检查点
Create Cloud Composer environment
/ 30
Create a Cloud Storage bucket
/ 30
Upload Airflow Files to Cloud Storage
/ 20
Upload data or other files to cloud storage
/ 20
Cloud Composer: Qwik Start - Command Line
- GSP606
- Overview
- Setup and requirements
- What is Cloud Composer?
- What is Apache Airflow?
- What is Cloud Dataproc?
- Task 1. Sample workflow
- Task 2. Verify the Composer environment
- Task 3. Set up Apache Airflow environment variables
- Task 4. Upload Airflow files to Cloud storage
- Task 5. Using the Airflow web interface
- Delete Cloud Composer Environment
- Congratulations!
GSP606

Overview
Workflows are a common theme in data analytics - they involve ingesting, transforming, and analyzing data to figure out the meaningful information within. In Google Cloud, the tool for hosting workflows is Cloud Composer which is a hosted version of the popular open source workflow tool Apache Airflow.
In this lab, you use the Cloud Shell command line to set up a Cloud Composer environment. You then use Cloud Composer to go through a simple workflow that verifies the existence of a data file, creates a Cloud Dataproc cluster, runs an Apache Hadoop wordcount job on the Cloud Dataproc cluster, and deletes the Cloud Dataproc cluster afterwards.
This lab also shows you how to access your Cloud Composer environment through the Cloud Console and the Airflow web interface.
What you'll do
- Use Cloud Shell command line to create the Cloud Composer environment and set up the Composer environment variables
- Verify the Environment configuration in the Cloud Console
- Run an Apache Airflow workflow in Cloud Composer that runs an Apache Hadoop wordcount job on the cluster
- View and run the DAG (Directed Acyclic Graph) in the Airflow web interface
- View the results of the wordcount job in storage
Suggested experience
Having the following experience can help maximize your learning:
- Basic CLI knowledge
- Basic understanding of Python
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
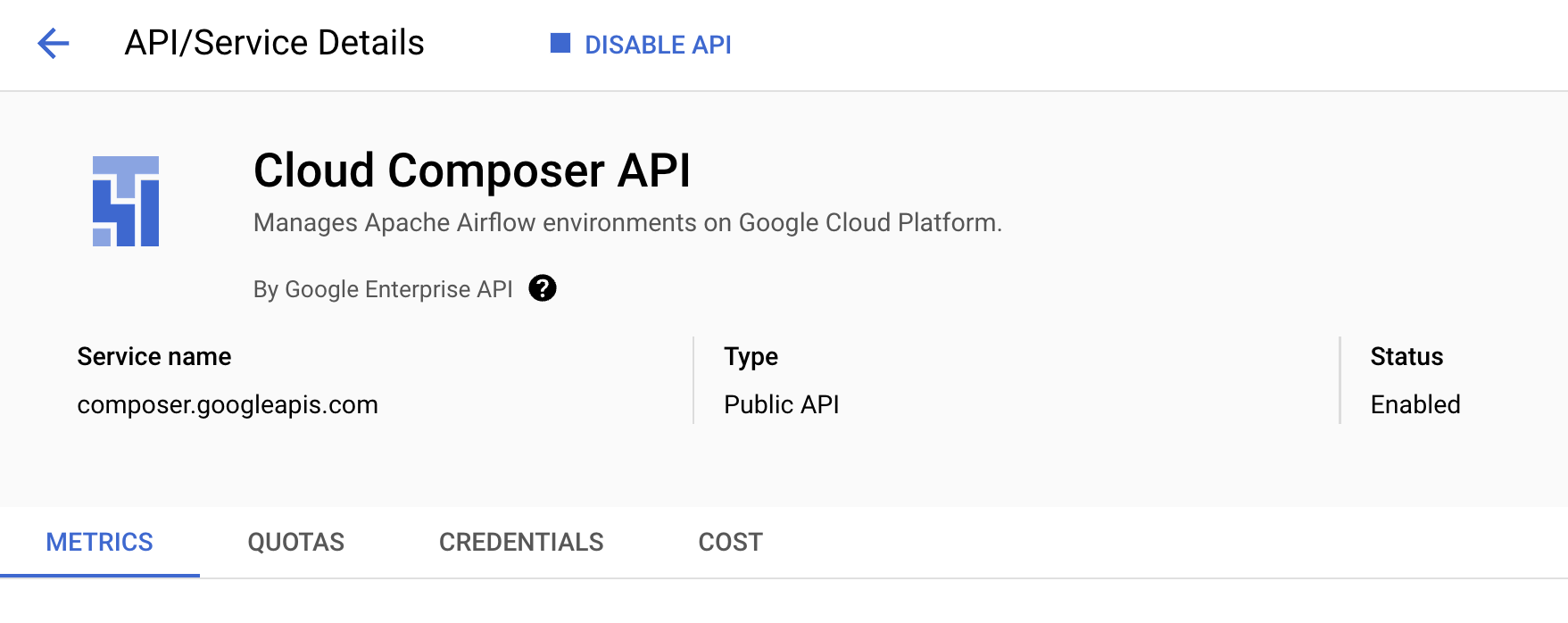
Ensure that the Cloud Composer API is successfully enabled
To ensure access to the necessary APIs, restart the connection to the Cloud Composer API.
-
In the Google Cloud Console, enter Cloud Composer API in the top search bar.
-
Click on the result for Cloud Composer API.
-
Click Manage.
-
Click Disable API.
If asked to confirm, click Disable.
- Click Enable.
When the API has been enabled again, the page will show the option to disable.
Assign IAM roles on Service Account
-
Navigate to the IAM & Admin > IAM (Identity and Access Management) page in the Google Cloud Console.
