Points de contrôle
Write a query to determine available seasons and games
/ 10
Create a labeled machine learning dataset
/ 10
Create a machine learning model
/ 20
Evaluate model performance and create table
/ 10
Using skillful ML model features
/ 10
Train the new model and make evaluation
/ 10
Run a query to create a table ncaa_2018_predictions
/ 10
Run queries to create tables ncaa_2019_tournament and ncaa_2019_tournament_predictions
/ 20
Prédiction du tableau d'un tournoi avec le machine learning de Google
- GSP461
- Aperçu
- Prérequis
- Ouvrir la console BigQuery
- Championnat NCAA March Madness
- Trouver l'ensemble de données public de la NCAA dans BigQuery
- Écrire une requête pour déterminer le nombre de saisons et de matchs disponibles
- Comprendre les caractéristiques et les étiquettes
- Créer un ensemble de données de machine learning étiqueté
- Partie 1 : créer un modèle de machine learning pour prédire l'équipe gagnante à partir de la place au classement des têtes de série et du nom de l'équipe
- Évaluer les performances du modèle
- Faire des prédictions
- Quel a été le niveau de réussite du modèle pour le tournoi 2018 de la NCAA ?
- Les modèles ne font pas de miracles...
- Partie 2 : utiliser des caractéristiques de modèles de ML plus avancées
- Prévisualiser les nouvelles caractéristiques
- Interpréter les statistiques sélectionnées
- Entraîner le nouveau modèle
- Évaluer les performances du nouveau modèle
- Identifier ce que le modèle a appris
- Passons aux prédictions !
- Analyse de la prédiction :
- Quelles ont été les surprises de mars 2018 ?
- Comparer les performances des modèles
- Prédictions pour le tournoi March Madness 2019
- Félicitations !
GSP461

Aperçu
Dans cet atelier, vous allez prédire le vainqueur d'une rencontre du tournoi de basket-ball masculin de la NCAA avec BigQuery, le machine Learning (ML) et l'ensemble de données du championnat masculin de basket-ball de la NCAA.
Cet atelier utilise la fonctionnalité BigQuery Machine Learning (BQML), qui vous permet de créer des modèles de ML de classification et de prévision basés sur SQL.
Objectifs de l'atelier
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Accéder à l'ensemble de données public de la NCAA à l'aide de BigQuery
- Explorer l'ensemble de données de la NCAA pour vous familiariser avec le schéma et le champ d'application des données disponibles
- Préparer les données existantes et les transformer en caractéristiques et en étiquettes
- Diviser l'ensemble de données en sous-ensembles destinés à l'entraînement et à l'évaluation
- Créer un modèle basé sur l'ensemble de données du tournoi de la NCAA avec BQML
- Prédire le tableau et le vainqueur du tournoi de la NCAA avec le modèle que vous avez créé
Prérequis
Cet atelier s'adresse aux utilisateurs de niveau intermédiaire. Pour le suivre, vous devez connaître le langage et les mots clé SQL. Il est également recommandé de savoir utiliser BigQuery. Si vous n'avez pas l'expérience requise dans ces domaines, suivez au minimum l'un des ateliers ci-dessous avant de vous lancer dans celui-ci :
Quand vous serez prêt, faites défiler la page pour en savoir plus sur les services que vous allez utiliser et sur la configuration de l'environnement de l'atelier.
BigQuery
BigQuery est la base de données d'analyse de Google. Économique et entièrement gérée, elle ne nécessite aucune opération (NoOps). Avec BigQuery, vous pouvez interroger des téraoctets et des téraoctets de données sans avoir à gérer d'infrastructure ni à faire appel aux services d'un administrateur de base de données. BigQuery est basé sur SQL et son utilisation est facturée selon un modèle de paiement à l'usage. BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des insights pertinents.
Un nouvel ensemble de données comportant des informations sur les matchs, les équipes et les joueurs de basket-ball de la NCAA est disponible. Les données sur les matchs couvrent les statistiques générales et par match depuis 2009, ainsi que les scores finaux depuis 1996. On y trouve des données supplémentaires sur les victoires et les défaites pouvant remonter à la saison 1894-1895 pour certaines équipes.
Machine learning
Google Cloud propose une gamme complète d'options de machine learning pour les analystes de données et les data scientists. Les plus populaires sont les suivantes :
- API de machine learning : utilisez des API pré-entraînées telles que Cloud Vision pour réaliser les tâches de ML les plus courantes.
- AutoML : créez des modèles de ML personnalisés sans code.
- BigQuery ML : créez des modèles de ML basés sur SQL dans BigQuery afin de les appliquer directement à vos données.
- AI Platform : construisez vos propres modèles de ML personnalisés et mettez-les en production avec l'infrastructure de Google.
Dans cet atelier, vous allez créer un prototype de modèle, l'entraîner et l'évaluer avec BigQuery ML afin de prédire l'équipe vainqueur et l'équipe perdante d'un match de basket-ball de la NCAA.
Prérequis
Configuration de Qwiklabs
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer votre atelier et vous connecter à la console
-
Cliquez sur le bouton Start Lab (Démarrer l'atelier). Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, le panneau Connection Details (Informations de connexion) contient les identifiants temporaires à utiliser pour cet atelier.
-
Copiez le nom d'utilisateur, puis cliquez sur Open Google Console (Ouvrir la console Google). L'atelier affiche les ressources, puis ouvre un nouvel onglet affichant la page Choose an account (Sélectionner un compte).
Conseil : Ouvrez les onglets dans des fenêtres distinctes, placées côte à côte.
-
Sur la page "Choose an account" (Sélectionner un compte), cliquez sur Use Another Account (Utiliser un autre compte).
-
La page de connexion s'affiche. Collez le nom d'utilisateur que vous avez copié dans le panneau "Connection Details" (Informations de connexion). Copiez et collez ensuite le mot de passe.
Important : Vous devez utiliser les identifiants fournis dans le panneau "Connection Details" (Informations de connexion), et non vos identifiants Qwiklabs. Si vous possédez un compte GCP, ne vous en servez pas pour cet atelier (vous éviterez ainsi que des frais ne vous soient facturés).
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais gratuits.


La console GCP s'ouvre dans cet onglet après quelques instants.
Ouvrir la console BigQuery
Dans la console Google Cloud, accédez au menu de navigation, puis sélectionnezBigQuery :
Cliquez sur Terminé pour accéder à l'interface utilisateur bêta. Assurez-vous que l'ID du projet GCP Qwiklabs est bien défini dans le menu "Resources" (Ressources) situé à gauche, qui devrait ressembler à ceci :
Si vous cliquez sur la flèche du menu déroulant à côté de votre projet, vous ne verrez aucune base de données ni aucune table, car vous n'en avez pas encore ajouté.
Par chance, BigQuery propose de nombreux ensembles de données publics et libres d'accès avec lesquels travailler. Nous allons maintenant parler plus en détail de l'ensemble de données de la NCAA, puis déterminer comment l'ajouter à votre projet BigQuery.
Championnat NCAA March Madness
La NCAA (National Collegiate Athletic Association) organise deux tournois de basket-ball universitaires majeurs tous les ans aux États-Unis, un féminin et un masculin. Lors du tournoi masculin de la NCAA en mars, 68 équipes s'affrontent dans des matchs à élimination directe. La dernière équipe est la grande gagnante du championnat March Madness.
La NCAA met à disposition un ensemble de données public qui contient les statistiques des matchs de basket-ball masculin et féminin ainsi que les joueurs et joueuses sélectionnés pour la saison et les tournois finaux. Les données sur les matchs couvrent les statistiques générales et par match depuis 2009, ainsi que les scores finaux depuis 1996. On y trouve des données supplémentaires sur les victoires et les défaites pouvant remonter à la saison 1894-1895 pour certaines équipes.
Vous pouvez consulter la campagne publicitaire Google Cloud Marketing sur la prédiction des tendances en temps réel afin d'en savoir un peu plus sur cet ensemble de données, voir comment il a été utilisé et suivre le tournoi de cette année : G.co/marchmadness
Trouver l'ensemble de données public de la NCAA dans BigQuery
Avant de procéder à cette étape, vérifiez que vous êtes toujours dans la console BigQuery. Cherchez l'onglet "Resources" (Ressources) dans le menu de gauche, cliquez sur le bouton + ADD DATA (+ AJOUTER DONNÉES), puis sélectionnez Explore public datasets (Accéder à des ensembles de données publics).
Tapez "NCAA Basketball" dans la barre de recherche et appuyez sur "Entrée". Lorsque l'ensemble apparaît, sélectionnez-le et cliquez sur VIEW DATASET (AFFICHER L'ENSEMBLE DE DONNÉES) :
Un nouvel onglet BigQuery affiche l'ensemble de données chargé. Vous pouvez continuer à travailler dans cet onglet, ou bien le fermer et actualiser votre console BigQuery dans l'autre onglet pour afficher votre ensemble de données public.
