Points de contrôle
Create Cloud Dataproc cluster
/ 50
Create a Logistic Regression Model
/ 50
Machine learning avec Spark sur Google Cloud Dataproc
- GSP271
- Présentation
- Préparation
- Tâche 1 : Créer un cluster Dataproc
- Tâche 2 : Configurer un bucket et lancer une session PySpark
- Tâche 3 : Lire et nettoyer l'ensemble de données
- Tâche 4 : Développer un modèle de régression logistique
- Tâche 5 : Enregistrer et restaurer un modèle de régression logistique
- Tâche 6 : Générer des prédictions avec le modèle de régression logistique
- Tâche 7 : Examiner le comportement du modèle
- Tâche 8 : Évaluer le modèle
- Félicitations !
GSP271

Présentation
Introduction
Dans cet atelier, vous allez implémenter une régression logistique à l'aide d'une bibliothèque de machine learning pour Apache Spark. Spark sera exécuté sur un cluster Dataproc. L'objectif est de développer un modèle applicable à un ensemble de données multivariable.
Dataproc est un service cloud rapide, convivial et entièrement géré qui vous permet d'exécuter des clusters Apache Spark et Apache Hadoop de manière simple et économique. Dataproc s'intègre facilement à d'autres services Google Cloud. Vous bénéficiez ainsi d'une plate-forme performante et complète pour vos tâches de traitement des données, d'analyse et de machine learning.
Apache Spark est un moteur d'analyse pour les tâches de traitement des données à grande échelle. La régression logistique est disponible sous forme de module dans la bibliothèque de machine learning d'Apache Spark, MLlib. La bibliothèque Spark MLlib, également appelée Spark ML, comprend des implémentations de la plupart des algorithmes de machine learning standard, comme le clustering en k-moyennes, les forêts d'arbres décisionnels, les moindres carrés alternés, les arbres de décision, les machines à vecteurs de support, etc. Spark peut s'exécuter sur un cluster Hadoop, tel que Dataproc, afin de traiter des ensembles de données très volumineux en parallèle.
Cet atelier utilise un ensemble de données fourni par le Bureau des statistiques du transport américain (US Bureau of Transports Statistics). Cet ensemble de données, qui comporte des informations historiques sur les vols intérieurs aux États-Unis, s'avère utile pour présenter de nombreux concepts et techniques de science des données. Dans le cadre de cet atelier, les données vous sont fournies sous la forme d'un ensemble de fichiers texte au format CSV.
Objectifs
- Créer un ensemble de données d'entraînement pour le machine learning à l'aide de Spark
- Développer un modèle de machine learning de régression logistique avec Spark
- Évaluer le comportement prédictif d'un modèle de machine learning à l'aide de Spark sur Dataproc
- Évaluer le modèle
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Tâche 1 : Créer un cluster Dataproc
Normalement, la première étape de l'écriture de jobs Hadoop consiste à déployer une installation Hadoop. Cela implique de configurer un cluster, d'y installer Hadoop et de configurer le cluster pour que les machines se connaissent toutes et puissent communiquer entre elles de manière sécurisée.
Il faut ensuite lancer les processus YARN et MapReduce, avant d'écrire les programmes Hadoop requis. En utilisant Dataproc sur Google Cloud, vous pouvez lancer facilement un cluster Hadoop capable d'exécuter MapReduce, Pig, Hive, Presto et Spark.
Si vous utilisez Spark, Dataproc propose un environnement Spark sans serveur et entièrement géré : il vous suffit d'envoyer un programme Spark et Dataproc l'exécute. Ainsi, Dataproc est à Apache Spark ce que Dataflow est à Apache Beam. De fait, Dataproc et Dataflow ont les mêmes services de backend.
Dans cette section, vous allez créer une machine virtuelle, puis y créer un cluster Dataproc.
-
Dans la console Cloud, accédez au menu de navigation (
), puis cliquez sur Compute Engine > Instances de VM.
-
Cliquez sur le bouton SSH à côté de la VM
startup-vmpour lancer un terminal et établir une connexion. -
Cliquez sur Connecter pour confirmer la connexion SSH.