-
Find the checkbox labeled Include Google-provided role grants on the right side of the page and click on it to enable it.
-
Locate the principal named service-(project-number)cloudcomposer-accounts.iam.gserviceaccount.com.
-
Next to the principal's name, you'll find the role titled Cloud Composer API Service Agent. Click on the pencil icon next to it.
-
In the dialog that opens, click on the Add role button.
-
Search for and select the Cloud Composer v2 API Service Agent Extension role from the list.
-
Click on the Save button to apply the changes.
Create your Cloud Composer environment
Your Cloud Composer environment must be created before you set up your Apache Airflow.
Since it takes over 15 minutes to create the Composer environment, you will start creating the environment, and then, while the environment is building, continue to the next sections and review the tools and concepts in the "Introduction" section, and the DAG code in the "Sample workflow" section.
- Enter the following command to create the Composer environment:
Click Check my progress to verify the objective.
What is Cloud Composer?
Cloud Composer is a fully managed workflow orchestration service that empowers you to author, schedule, and monitor pipelines that span across clouds and on-premises data centers. Built on the popular Apache Airflow open source project and operated using the Python programming language, Cloud Composer is free from lock-in and easy to use.
By using Cloud Composer instead of a local instance of Apache Airflow, users benefit from the best of Airflow with no installation and management overhead.
What is Apache Airflow?
Apache Airflow is an open source tool used to programatically author, schedule, and monitor workflows. There are a few key terms to remember relating to Airflow for this lab:
- DAG - a DAG (Directed Acyclic Graph) is a collection of organized tasks that you schedule and run. DAGs, also called workflows, are defined in standard Python files
- Operator - an Operator describes a single task in a workflow
What is Cloud Dataproc?
Cloud Dataproc is Google Cloud's fully-managed Apache Spark and Apache Hadoop service. Cloud Dataproc easily integrates with other Google Cloud services, giving you a powerful and complete platform for data processing, analytics and machine learning.
Task 1. Sample workflow
Take a look at the code for the DAG executed in this lab. In this section, don't worry about downloading files, just follow along.
There's a lot to unpack, so review a little of the code at a time.
