Checkpoints
Use Terraform to set up the necessary infrastructure
/ 50
Deploy demo application
/ 25
Generate Telemetry Data
/ 25
Como usar o Cloud Trace no Kubernetes Engine
GSP484

Visão geral
Quando você trabalha com um sistema de produção que atende a solicitações HTTP ou fornece uma API, é importante medir a latência dos endpoints para detectar quando o desempenho do sistema está fora da especificação. Em sistemas monolíticos, a medição da latência individual serve para detectar e diagnosticar um comportamento deteriorado. No entanto, isso é muito mais difícil com as arquiteturas de microsserviços modernas, porque uma única solicitação pode resultar em muitas outras solicitações para outros sistemas antes que a primeira solicitação seja atendida.
A deterioração do desempenho em um sistema subjacente talvez afete todos os outros sistemas que dependem dele. Embora seja possível medir a latência em cada endpoint de serviço, é difícil correlacionar a lentidão no endpoint público com erros em um sub-serviço específico.
O rastreamento distribuído é uma ótima solução para isso. Ele usa os metadados transmitidos com as solicitações para correlacioná-las com as diferentes camadas de serviço. Coletando dados de telemetria de todos os serviços em uma arquitetura de microsserviço e propagando um ID de trace de uma solicitação inicial para todas as solicitações subsidiárias, os desenvolvedores podem identificar com mais facilidade qual serviço causa atrasos que afetam o restante do sistema.
O pacote de operações do Google Cloud permite a geração de registros, monitoramento e rastreamento distribuído. Neste laboratório, vamos implantar o Kubernetes Engine e demonstrar uma arquitetura de várias camadas que implementa o rastreamento distribuído. Também usaremos o Terraform para criar a infraestrutura necessária.
Este laboratório foi criado por engenheiros do GKE Helmsman para explicar a autorização binária do GKE. Para conferir esta demonstração, execute os comandos gsutil cp -r gs://spls/gke-binary-auth/* . e cd gke-binary-auth-demo no Cloud Shell. Incentivamos todos a contribuir com nossos recursos.
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Clonar a demonstração
- Execute o seguinte comando para clonar os recursos necessários para este laboratório:
- Acesse o diretório da demonstração:
Configure sua região e zona
Alguns recursos do Compute Engine estão em regiões e zonas. As regiões são localizações geográficas específicas onde você executa seus recursos. Todas elas têm uma ou mais zonas.
