GSP273

Visão geral
Neste laboratório, você vai criar uma instância do Vertex AI Workbench e desenvolver nela um modelo do TensorFlow em um notebook Jupyter. Você vai treinar o modelo, criar um pipeline de dados de entrada, implantar o pipeline em um endpoint e receber previsões.
O TensorFlow é uma plataforma completa de código aberto para machine learning. Ele tem um ecossistema abrangente e flexível de ferramentas, bibliotecas e recursos da comunidade, para que pesquisadores aperfeiçoem ML de última geração e desenvolvedores criem e implantem aplicativos com tecnologia de ML.
A Vertex AI une o AutoML e o AI Platform em uma API, uma biblioteca de cliente e uma interface de usuário unificadas. Com a Vertex AI, tanto o treinamento do AutoML quanto o treinamento personalizado estão disponíveis.
Com o Vertex AI Workbench, os usuários criam de modo rápido fluxos de trabalho completos com notebooks, por meio da integração entre serviços de dados (como Dataproc, Dataflow, BigQuery e Dataplex) e a Vertex AI. Cientistas de dados usam o Workbench para acessar serviços de dados do Google Cloud, analisar conjuntos de dados, testar diferentes técnicas de modelagem, implantar modelos treinados na produção e gerenciar MLOps durante o ciclo de vida do modelo.
O Vertex AI Workbench é um ambiente de desenvolvimento único para todo o fluxo de trabalho de ciência de dados.
No laboratório, usamos um conjunto de exemplos de código e scripts desenvolvidos para o livro Data Science on Google Cloud Platform, 2a edição, da O'Reilly Media, Inc.
Objetivos
- Implantar uma instância do Vertex AI Workbench
- Criar dados mínimos de treinamento e de validação
- Criar o pipeline de dados de entrada
- Criar um modelo do TensorFlow
- Implantar o modelo na Vertex AI
- Implantar o modelo da Explainable AI na Vertex AI
- Fazer previsões no endpoint do modelo
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
Observação: para executar este laboratório, use o modo de navegação anônima ou uma janela anônima do navegador. Isso evita conflitos entre sua conta pessoal e a conta de estudante, o que poderia causar cobranças extras na sua conta pessoal.
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Observação: não use seu projeto ou conta do Google Cloud neste laboratório para evitar cobranças extras na sua conta.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento.
No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google.
O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta.
-
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina.
Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais.
-
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.
Observação: para ver uma lista dos produtos e serviços do Google Cloud, clique no Menu de navegação no canto superior esquerdo.

Tarefa 1: implantar uma instância do Vertex AI Workbench
-
No menu de navegação do console do Google Cloud, clique em Vertex AI > Workbench.
-
Clique em + Criar nova.
-
Na caixa de diálogo Criar instância, use o nome padrão ou insira um exclusivo para a instância do Vertex AI Workbench. Defina a região como e a zona como . Mantenha a opção padrão no resto das configurações.
-
Clique em Criar.
-
Clique em Abrir o JupyterLab.
Para usar um notebook, digite comandos em uma célula. Para executar os comandos na célula, pressione Shift + Enter ou clique no triângulo no menu superior "Notebook" para executar células selecionadas e avançar.
Implante uma instância do Vertex AI Workbench
Tarefa 2: criar dados mínimos de treinamento e de validação
- Na seção de acesso rápido Notebook, clique em Python 3 para abrir um novo notebook.
- Importe bibliotecas Python e defina as variáveis de ambiente:
import os, json, math, shutil
import numpy as np
import tensorflow as tf
!sudo apt install graphviz -y
# environment variables used by bash cells
PROJECT=!(gcloud config get-value project)
PROJECT=PROJECT[0]
REGION = '{{{project_0.default_region}}}'
BUCKET='{}-dsongcp'.format(PROJECT)
os.environ['ENDPOINT_NAME'] = 'flights'
os.environ['BUCKET'] = BUCKET
os.environ['REGION'] = REGION
os.environ['TF_VERSION']='2-' + tf.__version__[2:4]
Observação:
ao colar comandos em uma célula de um notebook Jupyter, lembre-se de executar a célula para garantir que o último comando em qualquer sequência seja executado, antes de prosseguir com a etapa seguinte.
Você pode ignorar qualquer aviso de carregamento da biblioteca do TensorRT ou do TensorFlow AVX2 FMA.