Start off with some Airflow imports:
-
airflow.models- allows you to access and create data in the Airflow database. -
airflow.contrib.operators- where operators from the community live. In this case, you need thedataproc_operatorto access the Cloud Dataproc API. -
airflow.operators.BashOperator- allows you to schedule bash commands. -
airflow.utils.trigger_rule- for adding trigger rules to our operators. Trigger rules allow fine-grain control over whether an operator should execute in regards to the status of its parents.
-
WORDCOUNT_JAR- location of the jar file you eventually run on the Cloud Dataproc cluster. It is already hosted on Google Cloud for you. -
input_file- location of the file containing the data your Apache Hadoop job will eventually compute on. In this lab, you upload the data to that location. -
wordcount_args- arguments you pass into the jar file.
This gives you a datetime object equivalent representing midnight on the previous day. For instance, if this is executed at 11:00 on March 4th, the datetime object would represent 00:00 on March 3rd. This has to do with how Airflow handles scheduling. More info on that can be found in the Scheduler documentation.
This specifies the location of your output file. The notable line here is models.Variable.get('gcs_bucket') which will grab the gcs_bucket variable value from the Airflow database.
The default_dag_args variable in the form of a dictionary should be supplied whenever a new DAG is created:
-
'email_on_failure'- lets Airflow know whether or not to send an email to the DAG owner if the DAG fails for any reason. -
'email_on_retry'-lets Airflow know whether or not to send an email to the DAG owner if the DAG fails for any reason. -
'retries' -denotes how many attempts Airflow should make if a DAG fails. -
'retry_delay'-denotes how long Airflow should wait before attempting a retry. -
'project_id'- tells the DAG what Project ID to associate it with, which will be needed later with the Dataproc Operator.
Using with models.DAG tells the script to include everything below it inside of the same DAG. You also see three arguments passed in:
- The first, which is a string, is the name to give the DAG that we're creating. In this case, we're using
composer_sample_quickstart. -
schedule_interval- adatetime.timedeltaobject, which here are set to one day. This means that this DAG will attempt to execute once a day after the'start_date'that was set earlier in'default_dag_args'. -
default_args- the dictionary you created earlier containing the default arguments for the DAG.
Check that the input file exists
- Here, you create your first operator! You create a
BashOperatorwhich has Airflow trigger a bash command:
You execute a command to determine whether or not your input file exists. As the rest of our workflow is dependent on the existence of this file, if the operator determines that the file does not exist, which is based on the exit code of the command, Airflow won't kick off the rest of the workflow. You provide the operator two input parameters:
-
task_id- the name assigned to the operator, which is viewable from the Airflow UI. -
bash_command- the bash command you want the operator to execute.
Create a Dataproc Cluster
- Next, you create a
dataproc_operator.DataprocClusterCreateOperator, which creates a Cloud Dataproc Cluster:
There are a few arguments within this operator, all but the first are specific to this operator:
-
task_id- just like in theBashOperator, this is the name you assign to the operator, which is viewable from the Airflow UI. -
cluster_name- is the name you assign the Cloud Dataproc cluster. Here, you've named itquickstart-cluster-{{ ds_nodash }}(see info box for optional additional information). -
num_workers- is the number of workers you allocate to the Cloud Dataproc cluster. -
zone- is the geographical region in which you wish for the cluster to live, as saved within the Airflow database. This will read the'gce_zone'variable you previously set. -
master_machine_type- is the type of machine to allocate to the Cloud Dataproc master. -
worker_machine_type- is the type of machine to allocate to the Cloud Dataproc worker.
cluster_name variable
The {{ ds_nodash }} part of the parameter is there because Airflow supports jinja2 templating. It is a parameter that gets rendered by Airflow at runtime every time the operator kicks off. In this case, {{ ds_nodash }} gets replaced with the execution_date of the DAG in YYYYMMDD format.
