Prüfpunkte
Create Cloud Dataproc cluster
/ 50
Create a Logistic Regression Model
/ 50
Machine Learning with Spark on Google Cloud Dataproc
- GSP271
- Overview
- Setup and requirements
- Task 1. Create a Dataproc cluster
- Task 2. Set up bucket and start pyspark session
- Task 3. Read and clean up dataset
- Task 4. Develop a logistic regression model
- Task 5. Save and restore a logistic regression model
- Task 6. Predict with the logistic regression model
- Task 7. Examine model behavior
- Task 8. Evaluate the model
- Congratulations!
GSP271

Overview
Introduction
In this lab you implement logistic regression using a machine learning library for Apache Spark. Spark runs on a Dataproc cluster to develop a model for data from a multivariable dataset.
Dataproc is a fast, easy-to-use, fully-managed cloud service for running Apache Spark and Apache Hadoop clusters in a simple, cost-efficient way. Dataproc easily integrates with other Google Cloud services, giving you a powerful and complete platform for data processing, analytics and machine learning
Apache Spark is an analytics engine for large scale data processing. Logistic regression is available as a module in Apache Spark's machine learning library, MLlib. Spark MLlib, also called Spark ML, includes implementations for most standard machine learning algorithms such as k-means clustering, random forests, alternating least squares, k-means clustering, decision trees, support vector machines, etc. Spark can run on a Hadoop cluster, like Dataproc, in order to process very large datasets in parallel.
The base dataset this lab uses is retrieved from the US Bureau of Transport Statistics. The dataset provides historical information about internal flights in the United States and can be used to demonstrate a wide range of data science concepts and techniques. This lab provides the data as a set of CSV formatted text files.
Objectives
- Create a training dataset for machine learning using Spark
- Develop a logistic regression machine learning model using Spark
- Evaluate the predictive behavior of a machine learning model using Spark on Dataproc
- Evaluate the model
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Task 1. Create a Dataproc cluster
Normally, the first step in writing Hadoop jobs is to get a Hadoop installation going. This involves setting up a cluster, installing Hadoop on it, and configuring the cluster so that the machines all know about one another and can communicate with one another in a secure manner.
Then, you’d start the YARN and MapReduce processes and finally be ready to write some Hadoop programs. On Google Cloud, Dataproc makes it convenient to spin up a Hadoop cluster that is capable of running MapReduce, Pig, Hive, Presto, and Spark.
If you are using Spark, Dataproc offers a fully managed, serverless Spark environment – you simply submit a Spark program and Dataproc executes it. In this way, Dataproc is to Apache Spark what Dataflow is to Apache Beam. In fact, Dataproc and Dataflow share backend services.
In this section you create a VM and then a Dataproc cluster on the VM.
-
In the Cloud Console, on the Navigation menu (
), click Compute Engine > VM instances.
-
Click the SSH button next to
startup-vmVM to launch a terminal and connect. -
Click Connect to confirm the SSH connection.
-
Run following command to clone the repository
data-science-on-gcp, and navigate to the directory06_dataproc:
- Set the project and bucket variable using the following code:
- Edit the
create_cluster.shfile by removing the zonal dependency code--zone ${REGION}-a
Your output should similar to the following:
-
Save file by using Ctrl+X press Y and enter
-
Create a Dataproc cluster to run jobs on, specifying the name of your bucket and the region that the bucket is in:
This command may take a few minutes.
JupyterLab on Dataproc
-
In the Cloud Console, on the Navigation menu, click Dataproc. You may have to click More Products and scroll down.
-
In the Cluster list, click on the cluster name to view cluster details.
-
Click the Web Interfaces tab and then click JupyterLab towards the bottom of the right pane.
-
In the Notebook launcher section click Python 3 to open a new notebook.
To use a Notebook you enter commands into a cell. Be sure you run the commands in the cell by either pressing Shift + Enter, or clicking the triangle on the Notebook top menu to Run selected cells and advance.
Task 2. Set up bucket and start pyspark session
- Set up a google cloud storage bucket where your raw files are hosted:
- Run the cell by either pressing Shift + Enter, or clicking the triangle on the Notebook top menu to Run selected cells and advance.
- Create a spark session using the following code block:
Once that code is added at the start of any Spark Python script, any code developed using the interactive Spark shell or Jupyter notebook will also work when launched as a standalone script.
Create a Spark Dataframe for training
- Enter the following commands into new cell:
- Run the cell.
Task 3. Read and clean up dataset
When you launched this lab, an automated script provided data to you as a set of prepared CSV files and was placed into your Cloud Storage bucket.
- Now, fetch the Cloud Storage bucket name from the environment variable you set earlier and create the
traindaysDataFrame by reading in a prepared CSV that the automated script puts into your Cloud Storage bucket.