Exporte os arquivos que contêm dados de treinamento e de validação
Quando o laboratório é ativado, algumas tabelas são criadas no conjunto de dados do BigQuery. Nesta seção, você vai usar o BigQuery para criar tabelas temporárias que contêm os dados necessários e vai exportar a tabela para arquivos CSV no Google Cloud Storage. Depois você vai excluir a tabela temporária. Em seguida, você vai ler e processar os arquivos de dados CSV para criar os conjuntos de dados completo, de treinamento e de validação necessários para um modelo personalizado do TensorFlow.
- Crie o conjunto de dados de treinamento
flights_train_data para treinar o modelo:
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_train_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False AND
is_train_day = 'True'
- Crie o conjunto de dados de avaliação
flights_eval_data para avaliar o modelo:
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_eval_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False AND
is_train_day = 'False'
- Crie o conjunto de dados completo
flights_all_data usando este código:
%%bigquery
CREATE OR REPLACE TABLE dsongcp.flights_all_data AS
SELECT
IF(arr_delay < 15, 1.0, 0.0) AS ontime,
dep_delay,
taxi_out,
distance,
origin,
dest,
EXTRACT(hour FROM dep_time) AS dep_hour,
IF (EXTRACT(dayofweek FROM dep_time) BETWEEN 2 AND 6, 1, 0) AS is_weekday,
UNIQUE_CARRIER AS carrier,
dep_airport_lat,
dep_airport_lon,
arr_airport_lat,
arr_airport_lon,
IF (is_train_day = 'True',
IF(ABS(MOD(FARM_FINGERPRINT(CAST(f.FL_DATE AS STRING)), 100)) < 60, 'TRAIN', 'VALIDATE'),
'TEST') AS data_split
FROM dsongcp.flights_tzcorr f
JOIN dsongcp.trainday t
ON f.FL_DATE = t.FL_DATE
WHERE
f.CANCELLED = False AND
f.DIVERTED = False
- Exporte os conjuntos de dados completo, de treinamento e de validação para o formato de arquivo CSV no bucket do Google Cloud Storage:
Isso vai levar cerca de 2 minutos.
- Aguarde até surgir o resultado do script bash abaixo na célula do notebook:
%%bash
PROJECT=$(gcloud config get-value project)
for dataset in "train" "eval" "all"; do
TABLE=dsongcp.flights_${dataset}_data
CSV=gs://${BUCKET}/ch9/data/${dataset}.csv
echo "Exporting ${TABLE} to ${CSV} and deleting table"
bq --project_id=${PROJECT} extract --destination_format=CSV $TABLE $CSV
bq --project_id=${PROJECT} rm -f $TABLE
done
- Liste os objetos exportados para o bucket do Google Cloud Storage com este código:
!gsutil ls -lh gs://{BUCKET}/ch9/data
Crie os conjuntos de dados de treinamento e de validação
Tarefa 3: criar os dados de entrada
Configuração no notebook
- Para desenvolvimento, treine para alguns períodos. É por isso que NUM_EXAMPLES é tão baixo.
DEVELOP_MODE = True
NUM_EXAMPLES = 5000*1000
- Atribua os URIs
training_data_uri e validation_data_uri aos conjuntos de dados de treinamento e de validação respectivamente:
training_data_uri = 'gs://{}/ch9/data/train*'.format(BUCKET)
validation_data_uri = 'gs://{}/ch9/data/eval*'.format(BUCKET)
- Configure os parâmetros do modelo com este bloco de código:
NBUCKETS = 5
NEMBEDS = 3
TRAIN_BATCH_SIZE = 64
DNN_HIDDEN_UNITS = '64,32'
Como inserir os dados no TensorFlow
- Para inserir os arquivos CSV do Google Cloud Storage no TensorFlow, use um método do pacote
tf.data:
if DEVELOP_MODE:
train_df = tf.data.experimental.make_csv_dataset(training_data_uri, batch_size=5)
for n, data in enumerate(train_df):
numpy_data = {k: v.numpy() for k, v in data.items()}
print(n, numpy_data)
if n==1: break
Escreva as funções features_and_labels() e read_dataset(). A função read_dataset() lê os dados de treinamento, gerando exemplos de batch_size a cada vez, e interrompe a iteração depois de ler determinado número de exemplos.