Execute o comando a seguir para configurar a região e a zona do seu laboratório (use a região/zona mais adequada para você):
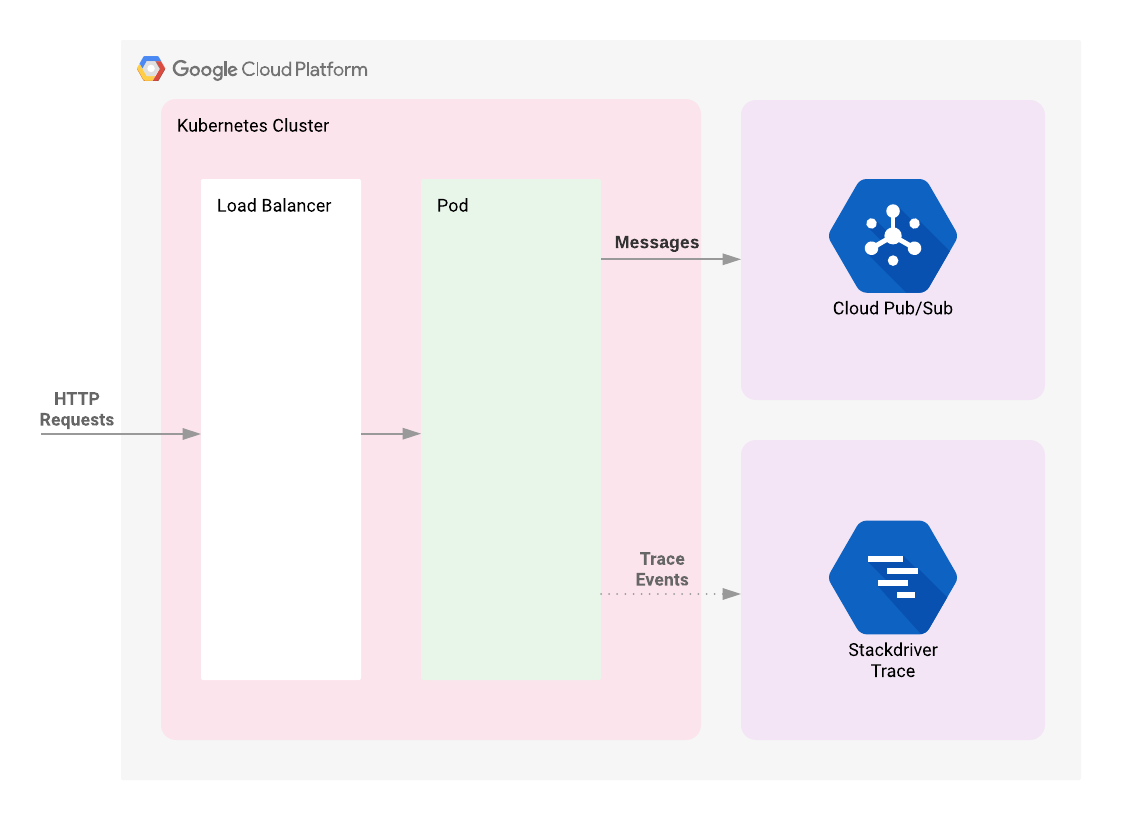
Arquitetura
O laboratório começa pela implantação de um cluster do Kubernetes Engine. Nesse cluster, vamos implantar um web app simples gerenciado por um balanceador de carga. O web app publica as mensagens fornecidas pelo usuário em um tópico do Cloud Pub/Sub. Quando solicitações HTTP são enviadas ao aplicativo, um trace é criado. O contexto do trace é propagado para a solicitação da API Publish do Cloud Pub/Sub. Os dados de telemetria correlacionados dessas solicitações estarão disponíveis no console do Cloud Trace.
Introdução ao Terraform
Seguindo os princípios de Infraestrutura como código e de Infraestrutura imutável, o Terraform possibilita a criação de descrições declarativas do estado de infraestrutura desejado. Quando o descritor é aplicado, o Terraform usa as APIs do Google Cloud para provisionar e atualizar os recursos. O Terraform compara o estado desejado com o estado atual para fazer outras alterações sem excluir tudo e começar de novo. Por exemplo, o Terraform pode criar projetos do Google Cloud, instâncias de computação e muito mais, e até mesmo configurar um cluster do Kubernetes Engine e implantar aplicativos nele. Quando os requisitos mudam, o descritor pode ser atualizado para que o Terraform faça as devidas alterações na infraestrutura em nuvem.
Este exemplo inicia um cluster do Kubernetes Engine usando o Terraform. Depois você usará os comandos do Kubernetes para implantar um aplicativo de demonstração no cluster. Por padrão, os clusters do Kubernetes Engine no Google Cloud têm um coletor baseado no Fluentd pré-configurado, que encaminha os eventos de geração de registro do cluster para o Cloud Monitoring. A interação com o app de demonstração produz eventos de trace que são exibidos na interface do Cloud Trace.
Como executar o Terraform
Esta demonstração inclui três arquivos do Terraform, localizados no subdiretório /terraform do projeto. O primeiro, main.tf, é o ponto de partida do Terraform. O arquivo descreve as funcionalidades que serão usadas, os recursos que serão manipulados e as respostas resultantes. O segundo arquivo, provider.tf, indica o provedor de nuvem e a versão de destino dos comandos do Terraform, neste caso, o Google Cloud. O último arquivo, variables.tf, contém uma lista das variáveis usadas como entradas do Terraform. Quando main.tf contém uma referência a uma variável que não está configurada em variables.tf, o sistema solicita a variável ao usuário no ambiente de execução.