The CSV identifies a subset of days as valid for training. This allows you to create views of the entire flights dataset which is divided into a dataset used for training your model and a dataset used to test or validate that model.
Read the dataset
- Enter and run the following commands into the new cell:
- Create a Spark SQL view:
- Query the first few records from the training dataset view:
This displays the first five records in the training table:

The next stage in the process is to identify the source data files.
- You will use the
all_flights-00000-*shard file for this, as it has a representative subset of the full dataset and can be processed in a reasonable amount of time:
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
- Now read the data into Spark SQL from the input file you created:
- Next, create a query that uses data only from days identified as part of the training dataset:
- Inspect some of the data to see if it looks correct:
"Truncated the string representation of a plan since it was too large." For this lab, ignore it as it's only relevant if you want to inspect SQL schema logs. Your output should be something similar to the following:
- Ask Spark to provide some analysis of the dataset:
This should output something similar to the following:
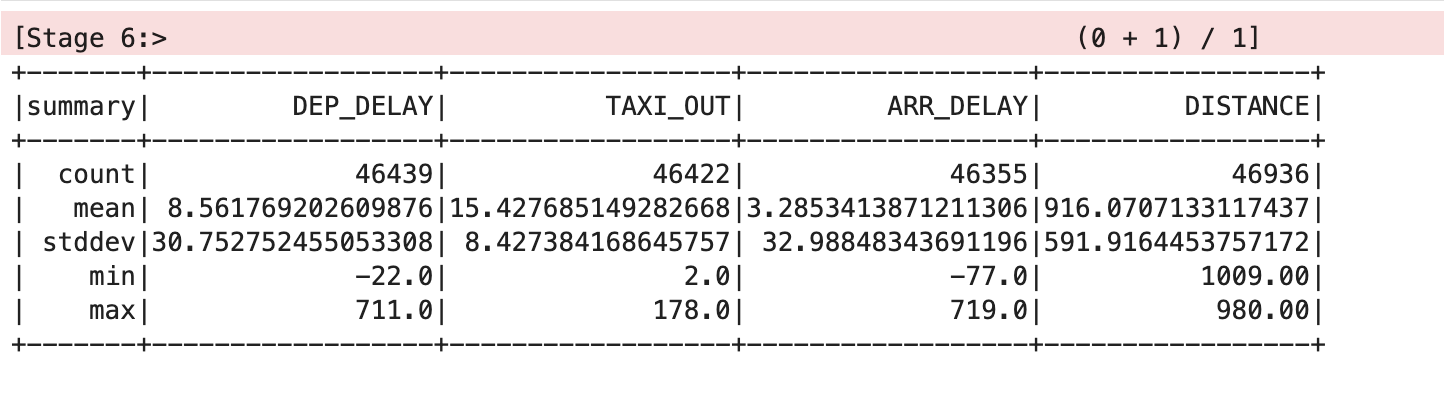
Clean the dataset
The mean and standard deviation values have been rounded to two decimal places for clarity in this table, but you will see the full floating point values on screen.
The table shows that there are some issues with the data. Not all of the records have values for all of the variables, there are different count stats for DEP_DELAY, TAXI_OUT, ARR_DELAY and DISTANCE. This happens because:
- Flights are scheduled but never depart
- Some depart but are cancelled before take off
- Some flights are diverted and therefore never arrive
- Enter following code in new cell:
trainquery = """ SELECT DEP_DELAY, TAXI_OUT, ARR_DELAY, DISTANCE FROM flights f JOIN traindays t ON f.FL_DATE == t.FL_DATE WHERE t.is_train_day == 'True' AND f.dep_delay IS NOT NULL AND f.arr_delay IS NOT NULL """ traindata = spark.sql(trainquery) traindata.describe().show()
This should output something similar to the following:
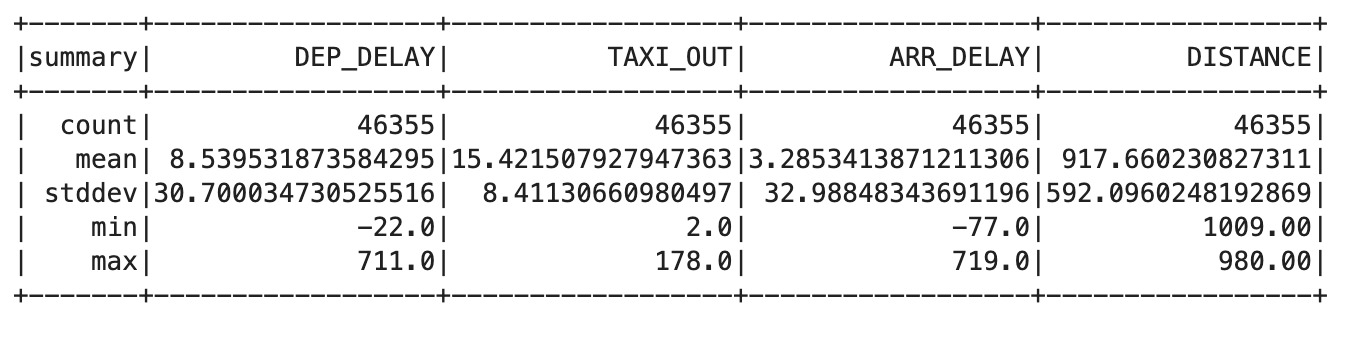
- Remove flights that have been cancelled or diverted using the following query:
This output should show the same count value for each column, which indicates that you fixed the problem.