O conjunto de dados contém todas as colunas do arquivo CSV, nomeadas de acordo com a linha de cabeçalho. Os dados consistem em atributos e rótulos. É melhor separar esses elementos por meio da função features_and_labels(), para facilitar a leitura do código. Por isso, vamos aplicar uma função pop() ao dicionário e retornar uma tupla de atributos e rótulos.
- Digite e execute este código:
def features_and_labels(features):
label = features.pop('ontime')
return features, label
def read_dataset(pattern, batch_size, mode=tf.estimator.ModeKeys.TRAIN, truncate=None):
dataset = tf.data.experimental.make_csv_dataset(pattern, batch_size, num_epochs=1)
dataset = dataset.map(features_and_labels)
if mode == tf.estimator.ModeKeys.TRAIN:
dataset = dataset.shuffle(batch_size*10)
dataset = dataset.repeat()
dataset = dataset.prefetch(1)
if truncate is not None:
dataset = dataset.take(truncate)
return dataset
if DEVELOP_MODE:
print("Checking input pipeline")
one_item = read_dataset(training_data_uri, batch_size=2, truncate=1)
print(list(one_item)) # should print one batch of 2 items
Tarefa 4: criar, treinar e avaliar o modelo do TensorFlow
Em geral, você cria um atributo para cada coluna dos dados em tabela. O Keras aceita colunas de atributos. Com isso, é possível representar dados estruturados usando técnicas comuns de engenharia de atributos como embeddings, agrupamento por classes e cruzamentos.
Já que é possível transmitir dados numéricos diretamente ao modelo de ML, mantenha as colunas de valores reais separadas das colunas esparsas (ou de strings).
- Digite e execute este código:
import tensorflow as tf
real = {
colname : tf.feature_column.numeric_column(colname)
for colname in
(
'dep_delay,taxi_out,distance,dep_hour,is_weekday,' +
'dep_airport_lat,dep_airport_lon,' +
'arr_airport_lat,arr_airport_lon'
).split(',')
}
sparse = {
'carrier': tf.feature_column.categorical_column_with_vocabulary_list('carrier',
vocabulary_list='AS,VX,F9,UA,US,WN,HA,EV,MQ,DL,OO,B6,NK,AA'.split(',')),
'origin' : tf.feature_column.categorical_column_with_hash_bucket('origin', hash_bucket_size=1000),
'dest' : tf.feature_column.categorical_column_with_hash_bucket('dest', hash_bucket_size=1000),
}
Todos esses atributos vêm diretamente do arquivo de entrada e são informados pelo cliente que quer a previsão de um voo. As camadas de entrada têm correspondência de 1:1 com os atributos de entrada e os tipos deles. Por isso, em vez de repetir os nomes das colunas, crie uma camada de entrada para cada coluna e especifique o tipo certo de dados (ponto flutuante ou string).
- Digite e execute este código:
inputs = {
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='float32')
for colname in real.keys()
}
inputs.update({
colname : tf.keras.layers.Input(name=colname, shape=(), dtype='string')
for colname in sparse.keys()
})
Agrupamento por classes
Quando colunas de valor real têm precisão em excesso (o que poderia causar overfitting), você pode transformá-las em colunas categóricas com discretização. Por exemplo, imagine uma coluna com a idade do avião. Você pode dividir os valores em apenas três grupos: menos de 5 anos, 5 a 20 anos e mais de 20 anos. Você pode usar o atalho de discretização em latitudes e longitudes e cruzar os buckets. Assim, o país é dividido em grades, e os pontos das grades correspondem a valores específicos de latitude e longitude.