Cliquez sur la flèche à côté de l'ensemble de données ncaa_basketball pour en visualiser les tables :
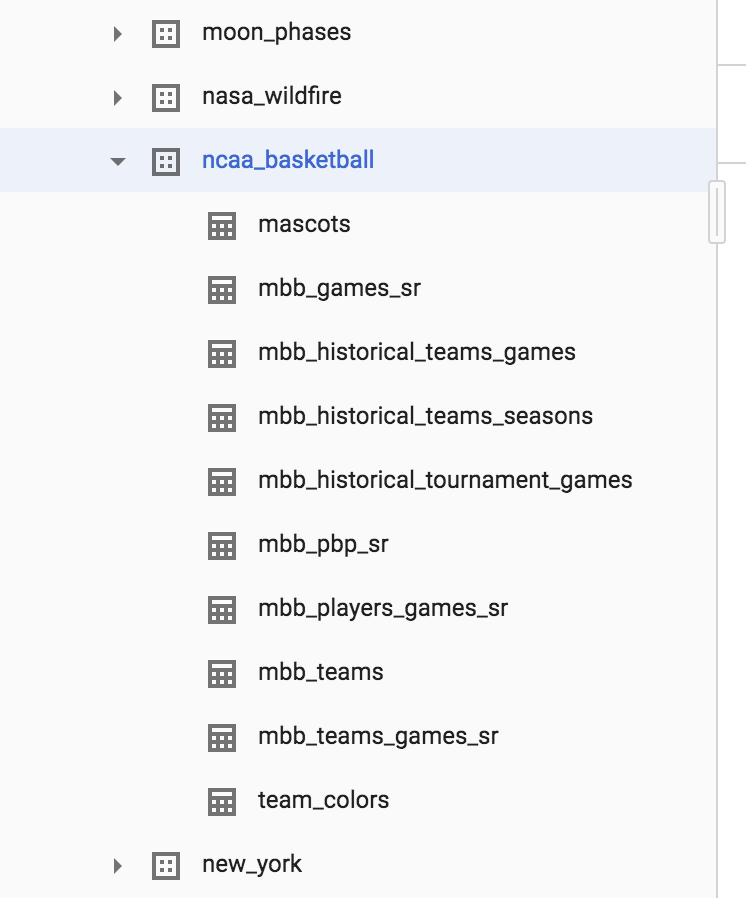
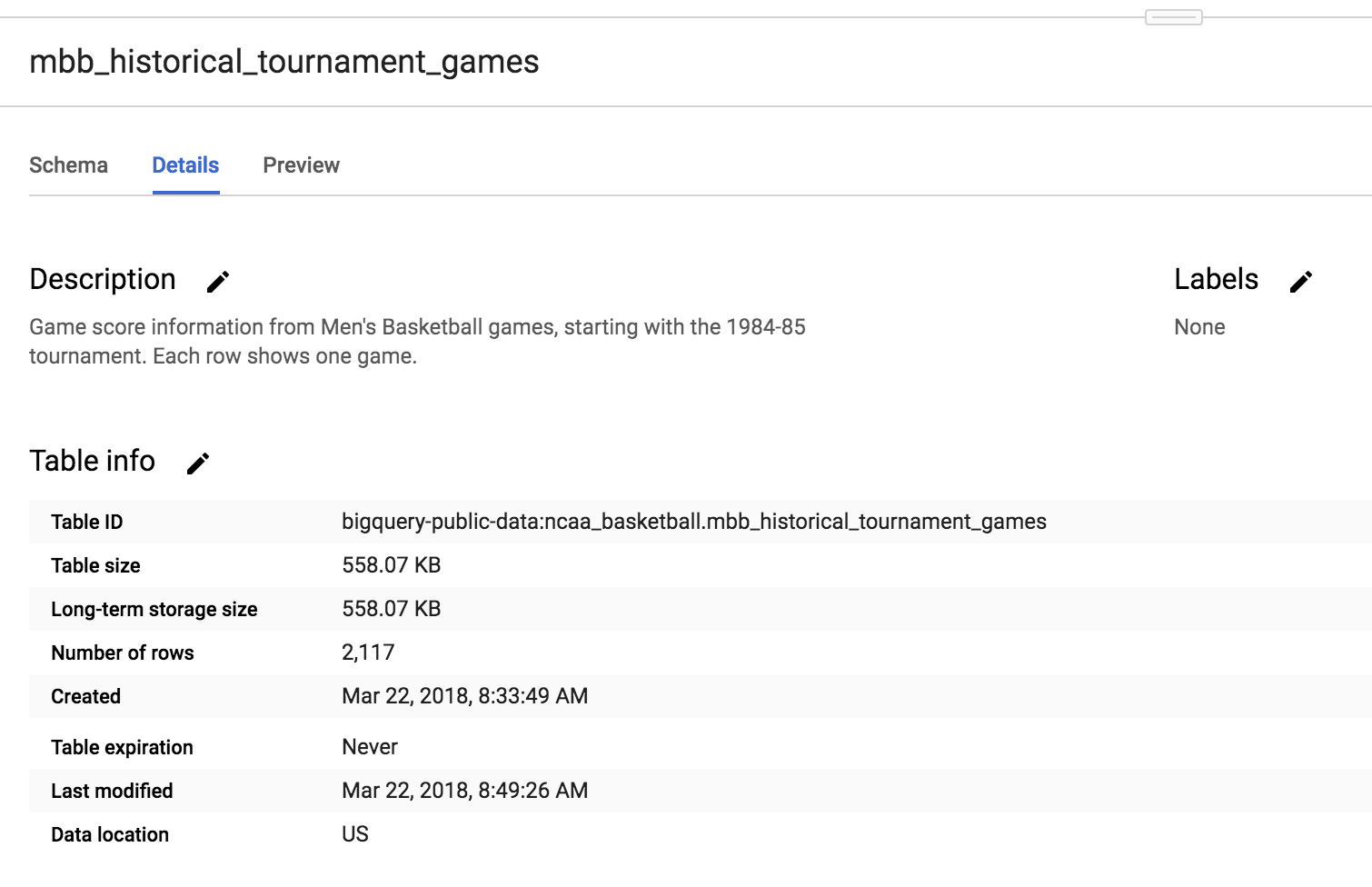
Normalement, l'ensemble de données comporte dix tables. Cliquez sur mbb_historical_tournament_games et sur Preview (Aperçu) pour générer un aperçu des lignes de données. Cliquez ensuite sur Details (Détails) pour consulter les métadonnées de la table. La page qui s'affiche doit ressembler à celle-ci :
Écrire une requête pour déterminer le nombre de saisons et de matchs disponibles
Vous allez à présent écrire une requête SQL simple pour déterminer le nombre de saisons et de matchs disponibles dans la table mbb_historical_tournament_games.
Cherchez l'éditeur de requête, qui se trouve au-dessus de la section "Details" (Détails) de la table, puis copiez-collez les commandes suivantes dans la zone de saisie :
SELECT
season,
COUNT(*) as games_per_tournament
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
GROUP BY season
ORDER BY season # default is Ascending (low to high)
Cliquez sur Run (Exécuter). Peu après, vous devriez obtenir un résultat semblable à celui-ci :
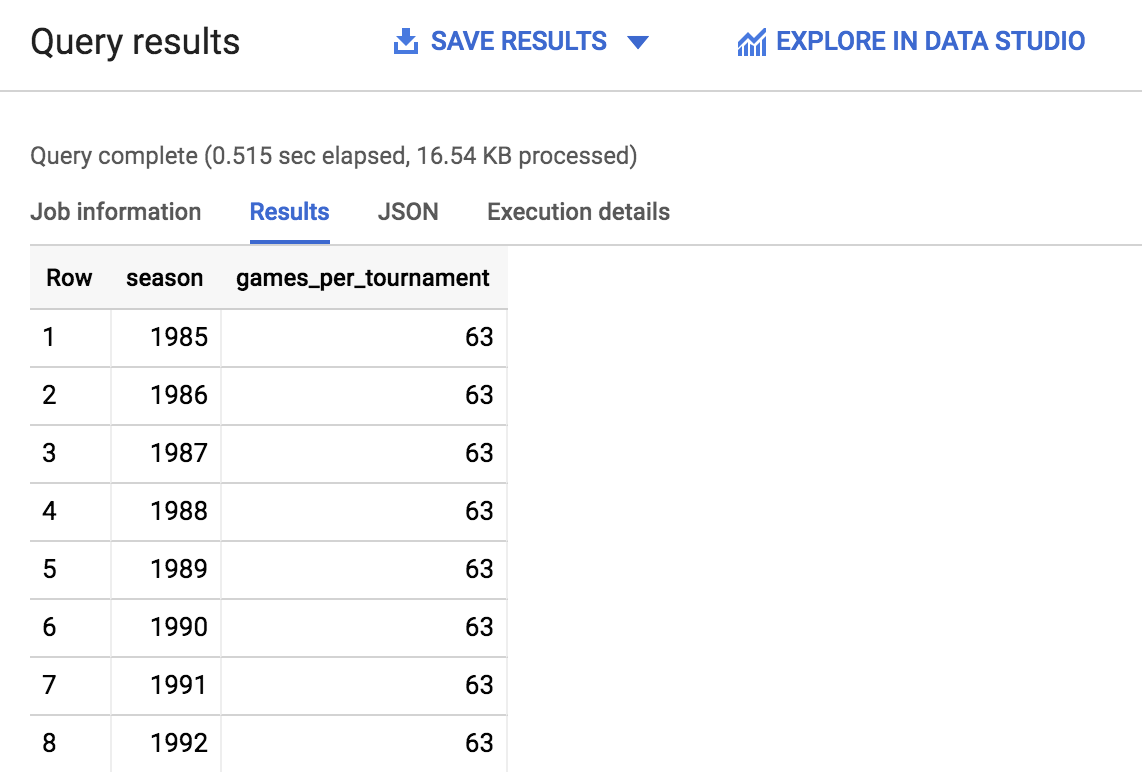
Parcourez les résultats et notez le nombre de saisons ainsi que le nombre de matchs organisés par saison. Ces informations vous seront utiles pour répondre aux questions qui suivent. Vous pouvez également voir rapidement le nombre de lignes renvoyées en bas à droite, près des flèches de pagination.
Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Tester vos connaissances
Répondez aux questions à choix multiples ci-dessous pour réviser les concepts abordés jusqu'ici. Répondez-y du mieux que vous le pouvez.
Comprendre les caractéristiques et les étiquettes
L'objectif de cet atelier est de prédire l'équipe gagnante d'un match de basket-ball masculin de la NCAA en s'appuyant sur les données historiques des matchs. En machine learning, une colonne de données permettant de déterminer un résultat (la victoire ou la défaite pour un match du tournoi) s'appelle une caractéristique.
La colonne comportant les données que vous souhaitez prédire s'appelle l'étiquette. Les modèles de machine learning apprennent à associer les caractéristiques entre elles pour prédire le résultat d'une étiquette.
Exemples de caractéristiques que votre ensemble de données pourrait comporter :
- Saison
- Nom de l'équipe
- Nom de l'équipe adverse
- Place de l'équipe au classement des têtes de série
- Place de l'équipe adverse au classement des têtes de série
L'étiquette que vous essayez de prédire pour les matchs à venir est le résultat du match, c'est-à-dire la victoire ou la défaite d'une équipe.
Tester vos connaissances
Répondez aux questions à choix multiples ci-dessous pour réviser les concepts abordés jusqu'ici. Répondez-y du mieux que vous le pouvez.