Submit an Apache Hadoop job
- The
dataproc_operator.DataProcHadoopOperatorallows you to submit a job to a Cloud Dataproc cluster:
There are several parameters:
-
task_id- the name you assign to this piece of the DAG. -
main_jar- the location of the jar file you run against the cluster. -
cluster_name- the name of the cluster to run the job against, which you'll notice is identical to what you find in the previous operator. -
arguments- the arguments that get passed into the jar file, as you would if executing the jar file from the command line.
Delete the cluster
- The last operator you create is the
dataproc_operator.DataprocClusterDeleteOperator:
As the name suggests, this operator deletes a given Cloud Dataproc cluster. There are several arguments:
-
task_id- just like in theBashOperator, this is the name assigned to the operator, which is viewable from the Airflow UI. -
cluster_name- the name assigned the Cloud Dataproc cluster. Here, we've named itquickstart-cluster-{{ ds_nodash }}(see info box after "Create a Dataproc Cluster" for optional additional information). -
trigger_rule- Trigger Rules were mentioned briefly during the imports at the beginning of this step, but here you have one in action. By default, an Airflow operator does not execute unless all of its upstream operators have successfully completed. TheALL_DONEtrigger rule only requires that all upstream operators have completed, regardless of whether or not they were successful. Here this means that even if the Apache Hadoop job failed, you still want to tear the cluster down.
Lastly, you want these operators to execute in a particular order, and you can use Python bitshift operators to denote this. In this case, check_file_existence always executes first, followed by create_dataproc_cluster, run_dataproc_hadoop, and finally, delete_dataproc_cluster. You might agree that this order feels natural.
- Putting it all together, the code looks like this:
Task 2. Verify the Composer environment
When the Composer environment is created, you see "done".
Output:
View the Composer environment in Cloud Console
The Environment details page provides information, such as the Airflow web interface URL, Google Kubernetes Engine cluster ID, name of the Cloud Storage bucket, and path for the /dags folder.
In Airflow, a DAG (Directed Acyclic Graph) is a collection of organized and scheduled tasks. DAGs, also called workflows, are defined in standard Python files. Cloud Composer only schedules the DAGs in the /dags folder. The /dags folder is in the Cloud Storage bucket that Cloud Composer creates automatically when you create your environment.
View the environment details in the Cloud Console:
-
Select Navigation menu > Composer and then click
my-composer-environmentin the Filter environment list. -
Click on the Environment Configuration tab.
-
Record the DAGs folder value to use later in the lab as
<your-dags-folder>(the location of your/dagsfolder).
Create a Cloud Storage bucket
Create a Cloud Storage bucket in your project. This bucket will be used to store output of the Hadoop job from Dataproc.
- Run the following command in Cloud Shell to create a Cloud Storage bucket named after your project ID:
Click Check my progress to verify the objective.
Task 3. Set up Apache Airflow environment variables
Apache Airflow variables are an Airflow-specific concept that is distinct from environment variables.
In this step, you set the following three Airflow variables: gcp_project, gcs_bucket, and gce_zone.
Set variables in Cloud Shell
To set Airflow variables in Cloud Shell using the gcloud command-line tool, use the gcloud composer environments run command with the variables sub-command. This gcloud composer command executes the Airflow CLI sub-command variables. The sub-command passes the arguments to the gcloud command line tool.
Run this command three times, replacing the variables with the ones relevant to your project.
- Run the following command to set the
gcp_projectvariable for your Cloud Composer environment:
- Run the following command to set the
gcs_bucketvariable for your Cloud Composer environment:
- Run the following command to set the
gce_zonevariable for your Cloud Composer environment:
(Optional) Using gcloud to view a variable
- To see the value of a variable, run the Airflow CLI sub-command variables with the
getargument. For example:
You can do this with any of the three variables you just set: gcp_project, gcs_bucket, and gce_zone.
Task 4. Upload Airflow files to Cloud storage
Copy the DAG to your /dags folder
- Run the following commands to copy codelab.py from a public Cloud Storage bucket into your home directory and then change the
<region>placeholder to the region where your Composer environment is located.