- Digite e execute este código:
latbuckets = np.linspace(20.0, 50.0, NBUCKETS).tolist() # USA
lonbuckets = np.linspace(-120.0, -70.0, NBUCKETS).tolist() # USA
disc = {}
disc.update({
'd_{}'.format(key) : tf.feature_column.bucketized_column(real[key], latbuckets)
for key in ['dep_airport_lat', 'arr_airport_lat']
})
disc.update({
'd_{}'.format(key) : tf.feature_column.bucketized_column(real[key], lonbuckets)
for key in ['dep_airport_lon', 'arr_airport_lon']
})
# cross columns that make sense in combination
sparse['dep_loc'] = tf.feature_column.crossed_column(
[disc['d_dep_airport_lat'], disc['d_dep_airport_lon']], NBUCKETS*NBUCKETS)
sparse['arr_loc'] = tf.feature_column.crossed_column(
[disc['d_arr_airport_lat'], disc['d_arr_airport_lon']], NBUCKETS*NBUCKETS)
sparse['dep_arr'] = tf.feature_column.crossed_column([sparse['dep_loc'], sparse['arr_loc']], NBUCKETS ** 4)
# embed all the sparse columns
embed = {
'embed_{}'.format(colname) : tf.feature_column.embedding_column(col, NEMBEDS)
for colname, col in sparse.items()
}
real.update(embed)
# one-hot encode the sparse columns
sparse = {
colname : tf.feature_column.indicator_column(col)
for colname, col in sparse.items()
}
if DEVELOP_MODE:
print(sparse.keys())
print(real.keys())
Treine e avalie o modelo
- Salve o checkpoint:
output_dir='gs://{}/ch9/trained_model'.format(BUCKET)
os.environ['OUTDIR'] = output_dir # needed for deployment
print('Writing trained model to {}'.format(output_dir))
- Exclua os checkpoints do modelo que já estão no bucket de armazenamento:
!gsutil -m rm -rf $OUTDIR
Como o modelo ainda não foi salvo, esta mensagem de erro vai aparecer: CommandException: 1 files/objects could not be removed. O erro indica que não há arquivos presentes no local de destino. Você precisa ter certeza de que esse local está vazio antes de salvar o modelo, e esse comando garante isso.
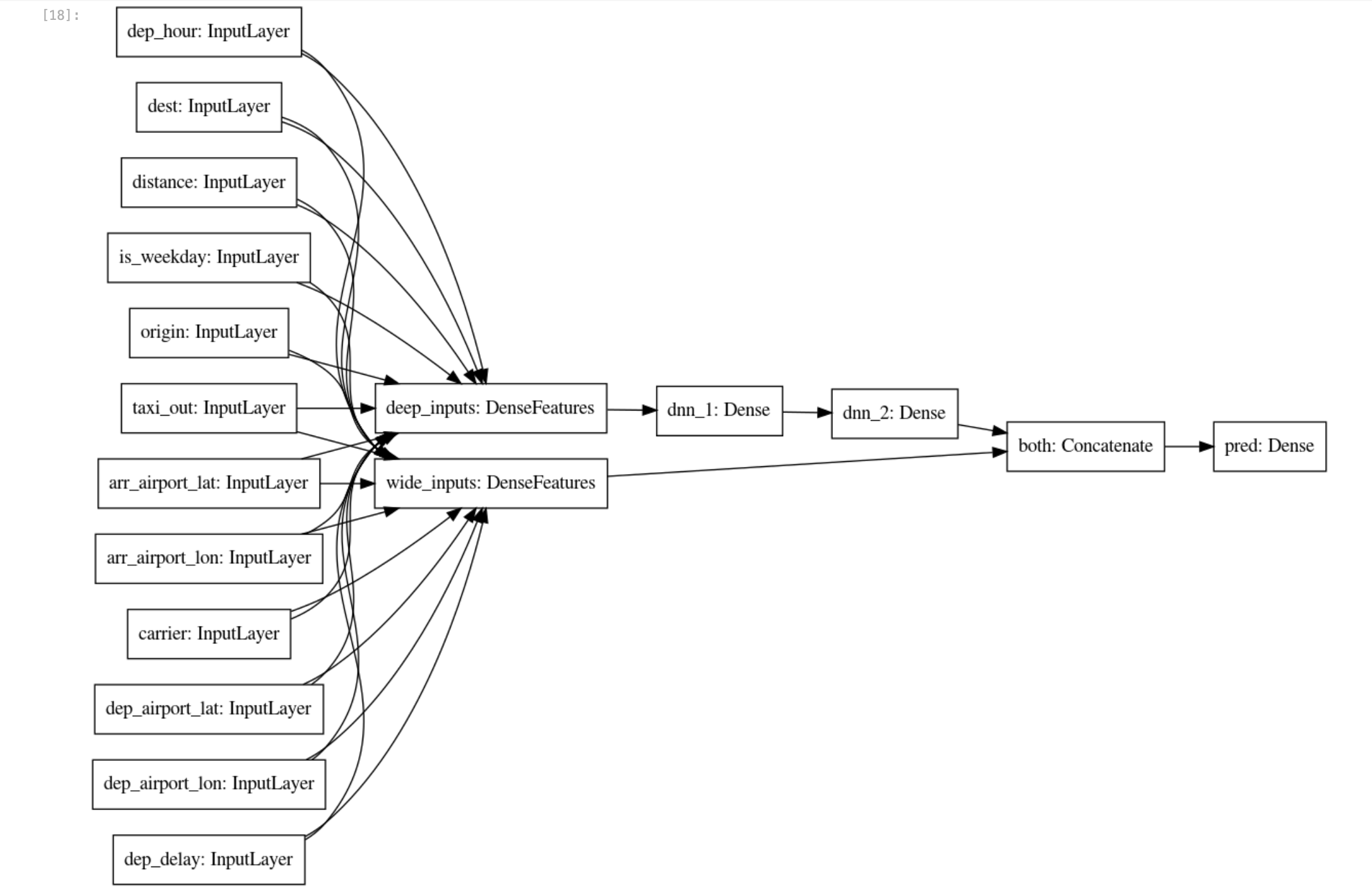
- Agora que as colunas esparsas e de atributos reais foram aprimoradas com as entradas brutas, você pode criar um
wide_and_deep_classifier para transmitir separadamente as colunas atributos lineares e profundos.