Créer un ensemble de données de machine learning étiqueté
Créer un modèle de machine learning nécessite un grand volume de données d'entraînement de bonne qualité. Par chance, l'ensemble de données de la NCAA est assez fourni pour permettre de créer un modèle efficace. Revenez à la console BigQuery. Elle devrait encore afficher les résultats de la requête que vous avez exécutée précédemment.
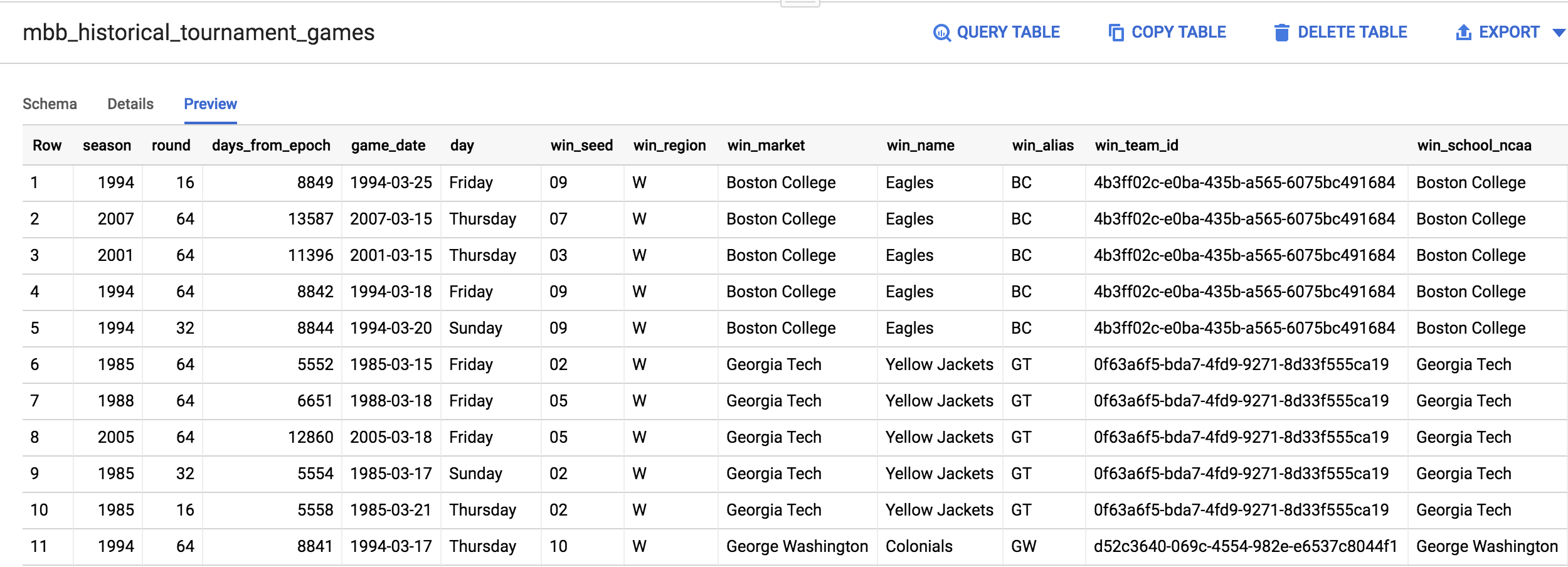
Dans le menu de gauche, ouvrez la table mbb_historical_tournament_games en cliquant sur son nom. Une fois qu'elle est chargée, cliquez sur Preview (Aperçu). La page qui s'affiche doit ressembler à celle-ci :
Tester vos connaissances
Répondez aux questions à choix multiples ci-dessous pour réviser les concepts abordés jusqu'ici. Répondez-y du mieux que vous le pouvez.
Après avoir parcouru l'ensemble de données, vous remarquerez qu'une ligne comporte à la fois les colonnes win_market et lose_market. Vous devez diviser le registre unifié des résultats des matchs de manière à séparer les données par équipe, et ainsi attribuer une étiquette "gagnante" ou "perdante" à chaque ligne.
Dans l'éditeur de requête, copiez-collez la requête suivante, puis cliquez sur Run (Exécuter) :
# create a row for the winning team
SELECT
# features
season, # ex: 2015 season has March 2016 tournament games
round, # sweet 16
days_from_epoch, # how old is the game
game_date,
day, # Friday
'win' AS label, # our label
win_seed AS seed, # ranking
win_market AS market,
win_name AS name,
win_alias AS alias,
win_school_ncaa AS school_ncaa,
# win_pts AS points,
lose_seed AS opponent_seed, # ranking
lose_market AS opponent_market,
lose_name AS opponent_name,
lose_alias AS opponent_alias,
lose_school_ncaa AS opponent_school_ncaa
# lose_pts AS opponent_points
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
round,
days_from_epoch,
game_date,
day,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_market AS market,
lose_name AS name,
lose_alias AS alias,
lose_school_ncaa AS school_ncaa,
# lose_pts AS points,
win_seed AS opponent_seed, # ranking
win_market AS opponent_market,
win_name AS opponent_name,
win_alias AS opponent_alias,
win_school_ncaa AS opponent_school_ncaa
# win_pts AS opponent_points
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
Vous devez obtenir le résultat suivant :
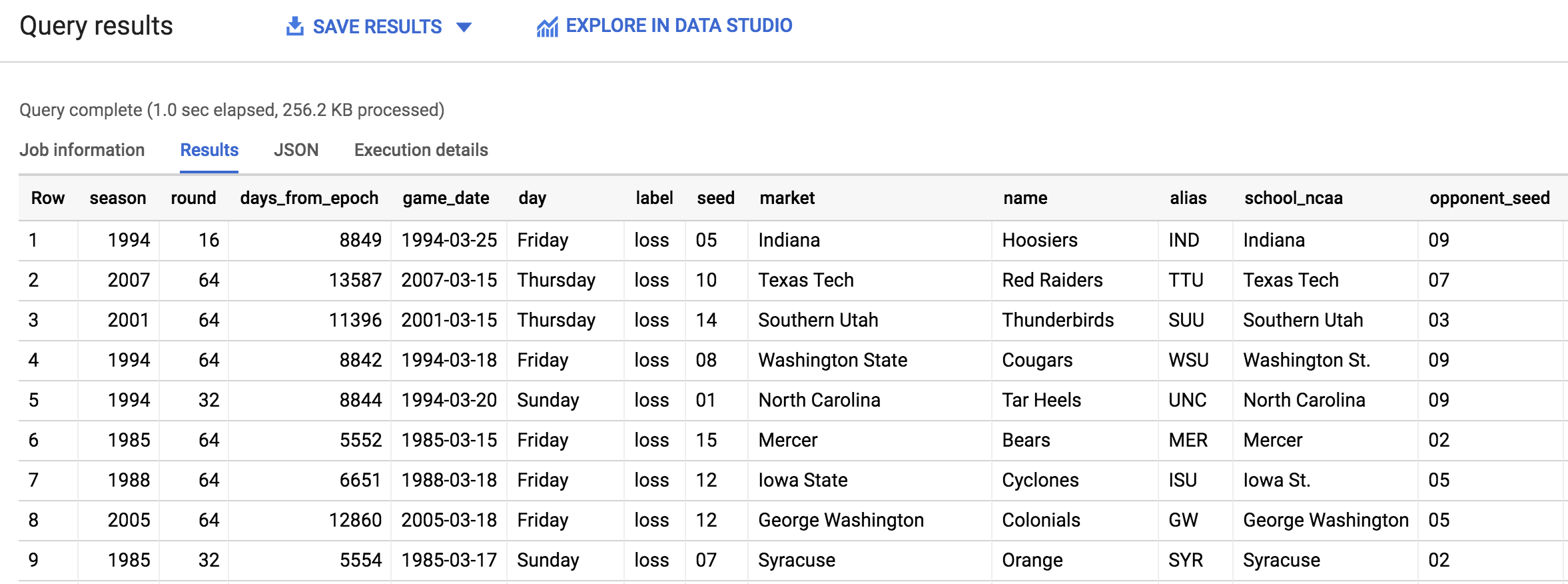
Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Vous connaissez maintenant les caractéristiques disponibles et pouvez répondre à la question suivante pour améliorer votre compréhension de l'ensemble de données.
Partie 1 : créer un modèle de machine learning pour prédire l'équipe gagnante à partir de la place au classement des têtes de série et du nom de l'équipe
Nous avons eu l'occasion de parcourir les données, et devons maintenant entraîner notre modèle de machine learning. Répondez aux questions suivantes du mieux possible, et utilisez-les pour vous guider dans cette section.
Choisir un type de modèle
Dans cette mise en situation, vous allez créer un modèle de classification. Comme nous avons deux classes, victoire ou défaite, on peut dire qu'il s'agit d'un modèle de classification binaire. Une équipe peut soit gagner un match, soit le perdre.
Lorsque cet atelier sera terminé, vous pourrez effectuer une prévision du nombre de points marqués par une équipe à l'aide d'un modèle de prévision, mais ce n'est pas l'objectif de ce chapitre.
Pour facilement déterminer si vous faites une prévision ou une classification, vous pouvez vérifier le type d'étiquette (colonne) de données que vous êtes en train de prédire :
- Si la colonne contient des valeurs numériques (un nombre d'unités vendues ou de points dans un match, par exemple), vous effectuez une prévision.
- S'il s'agit d'une valeur de chaîne, vous effectuez une classification (cette ligne correspond à une classe ou à l'autre).
- Si vous utilisez plus de deux classes (par exemple victoire, défaite et égalité), vous effectuez une classification à classes multiples.
Notre modèle de machine learning axé sur la classification se basera sur un modèle statistique largement répandu, la régression logistique. Nous avons besoin d'un modèle capable de générer une probabilité pour chaque modèle d'étiquette distinct possible, dans notre cas, une "victoire" ou une "défaite". La régression logistique est le type de modèle idéal pour ce cas de figure. Ce modèle de ML a l'avantage d'exploiter les fonctions avancées de calcul et d'optimisation de votre ordinateur pendant l'entraînement.
Créer un modèle de machine learning avec BigQuery ML
Pour créer notre modèle de classification dans BigQuery, il nous suffit d'écrire l'instruction SQL CREATE MODEL et d'ajouter quelques options.
Cependant, avant de créer le modèle, nous allons commencer par lui trouver un emplacement dans notre projet.