- Next, copy the file to your Cloud Composer environment's
/dagsfolder. Replace<your-dags-folder>with the location of your/dagsfolder (from your Composer environment details, noted in a previous section):
- While you're at it, run this command to set one more Airflow environment variable, which will make it easier for your DAG to access one of its input files. Once again, replace
<your-dags-folder>with the location of your/dagsfolder (from your Composer environment details):
Click Check my progress to verify the objective.
Upload Data or Other Files to Cloud Storage
Now upload the input data used in the Hadoop job.
- The following command pulls a publicly available file and move it into the
/dagsbucket in the Airflow environment:
Click Check my progress to verify the objective.
Task 5. Using the Airflow web interface
To access the Airflow web interface, in the console:
- In the console, go back to the Environments page. (Or select Navigation menu > Composer.)
- Click Airflow. The Airflow web interface opens in a new browser window.
For information about the Airflow UI, refer to Accessing the web interface.
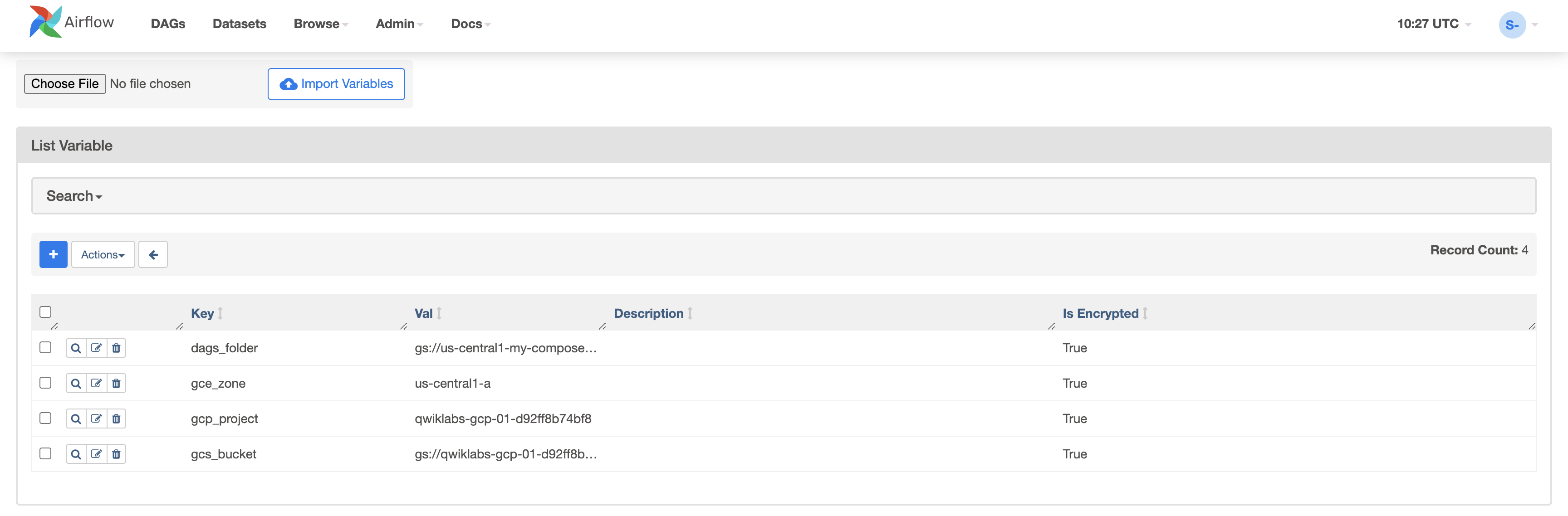
View variables
The variables you set earlier persist in your environment.
- View the variables by selecting Admin > Variables from the Airflow web interface menu bar.