# Build a wide-and-deep model.
def wide_and_deep_classifier(inputs, linear_feature_columns, dnn_feature_columns, dnn_hidden_units):
deep = tf.keras.layers.DenseFeatures(dnn_feature_columns, name='deep_inputs')(inputs)
layers = [int(x) for x in dnn_hidden_units.split(',')]
for layerno, numnodes in enumerate(layers):
deep = tf.keras.layers.Dense(numnodes, activation='relu', name='dnn_{}'.format(layerno+1))(deep)
wide = tf.keras.layers.DenseFeatures(linear_feature_columns, name='wide_inputs')(inputs)
both = tf.keras.layers.concatenate([deep, wide], name='both')
output = tf.keras.layers.Dense(1, activation='sigmoid', name='pred')(both)
model = tf.keras.Model(inputs, output)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
model = wide_and_deep_classifier(
inputs,
linear_feature_columns = sparse.values(),
dnn_feature_columns = real.values(),
dnn_hidden_units = DNN_HIDDEN_UNITS)
tf.keras.utils.plot_model(model, 'flights_model.png', show_shapes=False, rankdir='LR')
Use train_dataset para treinamento e eval_dataset para avaliação do modelo.
- Crie o modelo com estes blocos de código:
# training and evaluation dataset
train_batch_size = TRAIN_BATCH_SIZE
if DEVELOP_MODE:
eval_batch_size = 100
steps_per_epoch = 3
epochs = 2
num_eval_examples = eval_batch_size*10
else:
eval_batch_size = 100
steps_per_epoch = NUM_EXAMPLES // train_batch_size
epochs = 10
num_eval_examples = eval_batch_size * 100
train_dataset = read_dataset(training_data_uri, train_batch_size)
eval_dataset = read_dataset(validation_data_uri, eval_batch_size, tf.estimator.ModeKeys.EVAL, num_eval_examples)
checkpoint_path = '{}/checkpoints/flights.cpt'.format(output_dir)
shutil.rmtree(checkpoint_path, ignore_errors=True)
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,
save_weights_only=True,