-
Exécutez la commande suivante pour cloner le dépôt
data-science-on-gcpet accéder au répertoire06_dataproc:
- Définissez le projet et la variable du bucket à l'aide du code suivant :
- Modifiez le fichier
create_cluster.shen supprimant le code de la dépendance zonale--zone ${REGION}-a
Vous devez obtenir un résultat semblable à ce qui suit :
-
Enregistrez le fichier à l'aide de Ctrl+X. Appuyez sur Y et saisissez ce qui suit :
-
Créez un cluster Dataproc pour y exécuter des jobs. Vous devez préciser le nom du bucket et la région dans laquelle il se trouve :
L'exécution de cette commande peut prendre quelques minutes.
JupyterLab sur Dataproc
-
Dans la console Cloud, accédez au menu de navigation, puis cliquez sur Dataproc. Vous devrez peut-être cliquer sur Plus de produits et faire défiler la liste vers le bas.
-
Dans la liste des clusters, cliquez sur le nom du cluster pour en afficher les détails.
-
Cliquez sur l'onglet Interfaces Web, puis cliquez sur JupyterLab au bas du volet de droite.
-
Dans la section de lancement de Notebooks, cliquez sur Python 3 pour ouvrir un nouveau notebook.
Pour utiliser un notebook, vous devez saisir des commandes dans une cellule. Veillez à exécuter les commandes de la cellule. Pour ce faire, appuyez sur Maj + Entrée ou cliquez sur l'icône triangulaire dans le menu supérieur du notebook afin d'exécuter les cellules sélectionnées et de passer à la cellule suivante.
Tâche 2 : Configurer un bucket et lancer une session PySpark
- Configurez un bucket Google Cloud Storage dans lequel vos fichiers bruts seront hébergés :
- Pour exécuter le code de la cellule, appuyez sur Maj + Entrée ou cliquez sur l'icône triangulaire dans le menu supérieur du notebook afin d'exécuter les cellules sélectionnées et de passer à la cellule suivante.
- Créez une session Spark à l'aide du bloc de code suivant :
Une fois ce code ajouté au début d'un script Python pour Spark, le code développé à l'aide du shell interactif Spark ou du notebook Jupyter fonctionnera aussi s'il est lancé sous la forme d'un script autonome.
Créer un DataFrame Spark pour l'entraînement
- Saisissez les commandes suivantes dans la nouvelle cellule :
- Exécutez le code de la cellule.
Tâche 3 : Lire et nettoyer l'ensemble de données
Quand vous avez démarré cet atelier, un script automatisé vous a fourni des données sous la forme d'un ensemble de fichiers CSV préparés et les a placés dans votre bucket Cloud Storage.
- À présent, récupérez le nom du bucket Cloud Storage à partir de la variable d'environnement que vous avez définie précédemment et créez le DataFrame
traindaysen lisant un fichier CSV préparé que le script automatisé place dans le bucket Cloud Storage.
Ce fichier CSV identifie un sous-ensemble de jours comme valide pour l'entraînement. Cela vous permet de créer des vues de la totalité de l'ensemble de données flights, qui est divisé en deux ensembles de données : le premier sert à entraîner votre modèle, et le second, à tester ou valider ce modèle.
Lire l'ensemble de données
- Saisissez et exécutez les commandes suivantes dans la nouvelle cellule :
- Créez une vue Spark SQL :
- Interrogez les premiers enregistrements de la vue de l'ensemble de données d'entraînement :
Cette commande affiche les cinq premiers enregistrements de la table d'entraînement :

L'étape suivante du processus consiste à identifier les fichiers de données sources.