Exploring DAG Runs
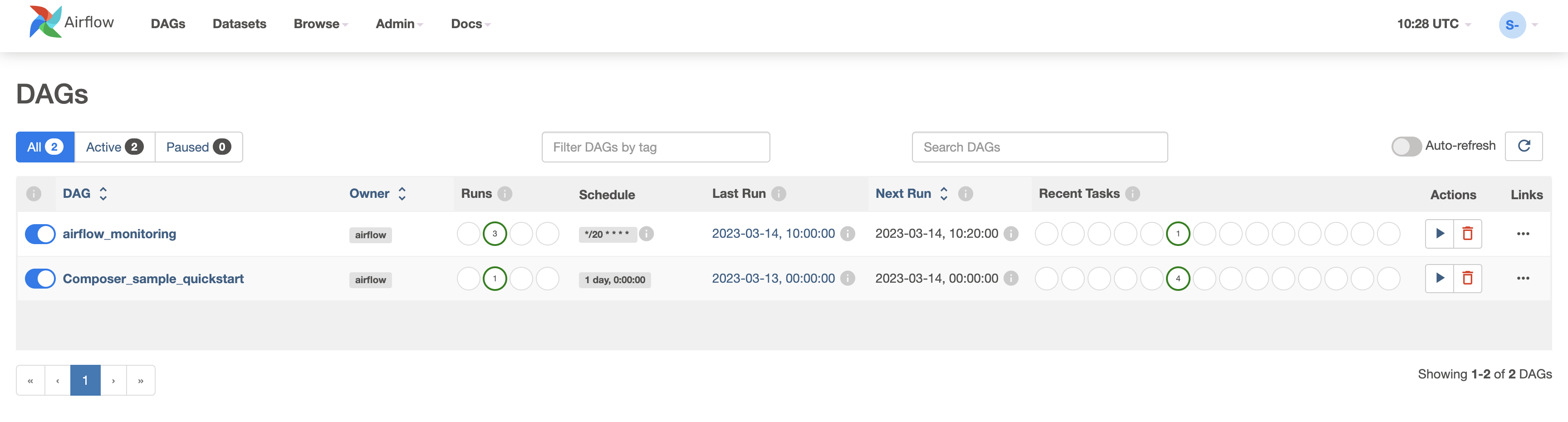
When you upload your DAG file to the dags folder in Cloud Storage, Cloud Composer parses the file. If no errors are found, the name of the workflow appears in the DAG listing, and the workflow is queued to run immediately.
- To look at your DAGs, be sure you're on the DAGs tab in the Airflow web interface. It takes several minutes for this process to complete. Refresh your browser to be sure you're looking at the latest information.
-
Click
Composer_sample_quickstartto open the DAG details page. -
In the toolbar, click Graph view and then mouseover the graphic for each task to see its status. The border around each task also indicates the status (green border = running; red = failed, etc.).
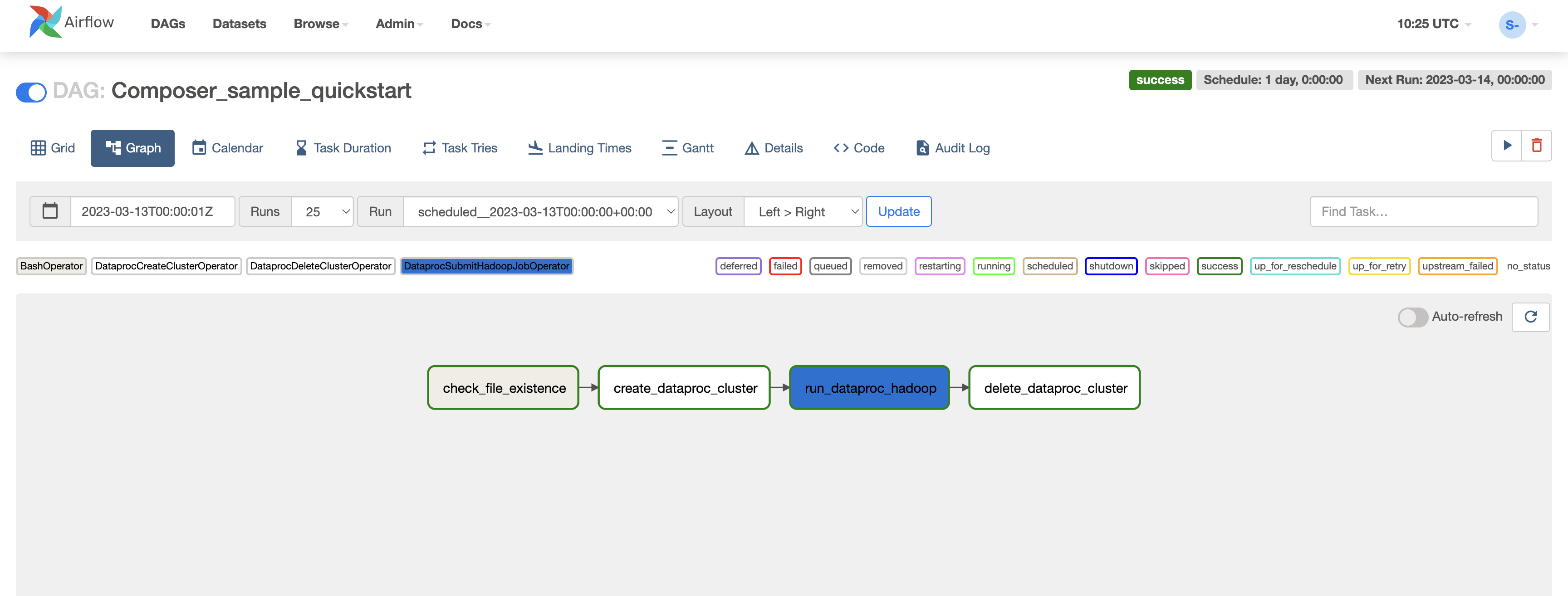
- Click the Refresh icon to be sure you're looking at the most recent information. If the status changes, the boarders of the processes change colors.
The icon "Success" displays when your process reaches the Success state. While you wait explore the Airflow web interface.
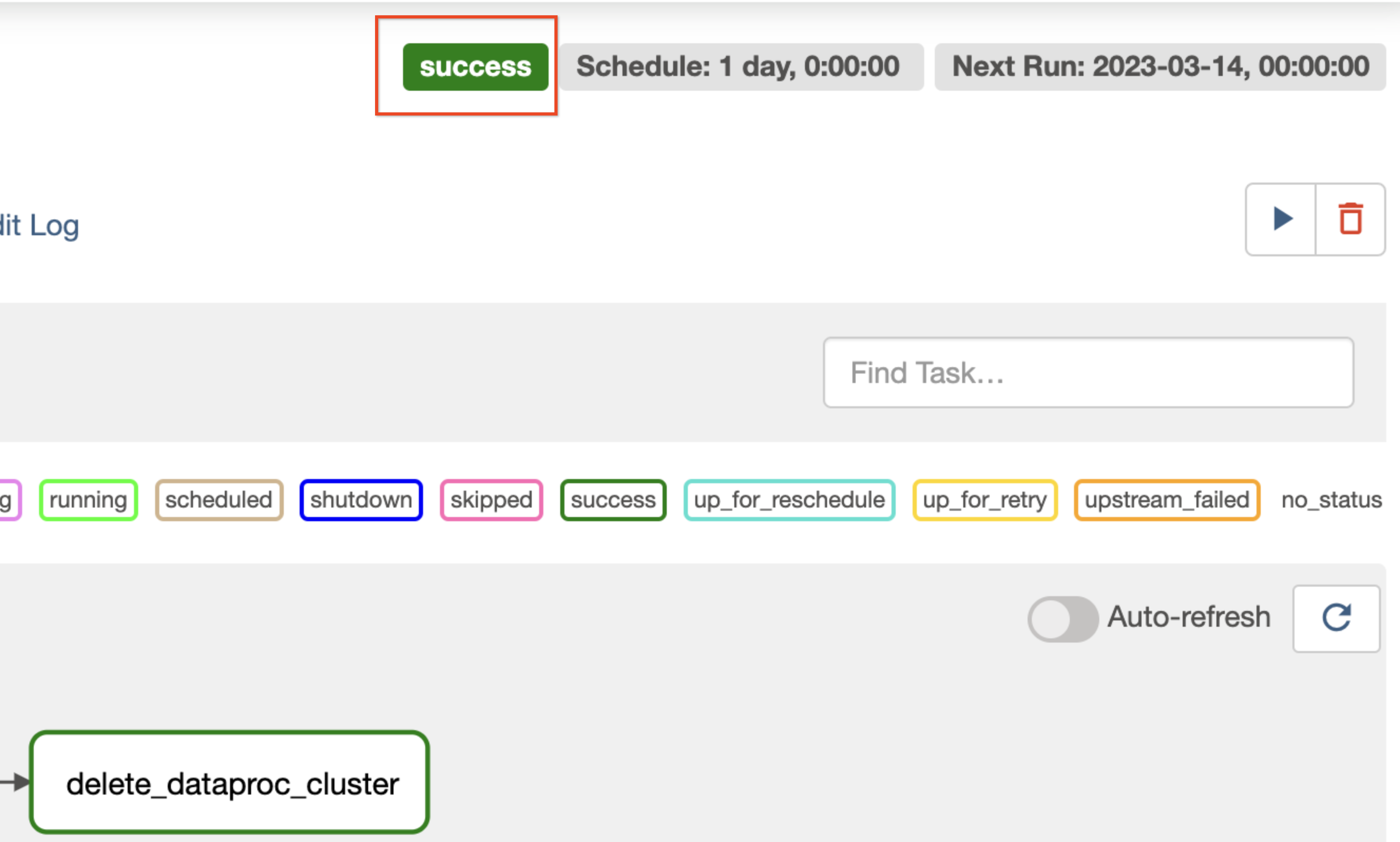