verbose=1)
history = model.fit(train_dataset,
validation_data=eval_dataset,
epochs=epochs,
steps_per_epoch=steps_per_epoch,
callbacks=[cp_callback])
- Visualize a perda e a acurácia do modelo usando
matplotlib.pyplot:
import matplotlib.pyplot as plt
nrows = 1
ncols = 2
fig = plt.figure(figsize=(10, 5))
for idx, key in enumerate(['loss', 'accuracy']):
ax = fig.add_subplot(nrows, ncols, idx+1)
plt.plot(history.history[key])
plt.plot(history.history['val_{}'.format(key)])
plt.title('model {}'.format(key))
plt.ylabel(key)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left');
A resposta será semelhante a:
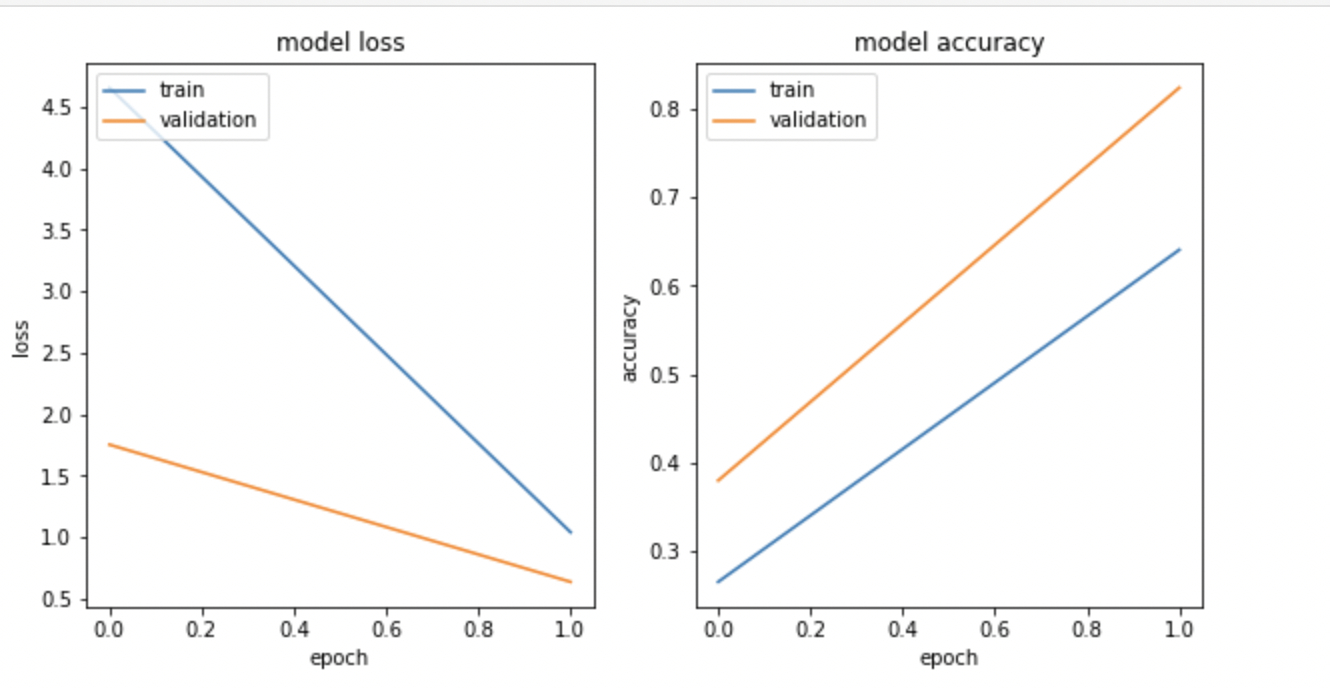
Observação: é possível que a perda do treinamento e o grafo de acurácia do modelo não coincidam porque você está treinando com uma amostra aleatória muito pequena.
Exporte o modelo treinado
- Salve os artefatos do modelo no bucket do Google Cloud Storage:
import time
export_dir = '{}/export/flights_{}'.format(output_dir, time.strftime("%Y%m%d-%H%M%S"))
print('Exporting to {}'.format(export_dir))
tf.saved_model.save(model, export_dir)
Crie o modelo do TensorFlow
Tarefa 5: implantar o modelo de voos na Vertex AI
A Vertex AI é um ambiente sem servidor e totalmente gerenciado para modelos de machine learning, com escalonamento automático. Você paga pelos recursos de computação (como CPUs ou GPUs) apenas quando os usa. O serviço faz o gerenciamento de dependências, já que os modelos são conteinerizados. Os endpoints cuidam das divisões de tráfego para você fazer testes A/B de maneira conveniente.
Há outros benefícios além de não precisar gerenciar a infraestrutura. Quando o modelo é implantado na Vertex AI, você tem acesso a vários recursos sem programação extra: explicabilidade, detecção de deslocamento, monitoramento etc.