Dans la liste "Resources" (Ressources) du menu de gauche, sélectionnez votre projet Qwiklabs :
Cliquez ensuite sur CREATE DATASET (Créer un ensemble de données) à droite de l'écran. Un menu s'ouvre. Définissez l'ID de l'ensemble de données sur bracketology et cliquez sur Create dataset (Créer un ensemble de données) :
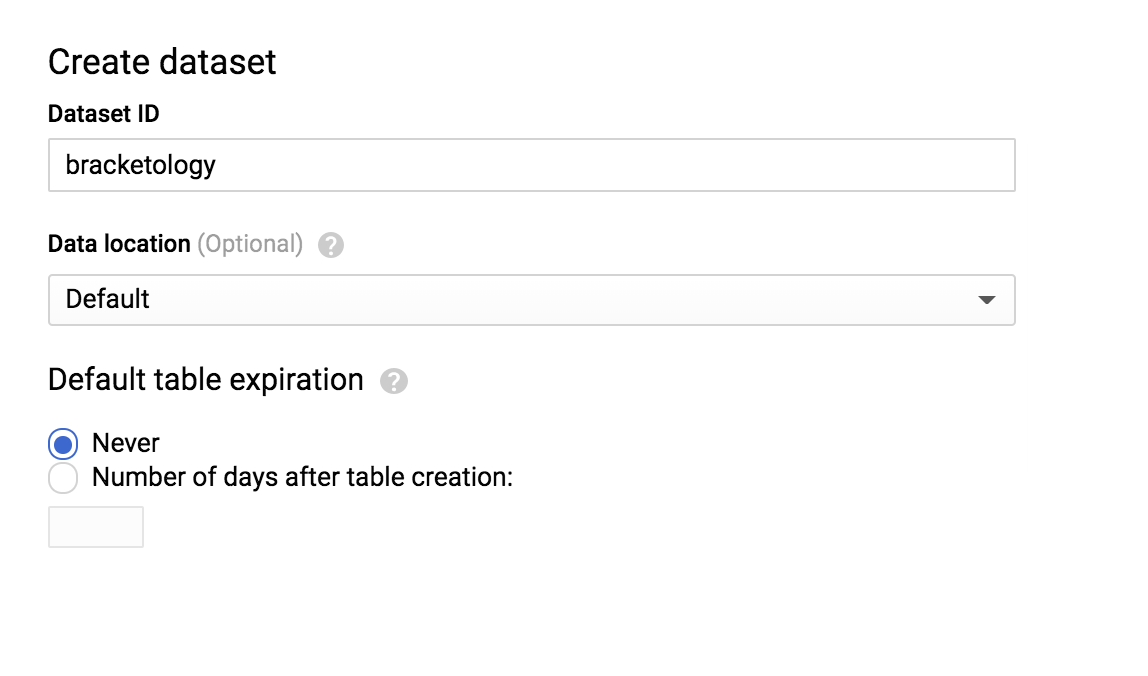
Exécutez les commandes suivantes dans l'éditeur de requête :
CREATE OR REPLACE MODEL
`bracketology.ncaa_model`
OPTIONS
( model_type='logistic_reg') AS
# create a row for the winning team
SELECT
# features
season,
'win' AS label, # our label
win_seed AS seed, # ranking
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
WHERE season <= 2017
UNION ALL
# create a separate row for the losing team
SELECT
# features
season,
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games`
# now we split our dataset with a WHERE clause so we can train on a subset of data and then evaluate and test the model's performance against a reserved subset so the model doesn't memorize or overfit to the training data.
# tournament season information from 1985 - 2017
# here we'll train on 1985 - 2017 and predict for 2018
WHERE season <= 2017
Ce code vous permet de constater que créer un modèle ne nécessite que quelques lignes de SQL. En revanche, il est très important de choisir le type de modèle logistic_reg pour notre tâche de classification.
L'entraînement du modèle prend entre 3 et 5 minutes. À la fin de l'opération, vous devriez recevoir le résultat suivant :

Cliquez sur le bouton Go to Model (Accéder au modèle) situé sur le côté droit de la console.
Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Consulter les informations du modèle d'entraînement
Dans la fenêtre des informations du modèle, descendez jusqu'à la section Training options (Options d'apprentissage) et affichez les itérations effectuées par le modèle au cours de l'entraînement. Les utilisateurs expérimentés en machine learning noteront qu'ils peuvent personnaliser tous ces hyperparamètres (options définies avant l'exécution du modèle) en configurant leur valeur dans l'instruction OPTIONS. Si vous débutez en machine learning, BigQuery ML attribuera des valeurs par défaut valides aux options laissées telles quelles.
Reportez-vous à la liste des options de modèle de BigQuery ML pour plus d'informations.
Consulter les statistiques du modèle d'entraînement
Les modèles de machine learning "apprennent" à associer les caractéristiques connues à des étiquettes inconnues. Comme vous l'aurez peut-être déjà remarqué, certaines caractéristiques sont plus utiles que d'autres pour déterminer une victoire ou une défaite. Par exemple, la place au classement des têtes de série et le nom de l'école seront plus pertinentes que le jour de programmation du match. Lorsqu'ils démarrent leur processus d'entraînement, les modèles de machine learning n'ont pas cette intuition et attribuent généralement une pondération aléatoire à chaque caractéristique.
Au cours du processus d'entraînement, le modèle va optimiser le niveau d'importance accordé à chaque caractéristique. À chaque exécution, il essaye de minimiser la perte des données d'entraînement et la perte des données d'évaluation. Si vous vous rendez compte que le taux de perte de données d'évaluation final est significativement plus élevé que celui des données d'entraînement, cela signifie que votre modèle est en surapprentissage, ou qu'il mémorise vos données d'entraînement au lieu d'apprendre quelles sont les relations généralisables.
Vous pouvez voir combien d'entraînements votre modèle a suivis en cliquant sur l'onglet Model Stats (Statistiques sur le modèle) ou Training (Entraînement). Au cours de cette séance, le modèle a terminé trois itérations d'entraînement en environ 20 secondes. Il est possible que vos statistiques soient différentes.
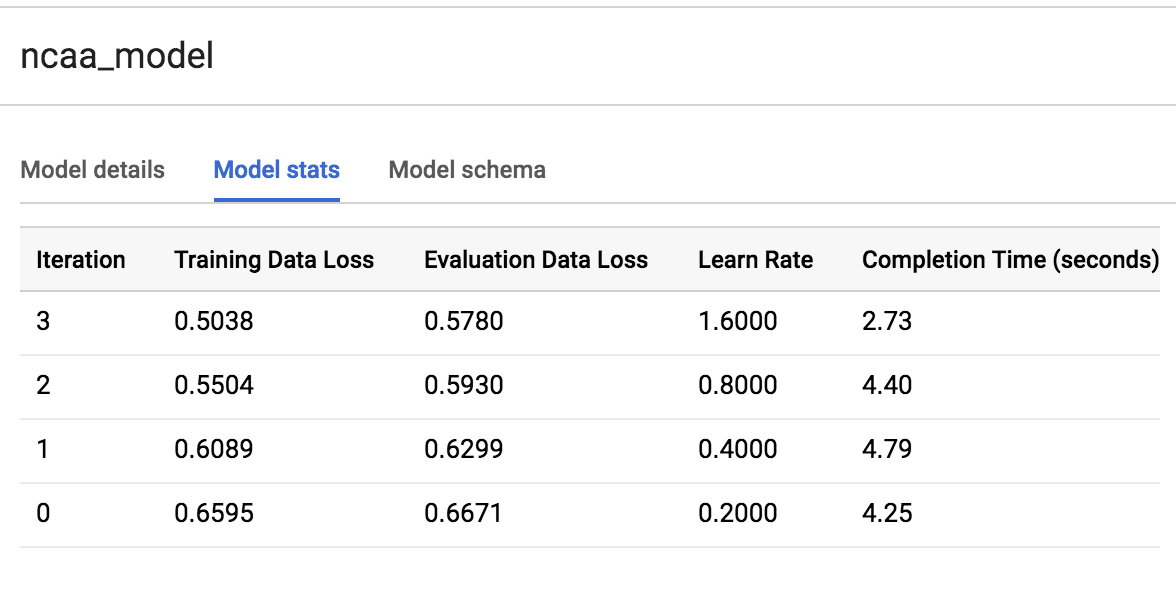
Voir ce que le modèle a appris des caractéristiques
Après l'entraînement, analyser la pondération vous permettra de voir quelles caractéristiques se sont avérées plus utiles pour votre modèle. Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT
category,
weight
FROM
UNNEST((
SELECT
category_weights
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model`)
WHERE
processed_input = 'seed')) # try other features like 'school_ncaa'
ORDER BY weight DESC
Le résultat doit se présenter comme suit :
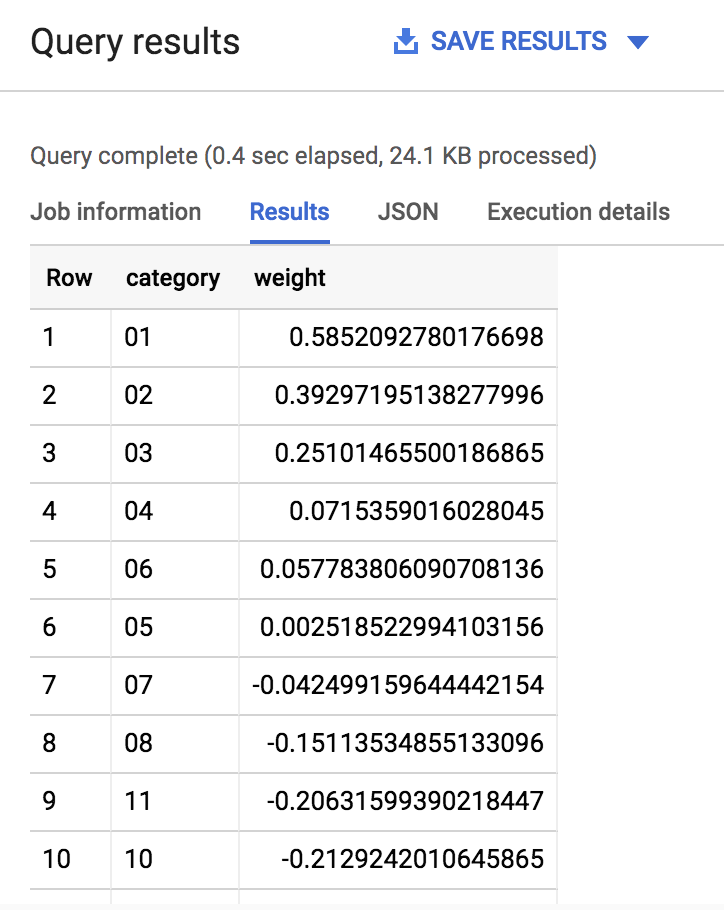
Comme vous pouvez le voir, si une équipe figure parmi les premières (1, 2, 3) ou les dernières (14, 15, 16) têtes de série, le modèle accorde plus d'importance à la caractéristique dans la détermination de la victoire ou de la défaite. En effet, les premières têtes de série sont censées obtenir de bons résultats au cours du tournoi.
