commande suivante pour insérer une nouvelle ligne dans la table "london1", qui définit
start_station_namesur "test destination" etnumsur "1" :
Le mot clé INSERT INTO nécessite d'indiquer une table (london1). Il crée une nouvelle ligne contenant les colonnes spécifiées par les termes de la première parenthèse (ici, "start_station_name" et "num"). Les éléments indiqués après la clause "VALUES" sont insérés en tant que valeurs dans la nouvelle ligne.
Vous devez obtenir le résultat suivant :
Si vous exécutez la requête SELECT * FROM london1;, une nouvelle ligne s'affiche au bas de la table "london1".
Mot clé UNION
Le dernier mot clé SQL que nous allons apprendre à utiliser est UNION. Ce mot clé combine les résultats de plusieurs requêtes SELECT en un seul ensemble. Vous utiliserez UNION pour associer les sous-ensembles des tables "london1" et "london2".
La requête en chaîne suivante récupère des données spécifiques des deux tables et les associe à l'aide de l'opérateur UNION.
- Exécutez la commande suivante dans l'invite de commande du serveur MySQL :
La première requête SELECT sélectionne les deux colonnes de la table "london1" et crée un alias pour "start_station_name", qui prend alors le nom de "top_stations". Le mot clé WHERE permet de récupérer uniquement le nom des stations de vélos en libre-service où sont retirés plus de 100 000 vélos.
La seconde requête SELECT sélectionne les deux colonnes de la table "london2", et le mot clé WHERE permet de récupérer uniquement le nom des stations de vélos en libre-service où sont déposés plus de 100 000 vélos.
Le mot clé UNION situé entre les deux requêtes associe leurs résultats en combinant les données des tables "london1" et "london2". Du fait de l'association des tables "london1" et "london2", les valeurs des colonnes qui prévalent sont "top_stations" et "num".
Le mot clé ORDER BY trie la table finale associée en classant les valeurs de la colonne "top_stations" par ordre alphabétique et décroissant.
Vous devez obtenir le résultat suivant :
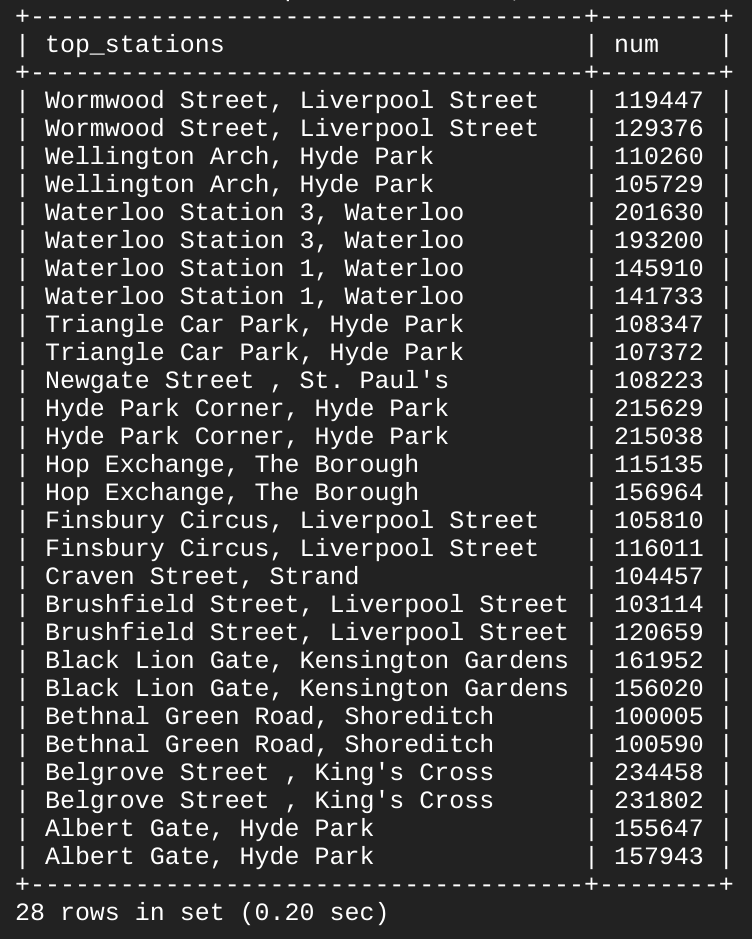
Comme vous pouvez le constater, 13 stations sur 14 constituent à la fois le principal lieu de retrait et de dépôt des vélos en libre-service. Ces quelques mots clés SQL de base vous ont permis d'interroger un ensemble de données de taille conséquente, qui vous a renvoyé des points de données ainsi que des réponses à des questions spécifiques.
Félicitations !
Dans cet atelier, vous avez découvert les principes de base du langage SQL. Vous avez également appris à appliquer des mots clés et à exécuter des requêtes dans BigQuery et CloudSQL. Vous avez découvert les principaux concepts concernant les projets, les bases de données et les tables. Vous vous êtes entraîné à utiliser les mots clés permettant de manipuler et de modifier des données. Vous avez appris à charger des ensembles de données dans BigQuery et vous vous êtes entraîné à exécuter des requêtes sur des tables. Vous avez appris à créer des instances dans Cloud SQL et vous avez découvert comment transférer des sous-ensembles de données vers des tables contenues dans des bases de données. Vous avez associé et exécuté des requêtes dans Cloud SQL et vous êtes parvenu à des conclusions intéressantes sur les stations de retrait et de dépôt de vélos en libre-service à Londres.
Terminer votre quête
Cet atelier d'auto-formation fait partie des quêtes Data Science on Google Cloud, Cloud SQL, BigQuery Basics for Data Analysts, NCAA® March Madness®: Bracketology with Google Cloud, Cloud Engineering, Data Catalog Fundamentals et Applying BQML's Classification, Regression, and Demand Forecasting for Retail Applications. Une quête est une série d'ateliers associés qui constituent un parcours de formation. Si vous terminez une quête, vous obtenez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à n'importe quelle quête contenant cet atelier pour obtenir immédiatement les crédits associés. Découvrez toutes les quêtes disponibles dans le catalogue Google Cloud Skills Boost.
Étapes suivantes et informations supplémentaires
Continuez à vous former et à vous entraîner à utiliser Cloud SQL et BigQuery grâce à ces ateliers Google Cloud Skills Boost :
- Données météorologiques dans BigQuery
- Explorer les données NCAA à l'aide de BigQuery
- Charger des données dans Google Cloud SQL
- Utiliser Cloud SQL avec Terraform
Approfondissez vos connaissances sur la science des données avec le livre Data Science on the Google Cloud Platform, 2nd Edition d'O'Reilly Media, Inc..
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 16 janvier 2024
Dernier test de l'atelier : 6 octobre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.