- Pour ce faire, vous utiliserez le fichier de partition
all_flights-00000-*, car il comporte un sous-ensemble représentatif de l'ensemble de données complet et peut être traité dans un délai raisonnable :
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
- À présent, lisez les données du fichier d'entrée que vous avez créé dans Spark SQL :
- Ensuite, créez une requête impliquant uniquement les données des jours identifiés comme faisant partie de l'ensemble de données d'entraînement :
- Inspectez certaines des données pour vérifier qu'elles sont correctes :
"Truncated the string representation of a plan since it was too large." (La représentation sous forme de chaîne d'un plan a été tronquée, car elle était trop étendue). Vous pouvez ignorer ce message pendant cet atelier, car il n'est pertinent que si vous voulez inspecter les journaux de schéma SQL. Vous devez obtenir un résultat semblable à celui-ci :
- Demandez à Spark d'analyser l'ensemble de données :
Vous devez obtenir un résultat semblable à celui-ci :
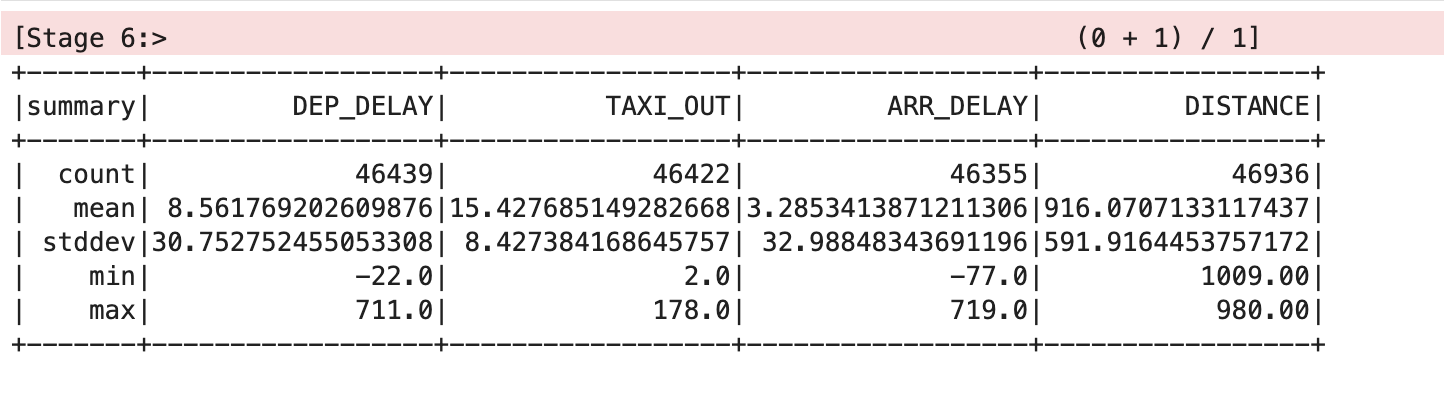
Nettoyer l'ensemble de données
Pour plus de clarté, les valeurs de moyenne et d'écart-type figurant dans cette table ont été arrondies à deux décimales, mais vous verrez les valeurs à virgule flottante complètes à l'écran.
Cette table vous indique que certaines données posent problème. Diverses variables de certains enregistrements sont dépourvues de valeur, et il existe des statistiques de comptabilisation différentes pour DEP_DELAY, TAXI_OUT, ARR_DELAY et DISTANCE. Cette situation se produit pour les raisons suivantes :
- Certains vols étaient planifiés, mais n'ont jamais pris le départ.
- Certains vols ont pris le départ, mais ont été annulés avant le décollage.
- Certains vols ont été déroutés et ne sont donc jamais arrivés.