L'essence du machine learning est d'être capable, sans abreuver le modèle d'instructions SQL IF THEN codées en dur, de lui faire comprendre que si (IF) l'équipe est tête de série n° 1, alors (THEN) il faudra estimer qu'elle a 80 % de chances supplémentaires de l'emporter. Le machine learning apprend les relations de manière autonome, sans logique ou règles codées en dur. Consultez la documentation sur la syntaxe pondérée de BQML pour plus d'informations.
Évaluer les performances du modèle
Pour évaluer les performances de votre modèle, il suffit d'exécuter la commande ML.EVALUATE à partir du modèle entraîné. Exécutez la commande suivante dans l'éditeur de requête :
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model`)
Vous devez obtenir un résultat semblable à celui-ci :

La valeur sera correcte à environ 69 %. Ce n'est pas du 50/50, mais cela mériterait d'être amélioré.
Faire des prédictions
Votre modèle ayant été entraîné sur des données historiques jusqu'à la saison 2017 incluse (ce qui constituait toutes les données en votre possession), il est maintenant possible de faire des prédictions pour la saison 2018. Votre équipe de science des données vient de vous fournir les résultats du tournoi de l'année 2018, qui se trouvent dans une table distincte de votre ensemble de données d'origine.
Pour faire les prédictions, il suffit d'appeler ML.PREDICT dans un modèle entraîné et de parcourir l'ensemble de données pour lequel vous voulez faire une prédiction.
Exécutez les commandes suivantes dans l'éditeur de requête :
CREATE OR REPLACE TABLE `bracketology.predictions` AS (
SELECT * FROM ML.PREDICT(MODEL `bracketology.ncaa_model`,
# predicting for 2018 tournament games (2017 season)
(SELECT * FROM `data-to-insights.ncaa.2018_tournament_results`)
)
)
Peu après, vous devriez obtenir un résultat semblable à celui-ci :

Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Votre ensemble de données d'origine affiche à présent trois colonnes supplémentaires :
- Étiquette prédite
- Options des étiquettes prédites
- Probabilité des étiquettes prédites
Comme vous connaissez les résultats du tournoi March Madness 2018, vous allez rapidement voir si les prédictions du modèle étaient justes. (Conseil : si vous voulez faire une prédiction pour le tournoi March Madness de cette année, utilisez un ensemble de données contenant le classement des têtes de série et le nom des équipes de l'année 2019). Bien entendu, ces colonnes seront vides, puisque ces matchs n'ont pas encore eu lieu... c'est là tout l'intérêt de la prédiction !)
Quel a été le niveau de réussite du modèle pour le tournoi 2018 de la NCAA ?
Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT * FROM `bracketology.predictions`
WHERE predicted_label <> label
Vous devez obtenir un résultat semblable à celui-ci :
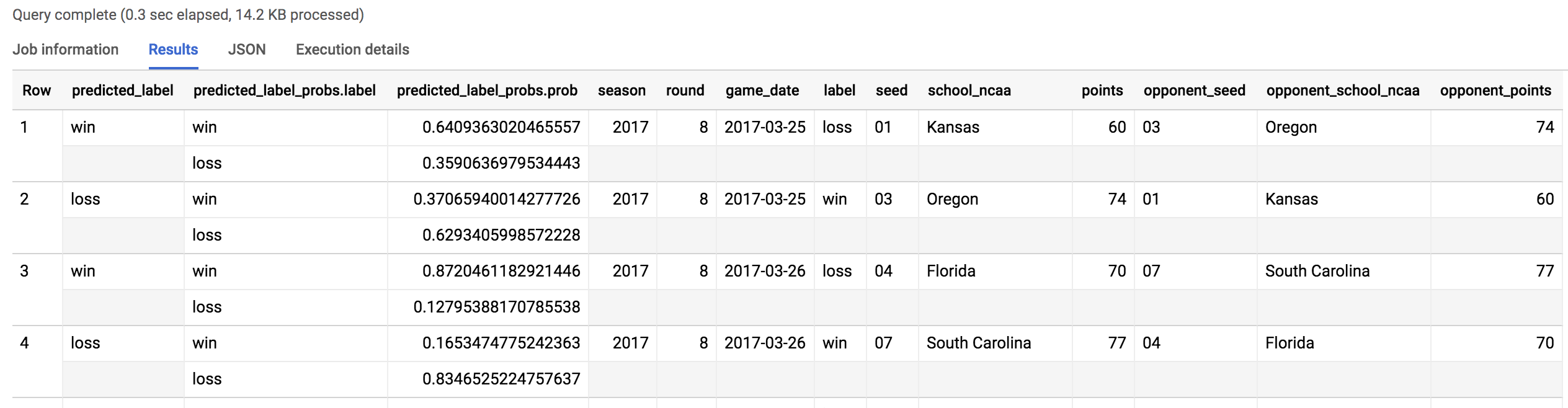
Sur 134 prédictions (67 matchs de tournoi), notre modèle s'est trompé 38 fois. C'est un score global de 70 % sur le tournoi 2018.
Les modèles ne font pas de miracles...
Beaucoup d'autres facteurs et caractéristiques entrent en ligne de compte dans les victoires très serrées et les défaites surprises du tournoi March Madness, ce qui en fait un événement très difficile à prédire pour les modèles.
Essayons de trouver les résultats les plus surprenants du tournoi 2017, d'après le modèle. Nous allons chercher des prédictions dont le niveau de confiance était supérieur à 80 %, mais qui se sont révélées FAUSSES.
Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT
model.label AS predicted_label,
model.prob AS confidence,
predictions.label AS correct_label,
game_date,
round,
seed,
school_ncaa,
points,
opponent_seed,
opponent_school_ncaa,
opponent_points
FROM `bracketology.predictions` AS predictions,
UNNEST(predicted_label_probs) AS model
WHERE model.prob > .8 AND predicted_label <> predictions.label
Vous devriez obtenir un résultat semblable à celui-ci :
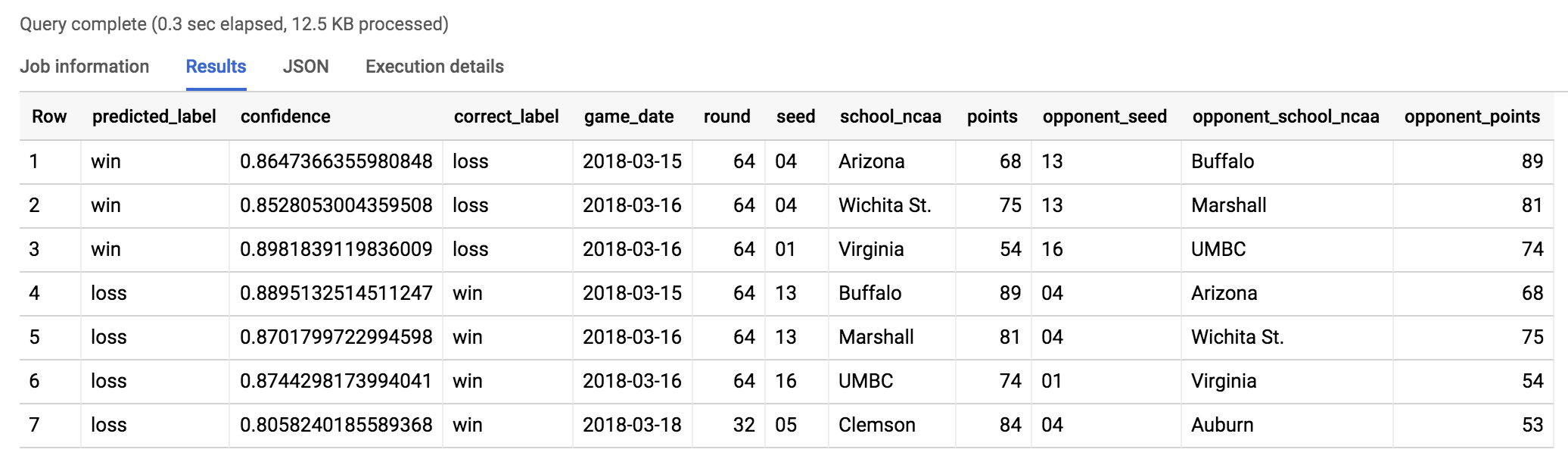
Regardez cette vidéo pour découvrir ce qui s'est passé !
À la fin du match, Barry Odom, entraîneur de l'UMBC a déclaré « Incroyable, c'est tout ce que je peux dire ».
Résumé
- Vous avez créé un modèle de machine learning servant à prédire les résultats d'un match.
- Vous avez évalué ses performances et avez obtenu une justesse de 69 % en utilisant le nom des équipes et leur place au classement des têtes de série comme caractéristiques principales.
- Vous avez prédit les résultats d'un tournoi de 2018.
- Vous avez analysé les résultats pour en tirer des informations.
Notre prochain défi sera de créer un modèle plus performant SANS utiliser les caractéristiques basées sur le nom des équipes et leur place au classement des têtes de série.
Partie 2 : utiliser des caractéristiques de modèles de ML plus avancées
Dans la deuxième partie de cet atelier, vous allez créer un autre modèle de ML en utilisant de nouvelles caractéristiques plus détaillées.