- Crie o endpoint do modelo
flights usando a célula de código abaixo e exclua os modelos que já existem com o mesmo nome:
%%bash
# note TF_VERSION and ENDPOINT_NAME set in 1st cell
# TF_VERSION=2-6
# ENDPOINT_NAME=flights
TIMESTAMP=$(date +%Y%m%d-%H%M%S)
MODEL_NAME=${ENDPOINT_NAME}-${TIMESTAMP}
EXPORT_PATH=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $EXPORT_PATH
# create the model endpoint for deploying the model
if [[ $(gcloud beta ai endpoints list --region=$REGION \
--format='value(DISPLAY_NAME)' --filter=display_name=${ENDPOINT_NAME}) ]]; then
echo "Endpoint for $MODEL_NAME already exists"
else
echo "Creating Endpoint for $MODEL_NAME"
gcloud beta ai endpoints create --region=${REGION} --display-name=${ENDPOINT_NAME}
fi
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo "ENDPOINT_ID=$ENDPOINT_ID"
# delete any existing models with this name
for MODEL_ID in $(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME}); do
echo "Deleting existing $MODEL_NAME ... $MODEL_ID "
gcloud ai models delete --region=$REGION $MODEL_ID
done
# create the model using the parameters docker conatiner image and artifact uri
gcloud beta ai models upload --region=$REGION --display-name=$MODEL_NAME \
--container-image-uri=us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.${TF_VERSION}:latest \
--artifact-uri=$EXPORT_PATH
MODEL_ID=$(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME})
echo "MODEL_ID=$MODEL_ID"
# deploy the model to the endpoint
gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=$REGION \
--model=$MODEL_ID \
--display-name=$MODEL_NAME \
--machine-type=e2-standard-2 \
--min-replica-count=1 \
--max-replica-count=1 \
--traffic-split=0=100
Observação: ocasionalmente, um erro pode ocorrer cerca de 5 minutos neste processo. Se ocorrer um erro, por exemplo, indicando que a conta de serviço não tem permissões suficientes para gravar objetos no bucket do Google Cloud Storage, execute a célula de código de novo. Ative também a API Vertex AI, caso não esteja ativada.
Observação: vai demorar cerca de 15 a 20 minutos para criar o modelo, o endpoint do modelo e implantar o modelo no endpoint. Se você não conseguir acessar o link do endpoint gerado, ignore-o. Para conferir o progresso no seu console do Cloud, clique em Menu de navegação > Vertex AI > Previsão on-line > Endpoints.
Implante o modelo de voos na Vertex AI
- Crie o arquivo de entrada de teste
example_input.json com este código:
%%writefile example_input.json
{"instances": [
{"dep_hour": 2, "is_weekday": 1, "dep_delay": 40, "taxi_out": 17, "distance": 41, "carrier": "AS", "dep_airport_lat": 58.42527778, "dep_airport_lon": -135.7075, "arr_airport_lat": 58.35472222, "arr_airport_lon": -134.57472222, "origin": "GST", "dest": "JNU"},
{"dep_hour": 22, "is_weekday": 0, "dep_delay": -7, "taxi_out": 7, "distance": 201, "carrier": "HA", "dep_airport_lat": 21.97611111, "dep_airport_lon": -159.33888889, "arr_airport_lat": 20.89861111, "arr_airport_lon": -156.43055556, "origin": "LIH", "dest": "OGG"}
]}
- Faça uma previsão no endpoint do modelo. Aqui os dados de entrada estão em um arquivo JSON chamado
example_input.json:
%%bash
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo $ENDPOINT_ID
gcloud beta ai endpoints predict $ENDPOINT_ID --region=$REGION --json-request=example_input.json
Veja como os programas clientes podem invocar o modelo que você implantou.
Digamos que os dados de entrada estão em um arquivo JSON chamado example_input.json.
- Agora envie uma solicitação POST HTTP. Você vai receber o resultado em JSON:
%%bash
PROJECT=$(gcloud config get-value project)
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @example_input.json \
"https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${REGION}/endpoints/${ENDPOINT_ID}:predict"
Tarefa 6: explicabilidade do modelo
A explicabilidade dos modelos é um dos problemas mais importantes em machine learning. É o conceito amplo de analisar e entender os resultados dos modelos de machine learning. Isso significa que você consegue explicar o que acontece no modelo, da entrada até a saída. O conceito torna os modelos transparentes e soluciona o problema da caixa preta. A Explainable AI (XAI) é a maneira mais formal de descrever isso.