- Saisissez le code suivant dans une nouvelle cellule :
trainquery = """ SELECT DEP_DELAY, TAXI_OUT, ARR_DELAY, DISTANCE FROM flights f JOIN traindays t ON f.FL_DATE == t.FL_DATE WHERE t.is_train_day == 'True' AND f.dep_delay IS NOT NULL AND f.arr_delay IS NOT NULL """ traindata = spark.sql(trainquery) traindata.describe().show()
Vous devez obtenir un résultat semblable à celui-ci :
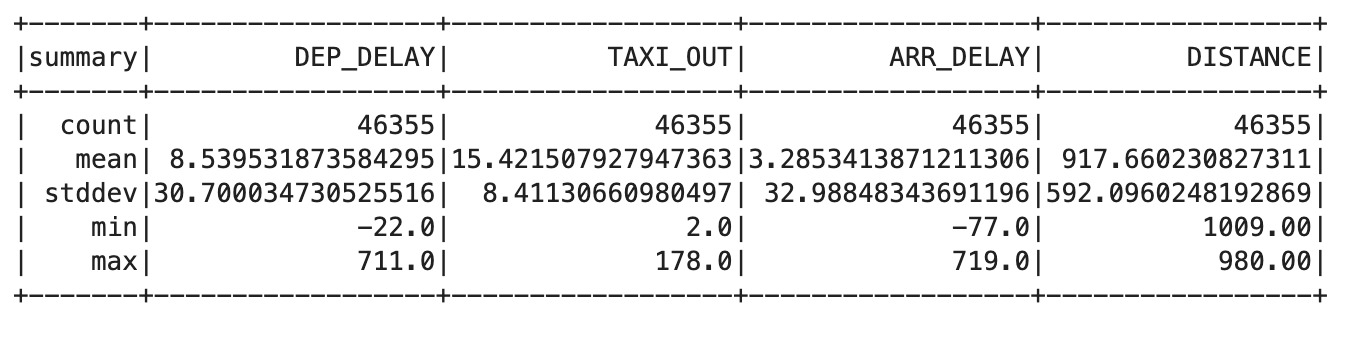
- Supprimez les vols qui ont été annulés ou déroutés à l'aide de la requête suivante :
Dans ce résultat, la même valeur doit s'afficher pour chaque colonne. Cela indique que vous avez résolu le problème.
Tâche 4 : Développer un modèle de régression logistique
Vous pouvez maintenant créer une fonction qui convertit un ensemble de points de données de votre DataFrame en exemple d'entraînement. Un exemple d'entraînement contient un échantillon des caractéristiques d'entrée et la réponse correcte qui leur est associée.
Dans ce cas précis, vous indiquez si le retard à l'arrivée est inférieur à 15 minutes ou non. Les libellés que vous utilisez comme entrées correspondent aux valeurs des champs departure delay, taxi out time et flight distance.
- Saisissez et exécutez le code suivant dans la nouvelle cellule pour créer la définition de la fonction d'exemple d'entraînement :
- Mappez cette fonction d'exemple d'entraînement sur l'ensemble de données d'entraînement :
- Saisissez et exécutez la commande suivante pour fournir un DataFrame d'entraînement pour le module de régression logistique Spark :
Le DataFrame d'entraînement crée un modèle de régression logistique basé sur votre ensemble de données d'entraînement.
- Utilisez le paramètre
intercept=True, car dans notre exemple, la prédiction du retard à l'arrivée diffère de zéro lorsque toutes les entrées sont égales à zéro. - Si vous disposez d'un ensemble de données d'entraînement pour lequel une prédiction doit être égale à zéro lorsque toutes les entrées présentent la valeur zéro, vous devez spécifier le paramètre
intercept=False.
- À la fin de cette méthode d'entraînement, l'objet
lrmodelcomportera des pondérations et une valeur d'interception que vous pourrez inspecter :
Le résultat ressemble à ceci :
Quand vous utilisez ces pondérations avec la formule de régression linéaire, vous pouvez créer un modèle dans le langage de programmation de votre choix.
- Testez cela en fournissant certaines variables d'entrée pour un vol présentant :
- un retard au départ de 6 minutes ;
- un roulage au départ de 12 minutes ;
- une distance de vol de 594 miles (955 km).
Nous obtenons un résultat de 1, ce qui signifie que le vol devrait être à l'heure.
- Effectuons maintenant un autre test en spécifiant un retard au départ de 36 minutes.
Nous obtenons un résultat de 0, indiquant que le vol sera probablement en retard.
Ces résultats ne constituent pas des probabilités ; ils sont renvoyés sous la forme d'une valeur "true" (vrai) ou "false" (faux) en fonction d'un seuil défini par défaut sur 0.5.
- Vous pouvez obtenir la probabilité réelle en supprimant ce seuil :
Notez que les résultats correspondent à des probabilités, le premier s'approchant de 1, et le second, de 0.
- Définissez le seuil sur 0.7 pour permettre l'annulation de réunions si la probabilité d'une arrivée à l'heure passe en dessous de 70 %.