Vous savez désormais comment créer des modèles de ML avec BigQuery ML. Votre équipe de science des données vous a donc fourni un nouvel ensemble de données par match, qui contient de nouvelles statistiques d'équipes que votre modèle pourra apprendre, y compris :
- L'efficacité à marquer des paniers dans la durée, d'après une analyse historique réalisée pour chaque match
- La possession du ballon dans la durée
Créer un nouvel ensemble de données de ML avec ces caractéristiques avancées
Exécutez les commandes suivantes dans l'éditeur de requête :
# create training dataset:
# create a row for the winning team
CREATE OR REPLACE TABLE `bracketology.training_new_features` AS
WITH outcomes AS (
SELECT
# features
season, # 1994
'win' AS label, # our label
win_seed AS seed, # ranking # this time without seed even
win_school_ncaa AS school_ncaa,
lose_seed AS opponent_seed, # ranking
lose_school_ncaa AS opponent_school_ncaa
FROM `bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# create a separate row for the losing team
SELECT
# features
season, # 1994
'loss' AS label, # our label
lose_seed AS seed, # ranking
lose_school_ncaa AS school_ncaa,
win_seed AS opponent_seed, # ranking
win_school_ncaa AS opponent_school_ncaa
FROM
`bigquery-public-data.ncaa_basketball.mbb_historical_tournament_games` t
WHERE season >= 2014
UNION ALL
# add in 2018 tournament game results not part of the public dataset:
SELECT
season,
label,
seed,
school_ncaa,
opponent_seed,
opponent_school_ncaa
FROM
`data-to-insights.ncaa.2018_tournament_results`
)
SELECT
o.season,
label,
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM outcomes AS o
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS team
ON o.school_ncaa = team.team AND o.season = team.season
LEFT JOIN `data-to-insights.ncaa.feature_engineering` AS opp
ON o.opponent_school_ncaa = opp.team AND o.season = opp.season
Peu après, vous devriez obtenir un résultat semblable à celui-ci :

Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Prévisualiser les nouvelles caractéristiques
Cliquez sur le bouton Go to table (Accéder à la table) sur le côté droit de la console. Cliquez sur l'onglet Aperçu (Preview).
La table doit ressembler à celle-ci :
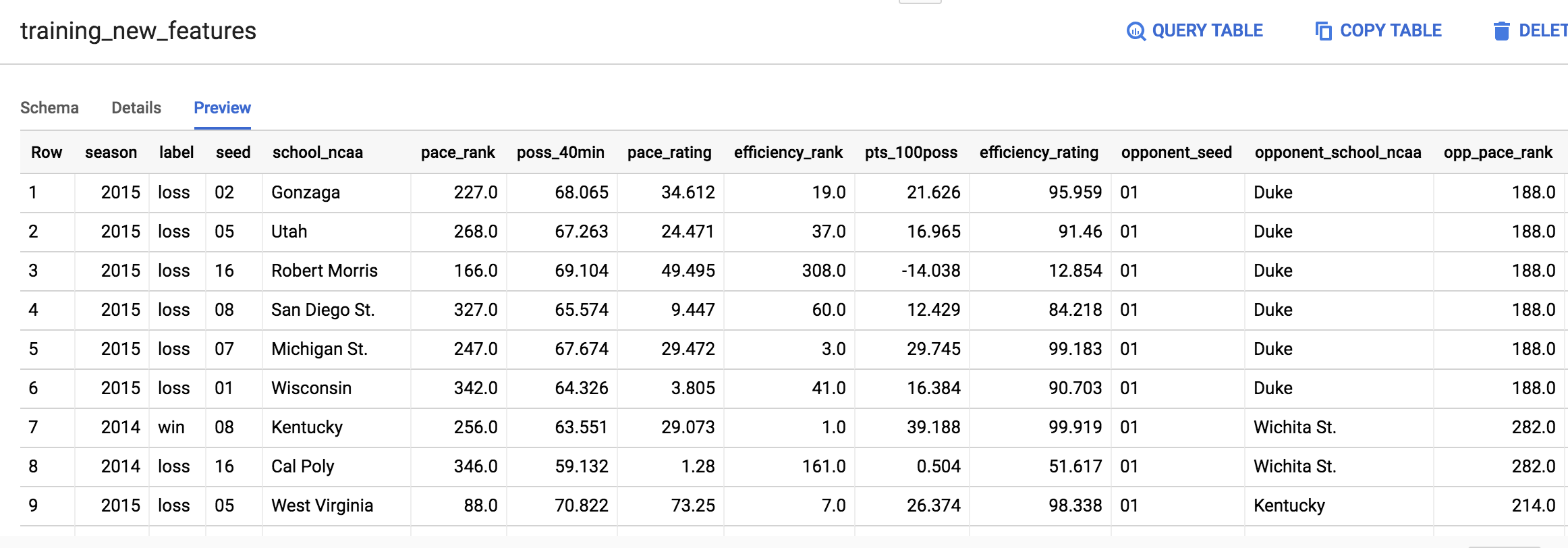
Si vous n'obtenez pas le même résultat que sur l'image ci-dessus, ne vous inquiétez pas.
Interpréter les statistiques sélectionnées
Vous allez maintenant découvrir des étiquettes importantes qui peuvent être très utiles pour effectuer des prédictions.
opp_efficiency_rank
Classement de l'efficacité de l'adversaire : parmi toutes les équipes, quel est le classement de notre adversaire par rapport au nombre de paniers marqués dans la durée (points par 100 possessions du ballon) ? Une valeur faible est préférable.
opp_pace_rank
Classement du rythme de l'adversaire : parmi toutes les équipes, quel est le classement de l'adversaire pour la possession du ballon (nombre de possessions en 40 minutes) ? Une valeur faible est préférable.
Vous disposez dorénavant de caractéristiques pertinentes sur l'efficacité des équipes en termes de paniers marqués et de capacité à rester en possession du ballon. Nous allons les utiliser pour entraîner notre deuxième modèle.
Pour éviter que ce nouveau modèle "se souvienne des bonnes équipes", effacez les noms des équipes et leur place au classement des têtes de série des caractéristiques pour travailler uniquement avec les nouvelles statistiques.
Entraîner le nouveau modèle
Exécutez les commandes suivantes dans l'éditeur de requête :
CREATE OR REPLACE MODEL
`bracketology.ncaa_model_updated`
OPTIONS
( model_type='logistic_reg') AS
SELECT
# this time, dont train the model on school name or seed
season,
label,
# our pace
poss_40min,
pace_rank,
pace_rating,
# opponent pace
opp_poss_40min,
opp_pace_rank,
opp_pace_rating,
# difference in pace
pace_rank_diff,
pace_stat_diff,
pace_rating_diff,
# our efficiency
pts_100poss,
efficiency_rank,
efficiency_rating,
# opponent efficiency
opp_pts_100poss,
opp_efficiency_rank,
opp_efficiency_rating,
# difference in efficiency
eff_rank_diff,
eff_stat_diff,
eff_rating_diff
FROM `bracketology.training_new_features`
# here we'll train on 2014 - 2017 and predict on 2018
WHERE season BETWEEN 2014 AND 2017 # between in SQL is inclusive of end points
Peu après, vous devriez obtenir un résultat semblable à ceci :
Évaluer les performances du nouveau modèle
Pour évaluer les performances de votre modèle, exécutez la commande suivante dans l'éditeur de requête :
SELECT
*
FROM
ML.EVALUATE(MODEL `bracketology.ncaa_model_updated`)
Vous devriez obtenir un résultat semblable à ceci :

Incroyable ! Vous venez d'entraîner un modèle avec des caractéristiques différentes et avez fait augmenter sa justesse à environ 75 %, soit une hausse de 5 % par rapport au modèle d'origine.
Il est indispensable de comprendre qu'avec le machine learning, la qualité des caractéristiques de l'ensemble de données a une influence importante sur la justesse du modèle.
Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Identifier ce que le modèle a appris
Quelles sont les caractéristiques auxquelles le modèle accorde le plus d'importance pour prédire une victoire ou une défaite ? Pour le savoir, exécutez la commande suivante dans l'éditeur de requête :
SELECT
*
FROM
ML.WEIGHTS(MODEL `bracketology.ncaa_model_updated`)
ORDER BY ABS(weight) DESC
Le résultat doit ressembler à l'exemple suivant :
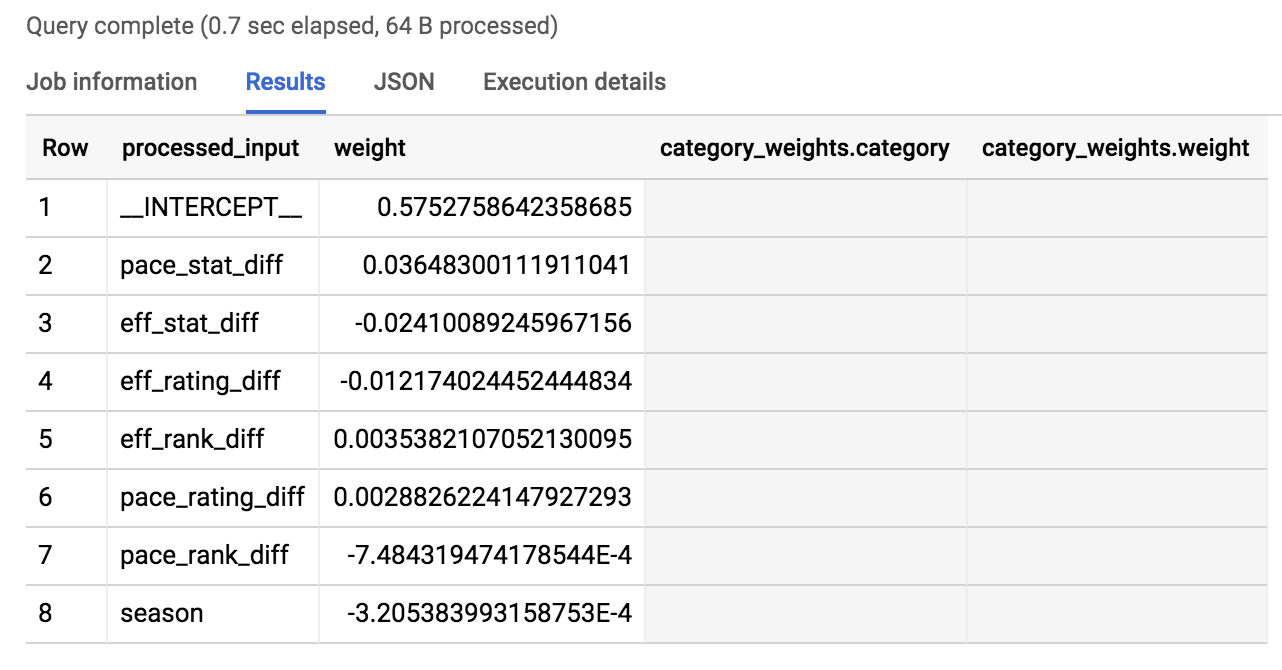
Nous avons pris la valeur absolue des pondérations pour les classer, de sorte à les faire apparaître par ordre d'importance (dans la détermination d'une victoire ou d'une défaite).