Tarefa 1. Inicialização
Como a autenticação foi configurada acima, já está tudo pronto para implantar a infraestrutura.
- Execute o seguinte comando no diretório raiz do projeto:
Atualizar o arquivo provider.tf
Remova a versão do provedor do Terraform do arquivo de script provider.tf.
- Edite o arquivo de script
provider.tf:
- Se o arquivo tiver a string de versão estática do provedor
googleabaixo, remova-a:
- Clique em CTRL + X > Y > Enter para salvar o arquivo.
Após as alterações, o arquivo de script provider.tf ficará com esta aparência:
Nesse local, inicialize o Terraform.
- Insira o seguinte:
As dependências do Terraform serão salvas localmente: o projeto e a zona do Google Cloud em que o aplicativo de demonstração será implantado. Se não tiver esses valores, o Terraform perguntará ao usuário. Por padrão, ele procura pelos valores em um arquivo chamado terraform.tfvars ou arquivos com um sufixo .auto.tfvars no diretório atual.
Esta demonstração inclui um script conveniente para solicitar o projeto e a zona e salvar as informações no arquivo terraform.tfvars.
- Execute o seguinte:
O script usa os valores já configurados no comando gcloud. Se os valores não tiverem sido configurados, a mensagem de erro indicará como o usuário deve fazer isso. Para acessar os valores atuais, execute este comando:
- Se os valores exibidos não indicarem o local em que você quer executar o aplicativo de demonstração, basta alterar em
terraform.tfvars.
Tarefa 2. Implantação
- Após inicializar o Terraform, execute este comando para saber as tarefas que serão realizadas:
Use o comando para verificar se as configurações estão corretas. O Terraform informa caso detecte erros. Embora não seja necessário, é uma boa prática executar o comando antes de usar o Terraform para alterar a infraestrutura.
- Após a verificação, peça ao Terraform para configurar a infraestrutura necessária:
As alterações que serão feitas são exibidas, e você deve confirmá-las com yes.
Enquanto espera a infraestrutura ficar pronta, configure um espaço de trabalho do Cloud Monitoring para usar mais adiante no laboratório.
Testar a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você tiver implantado a infraestrutura necessária com o Terraform, uma pontuação de avaliação será exibida.
Criar um escopo de métricas do Monitoring
Configure um escopo de métricas do Monitoring associado ao seu projeto do Google Cloud. Siga estas etapas para criar uma nova conta com acesso à um teste gratuito do Monitoring.
- No console do Cloud, clique em Menu de navegação (
) > Monitoring.
Quando a página Informações gerais do Monitoring abrir, o escopo de métricas estará pronto.
Tarefa 3. Implantar o aplicativo de demonstração
-
De volta ao Cloud Shell, quando aparecer a mensagem
Apply complete!, retorne ao console. -
No menu de navegação, acesse Kubernetes Engine > Clusters para exibir o cluster.
-
Clique no menu de navegação, role para baixo até a seção "Análise de dados" e clique em Pub/Sub para exibir Tópico e Assinatura.
-
Agora implemente o aplicativo de demonstração usando o comando
kubectldo Kubernetes:
Depois da implantação, o app aparecerá em Kubernetes Engine > Cargas de trabalho. O balanceador de carga que foi criado para o aplicativo aparece na seção Serviços e entrada do console.
Pode demorar alguns minutos para que o aplicativo seja implantado. Caso o console das cargas de trabalho tenha o status "Não há disponibilidade mínima" abaixo, faça o seguinte:
- Atualize a página até aparecer "OK" na barra de status:
É possível receber o endpoint de forma programática com este comando:
Testar a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você tiver implantado corretamente o aplicativo de demonstração, uma pontuação de avaliação será exibida.