Là encore, les résultats obtenus sont de 1 et 0, mais ils reflètent à présent le seuil de probabilité de 70 % conforme à vos exigences, et non plus le seuil par défaut de 50 %.
Tâche 5 : Enregistrer et restaurer un modèle de régression logistique
Vous pouvez enregistrer un modèle de régression logistique Spark directement dans Cloud Storage. Cela vous permet de réutiliser un modèle sans avoir besoin de le ré-entraîner entièrement.
Un emplacement de stockage ne contient qu'un modèle. Cela permet d'éviter toute interférence avec d'autres fichiers existants, qui entraînerait des problèmes de chargement du modèle. Pour cela, assurez-vous que votre emplacement de stockage est vide avant d'enregistrer votre modèle de régression Spark.
- Saisissez le code suivant dans une nouvelle cellule et exécutez-le :
Vous devez recevoir le message d'erreur CommandException: 1 files/objects could not be removed (Exception de commande : impossible de supprimer 1 fichier/objet), car le modèle n'a pas encore été enregistré. Cette erreur signale que l'emplacement cible ne comporte aucun fichier. Vous devez vous assurer que cet emplacement est vide avant d'essayer d'enregistrer le modèle. C'est précisément ce que cette commande vous permet de faire.
- Enregistrez le modèle en exécutant la commande suivante :
- Maintenant, détruisez l'objet de modèle en mémoire et vérifiez que la mémoire ne contient plus aucune donnée de modèle :
- À présent, récupérez le modèle à partir de l'espace de stockage :
Les paramètres du modèle, c'est-à-dire les pondérations et les valeurs d'interception, ont été restaurés.
Tâche 6 : Générer des prédictions avec le modèle de régression logistique
- Testez le modèle sur les données d'un vol qui arrivera immanquablement en retard :
Vous obtenez la valeur 0, ce qui prédit que le vol arrivera probablement en retard, compte tenu de votre seuil de probabilité de 70 %.
- Pour finir, testez de nouveau le modèle sur les données d'un vol qui devrait arriver à l'heure :
Vous obtenez la valeur 1, ce qui prédit que le vol arrivera probablement à l'heure, compte tenu de votre seuil de probabilité de 70 %.
Tâche 7 : Examiner le comportement du modèle
- Saisissez le code suivant dans une nouvelle cellule et exécutez-le :
Une fois les seuils supprimés, vous obtenez des probabilités. La probabilité d'un retard à l'arrivée augmente à mesure que le retard au départ augmente.
- Pour un retard au départ de 20 minutes et un roulage au départ de 10 minutes, voici comment la distance affecte la probabilité que le vol soit à l'heure :
Comme vous pouvez le constater, l'effet est relativement mineur. La probabilité passe d'environ 0,63 à environ 0,76 quand la distance passe d'un vol très court à un vol transcontinental.
- Exécutez la commande suivante dans une nouvelle cellule :
En revanche, si vous maintenez constants le roulage au départ et la distance, vous constatez qu'un retard au départ a beaucoup plus d'impact.
Tâche 8 : Évaluer le modèle
- Pour évaluer le modèle de régression logistique, vous avez besoin de données de test :
- À présent, mappez cette fonction d'exemple d'entraînement sur l'ensemble de données d'entraînement :
- Demandez à Spark d'analyser l'ensemble de données :
Vous devez obtenir un résultat semblable à celui-ci :

- Définissez une fonction
evalpour afficher le nombre total de vols annulés, le nombre total de vols non annulés, ainsi que des détails sur les vols correctement annulés et les vols correctement non annulés :
- À présent, évaluez le modèle en transmettant la bonne étiquette prédite :
Résultat :
- Ne conservez que les exemples proches du seuil de décision, qui est supérieur à 65 % et inférieur à 75 % :
Résultat :
Félicitations !
Vous savez désormais utiliser Spark pour effectuer une régression logistique à l'aide d'un cluster Dataproc.
Atelier suivant
Continuez avec :
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 4 décembre 2023
Dernier test de l'atelier : 4 décembre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.