Comme vous pouvez le constater dans les résultats, les trois premières sont pace_stat_diff, eff_stat_diff et eff_rating_diff. Prenons le temps de mieux les comprendre.
pace_stat_diff
Différence entre les statistiques (possessions/40 minutes) des deux équipes. D'après ce modèle, il s'agit du facteur le plus important pour déterminer l'issue du match.
eff_stat_diff
Différence entre les statistiques (points nets/100 possessions) des deux équipes.
eff_rating_diff
Différence entre les classements normalisés portant sur l'efficacité à marquer des paniers pour les deux équipes.
Quelles caractéristiques le modèle a-t-il négligées dans ses prédictions ? Saison. Il s'agissait du dernier élément de la liste des pondérations énumérées ci-dessus. Ce modèle met en avant le fait que la saison (2013, 2014, 2015) n'est pas un élément utile dans la prédiction de l'issue du match. L'année 2014 n'avait rien de particulièrement magique pour les équipes.
Il est intéressant de voir que le modèle a accordé plus d'importance au rythme d'une équipe (sa tendance à être en possession du ballon) qu'à son efficacité à marquer.
Passons aux prédictions !
Exécutez les commandes suivantes dans l'éditeur de requête :
CREATE OR REPLACE TABLE `bracketology.ncaa_2018_predictions` AS
# let's add back our other data columns for context
SELECT
*
FROM
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
SELECT
* # include all columns now (the model has already been trained)
FROM `bracketology.training_new_features`
WHERE season = 2018
))
Vous devriez obtenir un résultat semblable à celui-ci :

Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Analyse de la prédiction :
Comme vous connaissez le véritable résultat du match, vous pouvez facilement identifier les prédictions incorrectes en vous appuyant sur le nouvel ensemble de données de test. Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT * FROM `bracketology.ncaa_2018_predictions`
WHERE predicted_label <> label
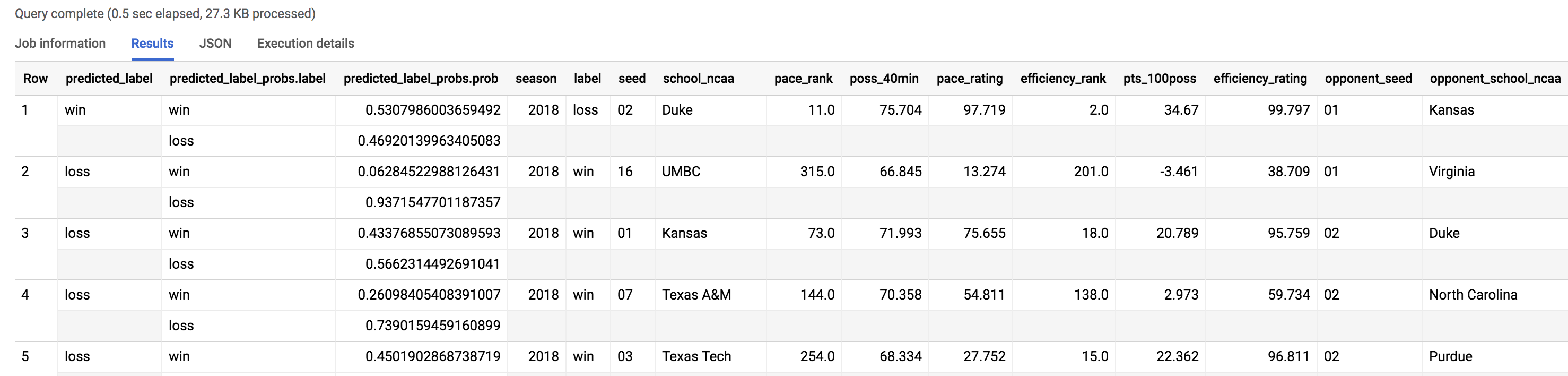
Vous voyez dans le nombre d'enregistrements renvoyés par la requête que le modèle s'est trompé à 48 reprises (24 matchs) sur le nombre total d'associations possibles au cours du tournoi de 2018, ce qui donne une justesse de 64 %. Découvrons les surprises qui ont fait de 2018 une année mémorable.
Quelles ont été les surprises de mars 2018 ?
Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT
CONCAT(school_ncaa, " was predicted to ",IF(predicted_label="loss","lose","win")," ",CAST(ROUND(p.prob,2)*100 AS STRING), "% but ", IF(n.label="loss","lost","won")) AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label <> n.label # model got it wrong
AND p.prob > .75 # by more than 75% confidence
ORDER BY prob DESC
Vous devriez obtenir le résultat suivant :
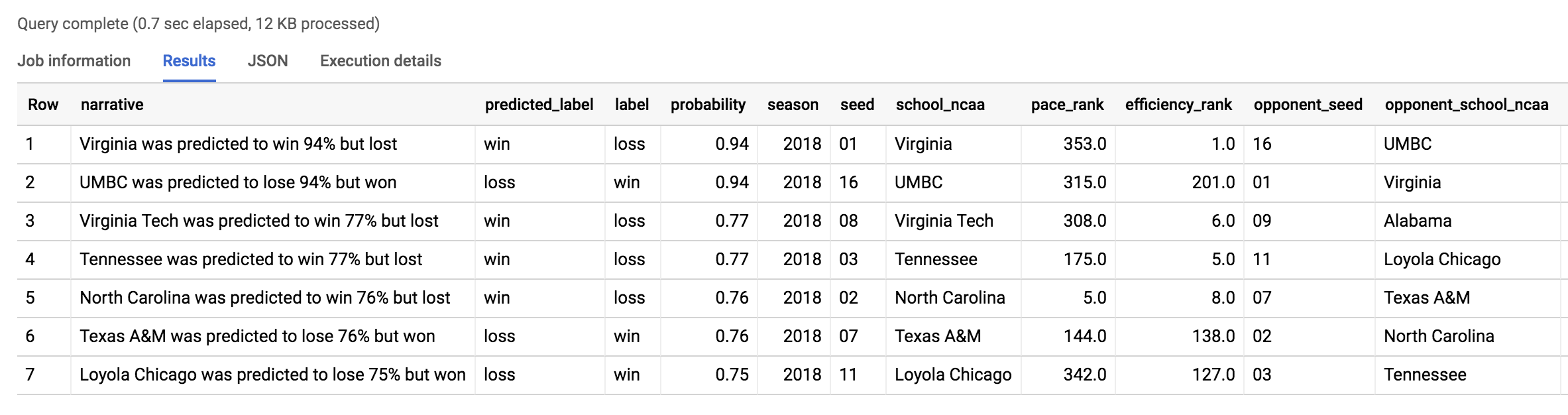
La plus grande surprise est celle que notre modèle précédent avait déjà trouvée : le match UMBC contre Virginia. Globalement, 2018 a été une année très surprenante. L'année 2019 nous réserve-t-elle autant de surprise ?
Comparer les performances des modèles
Que peut-on dire des fois où le modèle plus simpliste (avec comparaison des têtes de série) s'est trompé tandis que le modèle avancé a deviné juste ? Exécutez les commandes suivantes dans l'éditeur de requête :
SELECT
CONCAT(opponent_school_ncaa, " (", opponent_seed, ") was ",CAST(ROUND(ROUND(p.prob,2)*100,2) AS STRING),"% predicted to upset ", school_ncaa, " (", seed, ") and did!") AS narrative,
predicted_label, # what the model thought
n.label, # what actually happened
ROUND(p.prob,2) AS probability,
season,
# us
seed,
school_ncaa,
pace_rank,
efficiency_rank,
# them
opponent_seed,
opponent_school_ncaa,
opp_pace_rank,
opp_efficiency_rank,
(CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) AS seed_diff
FROM `bracketology.ncaa_2018_predictions` AS n,
UNNEST(predicted_label_probs) AS p
WHERE
predicted_label = 'loss'
AND predicted_label = n.label # model got it right
AND p.prob >= .55 # by 55%+ confidence
AND (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) > 2 # seed difference magnitude
ORDER BY (CAST(opponent_seed AS INT64) - CAST(seed AS INT64)) DESC
Vous devriez obtenir le résultat suivant :

Le modèle a prédit une surprise en faveur des Florida St. (09), contre Xavier (01), et c'est bien ce qui a eu lieu !
Ce résultat inattendu a été correctement prédit par le nouveau modèle qui s'est basé sur les nouvelles caractéristiques plus avancées, comme le rythme et l'efficacité à marquer (alors même que la place au classement des têtes de série suggérait l'inverse). Regardez les moments forts du match sur YouTube.
Prédictions pour le tournoi March Madness 2019
Nous connaissons maintenant les équipes et les têtes de série pour mars 2019, ce qui nous permet de prédire le résultat des matchs à venir.
Explorer les données de 2019
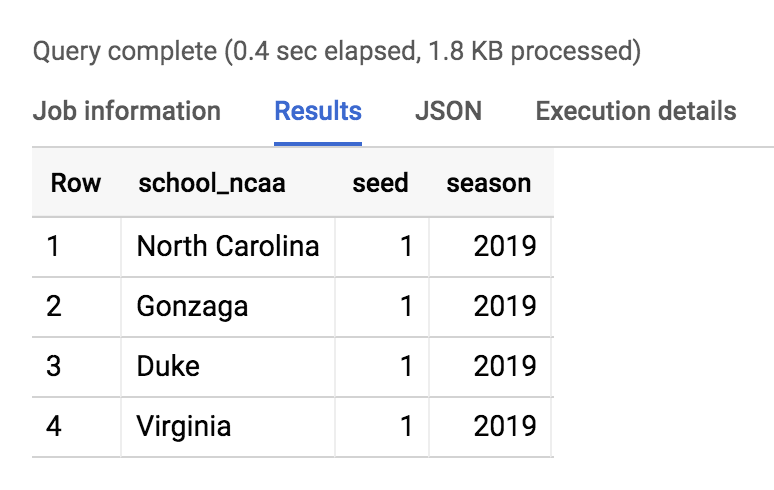
Exécutez la requête suivante pour identifier les meilleures têtes de série :
SELECT * FROM `data-to-insights.ncaa.2019_tournament_seeds` WHERE seed = 1
Vous devriez obtenir le résultat suivant :
Créer un tableau comportant tous les matchs possibles
Étant donné que nous ignorons quelles équipes s'affronteront durant le tournoi, nous allons toutes les opposer les unes aux autres.