- Execute o seguinte código:
%%bash
model_dir=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $model_dir
saved_model_cli show --tag_set serve --signature_def serving_default --dir $model_dir
- Crie um arquivo JSON chamado
explanation-metadata.json, que contém os metadados que descrevem a entrada e a saída do modelo para explicação. Você vai usar o método sampled-shapley, usado para explicações:
cols = ('dep_delay,taxi_out,distance,dep_hour,is_weekday,' +
'dep_airport_lat,dep_airport_lon,' +
'arr_airport_lat,arr_airport_lon,' +
'carrier,origin,dest')
inputs = {x: {"inputTensorName": "{}".format(x)}
for x in cols.split(',')}
expl = {
"inputs": inputs,
"outputs": {
"pred": {
"outputTensorName": "pred"
}
}
}
print(expl)
with open('explanation-metadata.json', 'w') as ofp:
json.dump(expl, ofp, indent=2)
- Abra o arquivo
explanation-metadata.json com o comando cat:
!cat explanation-metadata.json

Crie e implante outro modelo na Vertex AI, flights_xai
- Use este código para criar o endpoint do modelo
flights_xai, fazer upload do modelo e implantá-lo no endpoint:
%%bash
# note ENDPOINT_NAME is being changed
ENDPOINT_NAME=flights_xai
TIMESTAMP=$(date +%Y%m%d-%H%M%S)
MODEL_NAME=${ENDPOINT_NAME}-${TIMESTAMP}
EXPORT_PATH=$(gsutil ls ${OUTDIR}/export | tail -1)
echo $EXPORT_PATH
# create the model endpoint for deploying the model
if [[ $(gcloud beta ai endpoints list --region=$REGION \
--format='value(DISPLAY_NAME)' --filter=display_name=${ENDPOINT_NAME}) ]]; then
echo "Endpoint for $MODEL_NAME already exists"
else
# create model endpoint
echo "Creating Endpoint for $MODEL_NAME"
gcloud beta ai endpoints create --region=${REGION} --display-name=${ENDPOINT_NAME}
fi
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
echo "ENDPOINT_ID=$ENDPOINT_ID"
# delete any existing models with this name
for MODEL_ID in $(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME}); do
echo "Deleting existing $MODEL_NAME ... $MODEL_ID "
gcloud ai models delete --region=$REGION $MODEL_ID
done
# upload the model using the parameters docker conatiner image, artifact URI, explanation method,
# explanation path count and explanation metadata JSON file `explanation-metadata.json`.
# Here, you keep number of feature permutations to `10` when approximating the Shapley values for explanation.
gcloud beta ai models upload --region=$REGION --display-name=$MODEL_NAME \
--container-image-uri=us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.${TF_VERSION}:latest \
--artifact-uri=$EXPORT_PATH \
--explanation-method=sampled-shapley --explanation-path-count=10 --explanation-metadata-file=explanation-metadata.json
MODEL_ID=$(gcloud beta ai models list --region=$REGION --format='value(MODEL_ID)' --filter=display_name=${MODEL_NAME})
echo "MODEL_ID=$MODEL_ID"
# deploy the model to the endpoint
gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=$REGION \
--model=$MODEL_ID \
--display-name=$MODEL_NAME \
--machine-type=e2-standard-2 \
--min-replica-count=1 \
--max-replica-count=1 \
--traffic-split=0=100
Observação: vai demorar cerca de 15 a 20 minutos para criar o modelo, o endpoint do modelo e implantar o modelo no endpoint. Se você não conseguir acessar o link do endpoint gerado, ignore-o. Para conferir o progresso no seu console do Cloud, clique em Menu de navegação > Vertex AI > Previsão on-line > Endpoints.
Implante o modelo flights_xai na Vertex AI
Tarefa 7: invocar o modelo implantado
Veja como os programas clientes podem invocar o modelo que você implantou. Digamos que os dados de entrada estão em um arquivo JSON chamado example_input.json. Agora envie uma solicitação POST HTTP. Você vai receber o resultado em JSON.
- Execute o seguinte código:
%%bash
PROJECT=$(gcloud config get-value project)
ENDPOINT_NAME=flights_xai
ENDPOINT_ID=$(gcloud beta ai endpoints list --region=$REGION \
--format='value(ENDPOINT_ID)' --filter=display_name=${ENDPOINT_NAME})
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @example_input.json \
"https://${REGION}-aiplatform.googleapis.com/v1/projects/${PROJECT}/locations/${REGION}/endpoints/${ENDPOINT_ID}:explain"
Parabéns!
Parabéns! Neste laboratório, você aprendeu como criar um modelo usando a Vertex AI e implantá-lo nos endpoints da Vertex AI. Você também aprendeu a usar o recurso Explainable AI (XAI) da Vertex AI para explicar as previsões do modelo. Você treinou um modelo de regressão logística em todos os valores de entrada e aprendeu que o modelo não consegue usar bem os novos atributos, como locais de aeroportos.
Próximas etapas / Saiba mais
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 30 de outubro de 2023
Laboratório testado em 31 de outubro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.