Tarefa 4. Validação
Como gerar dados de telemetria
Após a implantação do aplicativo de demonstração, uma lista dos serviços expostos será exibida.
- Ainda na janela do Kubernetes, clique em Serviços e entradas para exibir os serviços expostos.
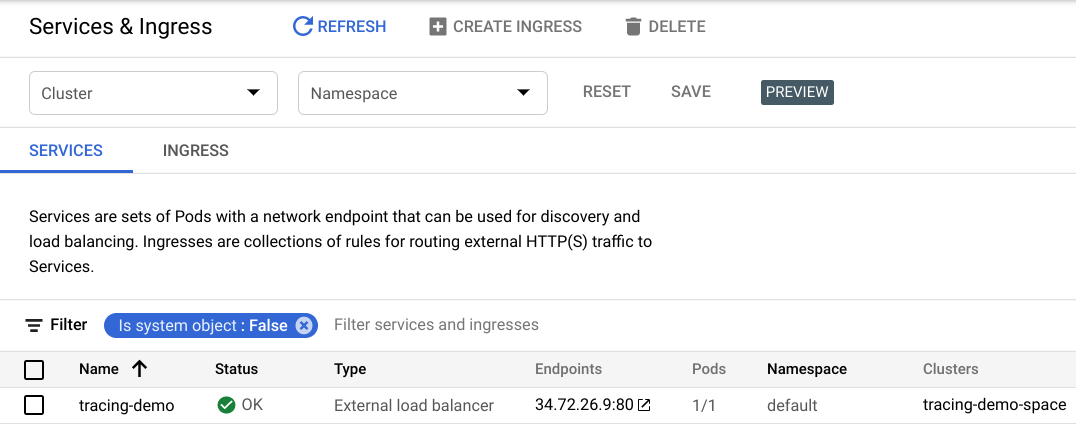
- Clique no endpoint ao lado do balanceador de carga
tracing-demopara abrir a página da Web do app de demonstração em uma nova guia do navegador.
Seu endereço IP será diferente do que aparece no exemplo acima. A página exibida é simples:
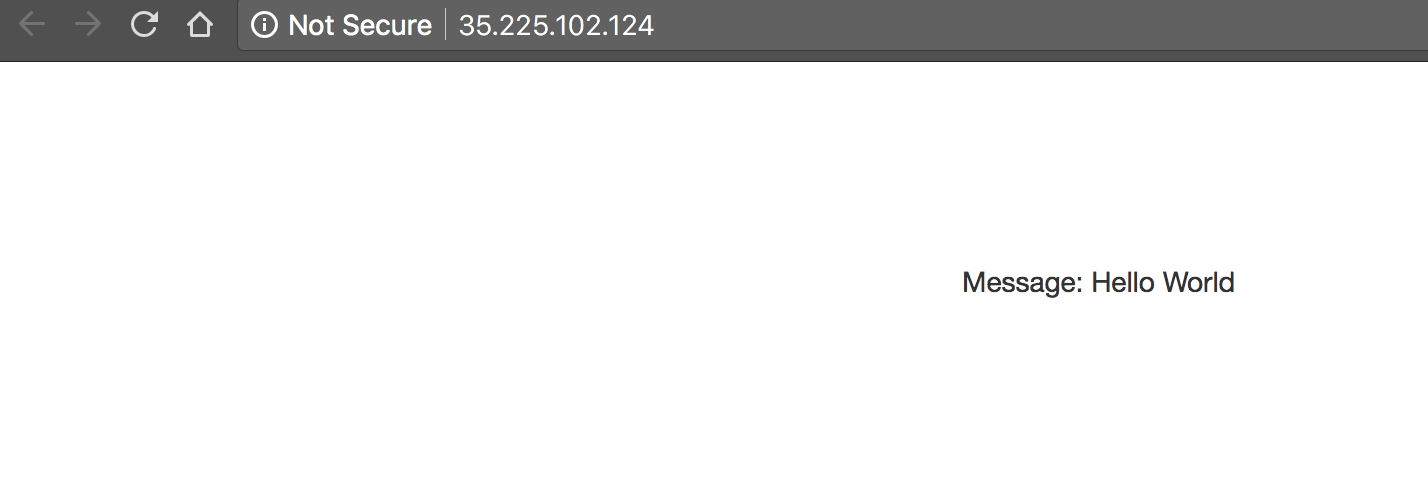
- No URL, adicione a string
?string=CustomMessagee confira se a mensagem a seguir é exibida:
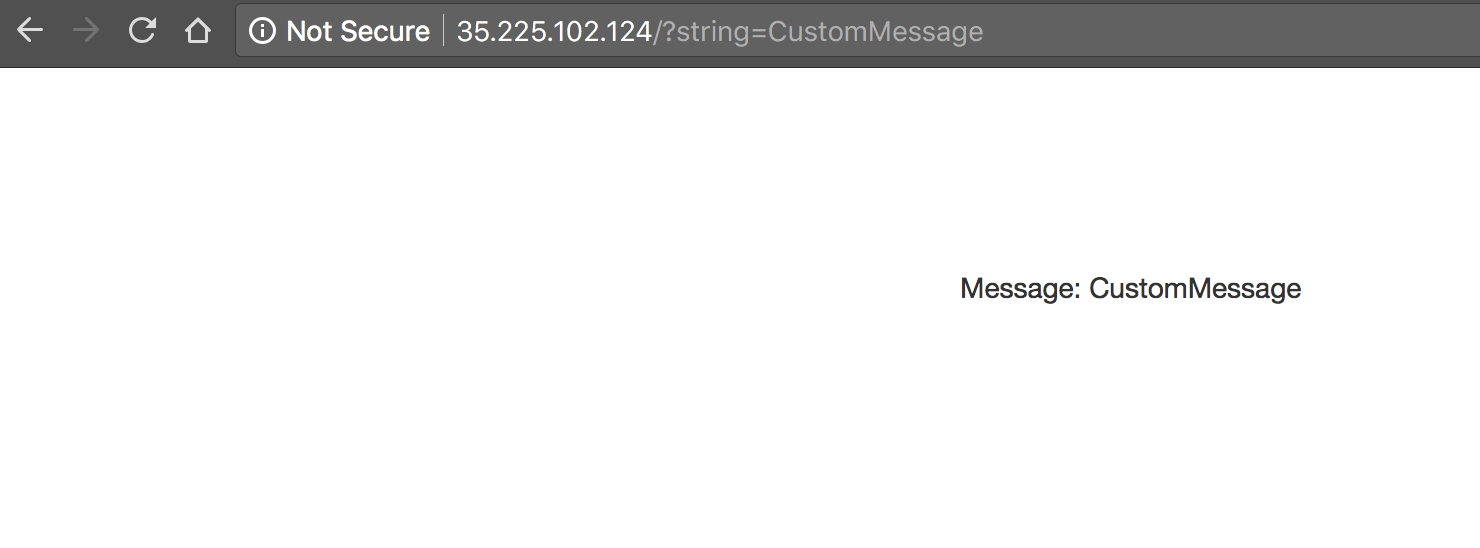
Quando um parâmetro string não é informado,
o aplicativo usa o valor padrão, Hello World. O app é usado para gerar dados de telemetria de trace.
- Substitua "CustomMessage" por suas próprias mensagens para gerar alguns dados para analisar.
Testar a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você gerou dados de telemetria, a pontuação de avaliação será exibida.
Como analisar os traces
-
No console, selecione Menu de navegação > Trace > Explorador de traces. Aparece um gráfico que exibe eventos de trace em uma linha do tempo, com a latência como métrica vertical.
-
Clique no botão ativar/desativar Recarregar automaticamente para abrir os dados mais recentes.