Dans SQL, la fonction de jointure croisée (CROSS JOIN) nous permet de faire en sorte que toutes les équipes de la table s'affrontent.
Exécutez la requête ci-dessous pour créer tous les cas de figure possibles pendant le tournoi.
SELECT
NULL AS label,
team.school_ncaa AS team_school_ncaa,
team.seed AS team_seed,
opp.school_ncaa AS opp_school_ncaa,
opp.seed AS opp_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
Ajouter les statistiques d'équipes de 2018 (rythme, efficacité)
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament` AS
WITH team_seeds_all_possible_games AS (
SELECT
NULL AS label,
team.school_ncaa AS school_ncaa,
team.seed AS seed,
opp.school_ncaa AS opponent_school_ncaa,
opp.seed AS opponent_seed
FROM `data-to-insights.ncaa.2019_tournament_seeds` AS team
CROSS JOIN `data-to-insights.ncaa.2019_tournament_seeds` AS opp
# teams cannot play against themselves :)
WHERE team.school_ncaa <> opp.school_ncaa
)
, add_in_2018_season_stats AS (
SELECT
team_seeds_all_possible_games.*,
# bring in features from the 2018 regular season for each team
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE school_ncaa = team AND season = 2018) AS team,
(SELECT AS STRUCT * FROM `data-to-insights.ncaa.feature_engineering` WHERE opponent_school_ncaa = team AND season = 2018) AS opp
FROM team_seeds_all_possible_games
)
# Preparing 2019 data for prediction
SELECT
label,
2019 AS season, # 2018-2019 tournament season
# our team
seed,
school_ncaa,
# new pace metrics (basketball possession)
team.pace_rank,
team.poss_40min,
team.pace_rating,
# new efficiency metrics (scoring over time)
team.efficiency_rank,
team.pts_100poss,
team.efficiency_rating,
# opposing team
opponent_seed,
opponent_school_ncaa,
# new pace metrics (basketball possession)
opp.pace_rank AS opp_pace_rank,
opp.poss_40min AS opp_poss_40min,
opp.pace_rating AS opp_pace_rating,
# new efficiency metrics (scoring over time)
opp.efficiency_rank AS opp_efficiency_rank,
opp.pts_100poss AS opp_pts_100poss,
opp.efficiency_rating AS opp_efficiency_rating,
# a little feature engineering (take the difference in stats)
# new pace metrics (basketball possession)
opp.pace_rank - team.pace_rank AS pace_rank_diff,
opp.poss_40min - team.poss_40min AS pace_stat_diff,
opp.pace_rating - team.pace_rating AS pace_rating_diff,
# new efficiency metrics (scoring over time)
opp.efficiency_rank - team.efficiency_rank AS eff_rank_diff,
opp.pts_100poss - team.pts_100poss AS eff_stat_diff,
opp.efficiency_rating - team.efficiency_rating AS eff_rating_diff
FROM add_in_2018_season_stats
Faire des prédictions
CREATE OR REPLACE TABLE `bracketology.ncaa_2019_tournament_predictions` AS
SELECT
*
FROM
# let's predicted using the newer model
ML.PREDICT(MODEL `bracketology.ncaa_model_updated`, (
# let's predict on March 2019 tournament games:
SELECT * FROM `bracketology.ncaa_2019_tournament`
))
Cliquez sur Check my progress (Vérifier ma progression) pour vérifier l'objectif.
Obtenir vos prédictions
SELECT
p.label AS prediction,
ROUND(p.prob,3) AS confidence,
school_ncaa,
seed,
opponent_school_ncaa,
opponent_seed
FROM `bracketology.ncaa_2019_tournament_predictions`,
UNNEST(predicted_label_probs) AS p
WHERE p.prob >= .5
AND school_ncaa = 'Duke'
ORDER BY seed, opponent_seed
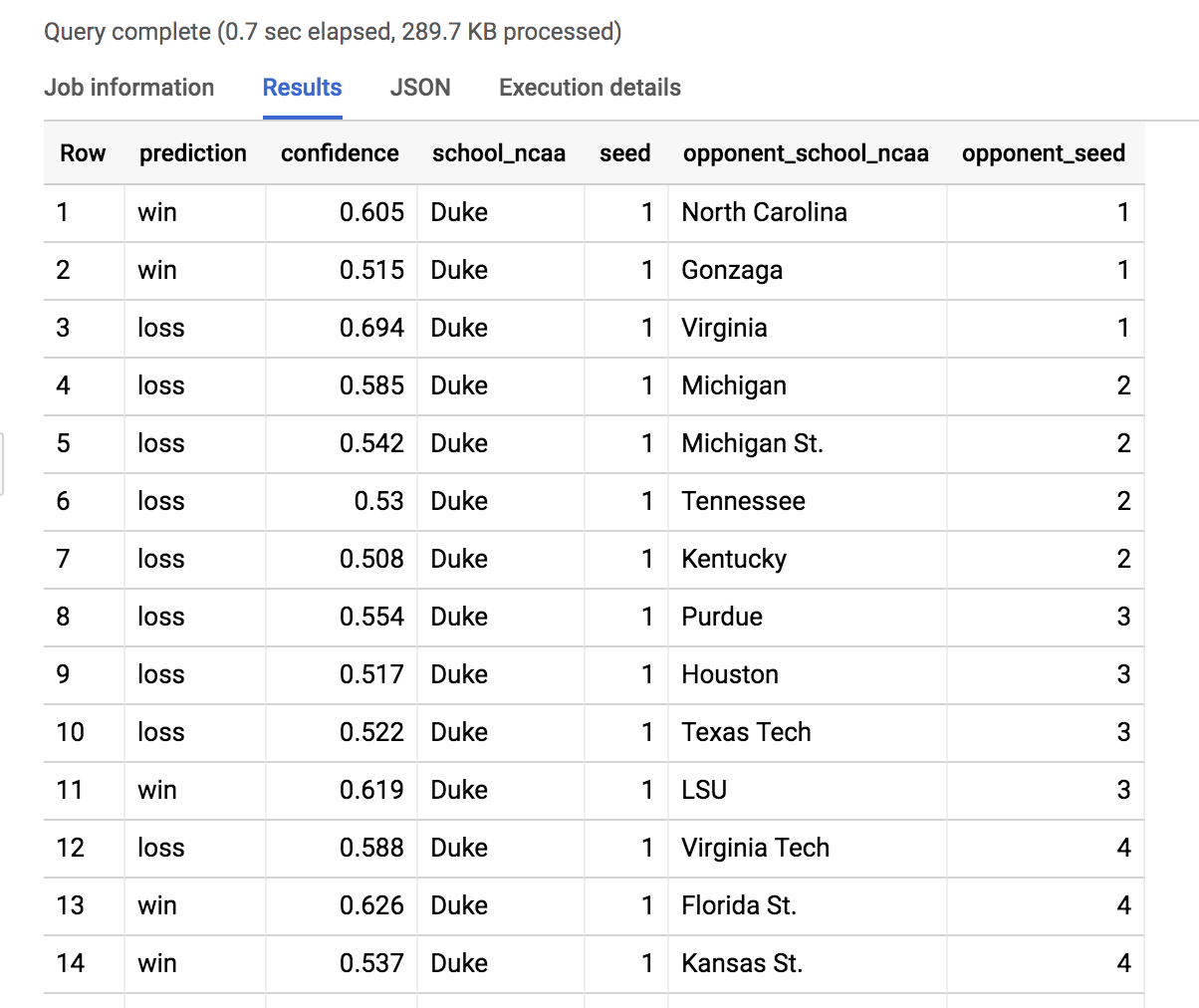
Ici, nous avons filtré les résultats du modèle pour afficher tous les matchs possibles pour l'équipe de Duke. Faites défiler la page pour trouver le match opposant Duke à North Dakota St.
Statistique : Duke (1) est 88,5 % plus susceptible de gagner que North Dakota St. (16) le 22 mars 2019.
Essayez de modifier le filtre school_ncaa au-dessus pour prédire les matchs de votre tableau. Notez le niveau de confiance du modèle et profitez des matchs !
Félicitations !
Et voilà ! Vous avez utilisé le machine learning pour prédire les victoires lors du tournoi de basket-ball masculin de la NCAA.


Terminer votre quête
Cet atelier d'auto-formation fait partie des quêtes Qwiklabs NCAA® March Madness®: Bracketology with Google Cloud et BigQuery for BigQuery for Machine Learning. Une quête est une série d'ateliers associés qui constituent une formation. Si vous terminez une quête, vous obtiendrez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à l'une de ces quêtes pour obtenir immédiatement les crédits associés à cet atelier si vous l'avez suivi. Découvrez d'autres quêtes Qwiklabs disponibles (http://google.qwiklabs.com/catalog).
Atelier suivant
Nous espérons que vous avez apprécié cet atelier consacré à l'exploration du big data et à la création de modèles de machine learning dans BigQuery. Vous pouvez maintenant passer à la suite :
Étapes suivantes et informations supplémentaires
- Vous voulez en savoir plus sur les statistiques et l'analyse des matchs de basket-ball ? Consultez d'autres analyses réalisées par l'équipe à l'origine des publicités et des prédictions Google Cloud sur le tournoi de la NCAA.
- Consultez l'article Utiliser le machine learning sur Compute Engine pour recommander des produits pour découvrir les possibilités qu'offre le ML.
- Quête Data Science
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 8 octobre 2020
Dernier test de l'atelier : 8 octobre 2020
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.