Task 4. Develop a logistic regression model
Now you can create a function that converts a set of data points in your DataFrame into a training example. A training example contains a sample of the input features and the correct answer for those inputs.
In this case, you answer whether the arrival delay is less than 15 minutes. The labels you use as inputs are the values for departure delay, taxi out time, and flight distance.
- Enter and run the following into the new cell to create the definition for the training example function:
- Map this training example function to the training dataset:
- Enter and run the following command to provide a training DataFrame for the Spark logistic regression module:
The training DataFrame creates a logistic regression model based on your training dataset.
- Use the
intercept=Trueparameter because the prediction for arrival delay does not equal zero when all of the inputs are zero in this case. - If you have a training dataset where you expect that a prediction should be zero when the inputs are all zero, then you would specify
intercept=False.
- When this train method finishes, the
lrmodelobject will have weights and an intercept value that you can inspect:
The output looks similar to the following:
These weights, when used with the formula for linear regression, allow you to create a model using code in the language of your choice.
- Test this by providing some input variables for a flight that has:
- A departure delay of 6 minutes
- A taxi-out time of 12 minutes
- A flight distance of 594 miles
The result of 1 predicts the flight will be on time.
- Now try it with a much longer departure delay of 36 minutes:
The result of 0 predicts the flight won't be on time.
These results are not probabilities; they are returned as either true or false based on a threshold which is set by default to 0.5.
- You can return the actual probability by clearing the threshold:
Notice the results are probabilities, with the first close to 1 and the second close to 0.
- Set the threshold to 0.7 to correspond to your requirement to be able to cancel meetings if the probability of an on time arrival falls below 70%:
Your outputs are once again 1 and 0, but now they reflect the 70% probability threshold that you require and not the default 50%.
Task 5. Save and restore a logistic regression model
You can save a Spark logistic regression model directly to Cloud Storage. This allows you to reuse a model without having to retrain the model from scratch.
A storage location contains only one model. This avoids interference with other existing files which would cause model loading issues. To do this, make sure your storage location is empty before you save your Spark regression model.
- Enter the following code in new cell and run:
This should report an error stating CommandException: 1 files/objects could not be removed because the model has not been saved yet. The error indicates that there are no files present in the target location. You must be certain that this location is empty before attempting to save the model and this command guarantees that.
- Save the model by running:
- Now destroy the model object in memory and confirm that it no longer contains any model data:
- Now retrieve the model from storage:
The model parameters, i.e. the weights and intercept values, have been restored.
Task 6. Predict with the logistic regression model
- Test the model with a scenario that will definitely not arrive on time:
This prints out 0, predicting the flight will probably arrive late, given your 70% probability threshold.
- Finally, retest the model using data for a flight that should arrive on time:
This prints out 1, predicting that the flight will probably arrive on time, given your 70% probability threshold.
Task 7. Examine model behavior
- Enter the following code into a new cell and run the cell:
With the thresholds removed, you get probabilities. The probability of arriving late increases as the departure delay increases.
- At a departure delay of 20 minutes and a taxi-out time of 10 minutes, this is how the distance affects the probability that the flight is on time:
As you can see, the effect is relatively minor. The probability increases from about 0.63 to about 0.76 as the distance changes from a very short hop to a cross-continent flight.
- Run the following in new cell:
On the other hand, if you hold the taxi-out time and distance constant and examine the dependence on departure delay, you see a more dramatic impact.
Task 8. Evaluate the model
- To evaluate the logistic regression model, you need test data:
- Now map this training example function to the testing dataset:
- Ask Spark to provide some analysis of the dataset:
This should output something similar to the following:

- Define a
evalfunction and return total cancel, total noncancel, correct cancel and correct noncancel flight details:
- Now, evaluate the model by passing correct predicted label:
Output:
- Keep only those examples near the decision threshold which is greater than 65% and less than 75%:
Output:
Congratulations!
Now you know how to use Spark to perform logistic regression with a Dataproc cluster.
Take your next lab
Continue with:
Next steps / learn more
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated December 04, 2023
Lab Last Tested December 04, 2023
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.