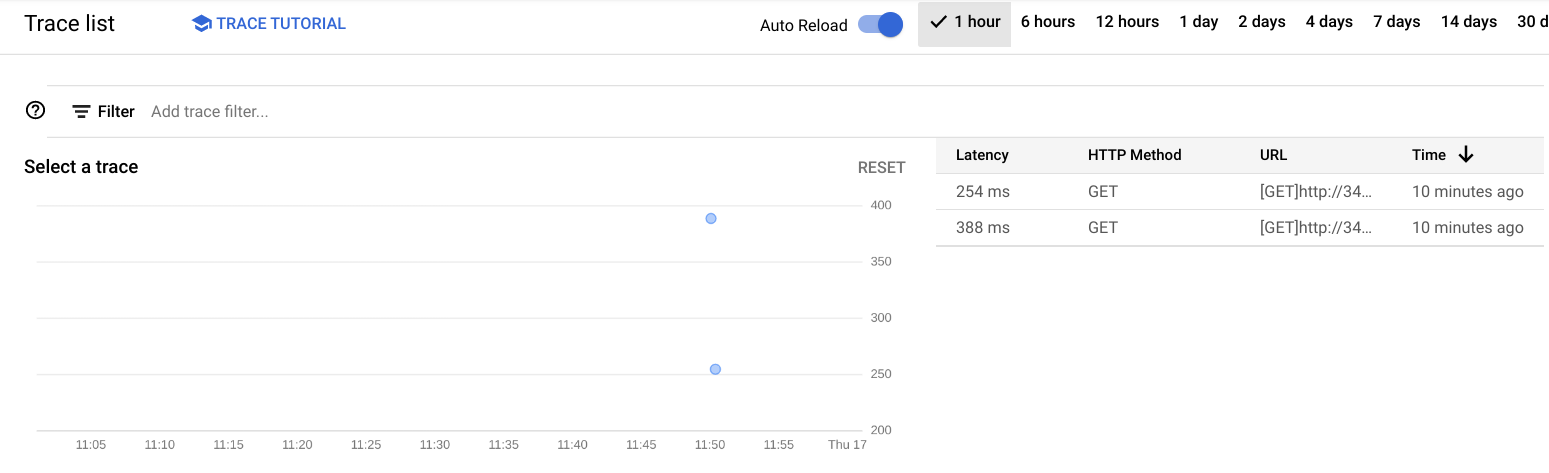
- Clique em um dos pontos no gráfico. Aparecerá um gráfico com duas barras, sendo a de cima maior que a de baixo.
A barra de cima, chamada de root span, representa a duração da solicitação HTTP desde a chegada do primeiro byte até o envio do último byte da resposta. A barra inferior representa a duração da solicitação feita ao enviar a mensagem para o tópico do Pub/Sub.
Como o processamento da solicitação HTTP é bloqueado porque a API Pub/Sub foi chamada, fica claro que a interação com o Pub/Sub toma a maior parte do tempo gasto para atender à solicitação HTTP. Assim demonstramos que a instrumentalização de cada camada do aplicativo facilita a identificação dos gargalos.
Extração de mensagens do Pub/Sub
Como descrevemos na seção "Arquitetura" deste documento, as mensagens do app de demonstração são publicadas em um tópico do Pub/Sub.
Abra essas mensagens com o seguinte comando da CLI do gcloud:
Saída:
A extração de mensagens do tópico não afeta o rastreio. Nesta seção, criamos um consumidor das mensagens para fins de verificação.
Como monitorar e gerar registros
O monitoramento e a geração de registros do Cloud não são temas desta demonstração, mas o aplicativo implantado publicará registros no Cloud Logging e métricas no Cloud Monitoring.
-
No console, selecione menu de navegação > Monitoramento > Metrics Explorer.
-
No campo "Selecione uma métrica", selecione Instância da VM > Instância > Uso da CPU e Aplicar.
Aparecerá um gráfico da métrica em diferentes pods em execução no cluster.
-
Para abrir os registros, selecione menu de navegação > Geração de registros.
-
Na seção Campos de registro, defina o seguinte:
-
TIPO DE RECURSO:
Kubernetes Container -
NOME DO CLUSTER:
tracing-demo-space -
NOME DO NAMESPACE:
default

Tarefa 5. Solução de problemas no seu ambiente
Use o comando kubectl para detectar vários erros possíveis.
Por exemplo, para exibir uma implantação:
Saída:
Para mais detalhes, use describe:
Este comando exibe uma lista dos pods implantados:
Saída:
Para abrir os detalhes do pod, use describe de novo:
-
Anote o nome do pod para usar na próxima etapa.
-
Use o nome para ler os registros no local:
Saída:
Ocorre uma falha no script de instalação com a mensagem Permission denied na execução do Terraform.
As credenciais que o Terraform está usando não concedem as permissões necessárias para criar recursos nos projetos selecionados. Verifique se a conta que aparece em gcloud config list tem as permissões necessárias para criar recursos. Se ela tiver, gere novamente as credenciais padrão do aplicativo usando gcloud auth application-default login.
Tarefa 6. Eliminação
- Embora o Qwiklabs se encarregue de desativar todos os recursos usados no laboratório, confira como limpar seu ambiente para reduzir o custo e ser um bom usuário da nuvem:
Assim como no comando apply, selecione yes para confirmar sua intenção ao Terraform.
Como o Terraform controla os recursos que criou, ele pode excluir o cluster, o tópico e a assinatura do Pub/Sub.
Parabéns!
Próximas etapas / Saiba mais
Confira outros materiais relevantes para seu aprendizado:
Kubernetes
O Kubernetes é uma conhecida plataforma de orquestração de contêineres em arquiteturas de microsserviço. O Google Cloud oferece uma versão gerenciada do Kubernetes chamada Kubernetes Engine.
OpenCensus
O OpenCensus oferece bibliotecas para coletar e publicar dados de telemetria de traces. Com bibliotecas para algumas das linguagens mais comuns, a solução tem suporte em diversas plataformas de trace, incluindo Cloud Monitoring e Zipkin. A demonstração descrita neste documento usa o OpenCensus para publicar dados de telemetria no Cloud Monitoring.
Spring Sleuth
O Spring Sleuth realiza a instrumentação de aplicativos Java que usam o conhecido framework Spring. Com o Spring Sleuth, os desenvolvedores podem usar abstração em coletores de telemetria de traces distribuída e alternar entre Zipkin, Cloud Monitoring e outros mecanismos.
Cloud Monitoring
O pacote de operações do Google Cloud inclui ferramentas para geração de registros, monitoramento, rastreamento e recursos relacionados. Neste documento e na demonstração, tratamos especificamente do recurso Cloud Trace desse pacote.
Terraform
O Terraform é uma ferramenta declarativa de infraestrutura como código que usa arquivos de configuração para automatizar a implantação e a evolução de infraestrutura na nuvem.
Zipkin
O Zipkin é uma ferramenta de rastreamento distribuído que contribuiu para popularizar a prática.
Quando um aplicativo já está instrumentado para Zipkin, é possível usar um Zipkin Collector para adaptar os dados de telemetria para eventos do Cloud Monitoring. Para implantar no Kubernetes Engine, use:
Esse comando implanta o coletor na porta 9411,
conhecida por ser usada pelo Zipkin. Os aplicativos que procurarem pelo Zipkin na porta local encontram
o que parece ser um servidor Zipkin, mas os dados de telemetria aparecem no Cloud Trace.
Finalize o laboratório
Após concluir o laboratório, clique em Terminar o laboratório. Sua conta e os recursos que você utilizou serão removidos da plataforma do laboratório.
Você poderá classificar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Enviar.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Suporte.
Manual atualizado em 28 de setembro de 2023
Laboratório testado em 28 de setembro de 2023
Copyright 2024 Google LLC. Este software é fornecido no estado em que se encontra, sem declarações nem garantias para qualquer uso ou finalidade. O uso do software está sujeito ao seu contrato com o Google.