After your process reached the Success state, run the workflow again from the Graph view:
- In the Airflow UI Graph View, click the
check_file_existencegraphic. - Click Clear to reset the three tasks and then click OK to confirm.
After you reset the process, it automatically starts again. The process State should be running. If it is still success, refresh your view.
You can also check the status and results of the Composer-sample-quickstart workflow by going to the following console pages:
- Navigation menu > Dataproc > Clusters to monitor cluster creation and deletion. The cluster created by the workflow is ephemeral: it only exists for the duration of the workflow and is deleted as part of the last workflow task.
- In the left pane of the Dataproc page, click Jobs to view or monitor the Apache Hadoop wordcount job.
- Click the Job ID to see job log output.
See the results
The wordcount results are in the Cloud Storage bucket.
-
Select Navigation menu > Cloud Storage > Buckets and click the bucket name that starts with "qwiklabs-gcp".
-
Navigate to the
wordcount/<date-num>folder. -
Click each file in the folder to download the files, then open with a text editor, for example, Notepad. The file
<xxx_SUCCESS>is empty, but the others have wordcount results.
Sample result:

Delete Cloud Composer Environment
-
Return to the Environments page in Composer.
-
Select the checkbox next to your Composer environment.
-
Click DELETE.
-
Confirm the pop-up by clicking DELETE again.
Congratulations!
You used Cloud Shell command line to set up your Cloud Composer environment, then used Cloud Composer to run a simple workflow that verifies the existence of a data file, creates a Cloud Dataproc cluster, runs an Apache Hadoop wordcount job on the Cloud Dataproc cluster, and deletes the Cloud Dataproc cluster afterwards. Finally you used the GCP Console to view the environment, and retrieve the wordcount results.
Take your next lab
This lab is part of a series of labs called Qwik Starts. These labs are designed to give you a little taste of the many features available with Google Cloud. Search for "Qwik Starts" in the lab catalog to find the next lab you'd like to take!
Or, learn more about Cloud Composer with:
- Launching Dataproc Jobs with Cloud Composer
- Cloud Composer: Copying BigQuery Tables Across Different Locations
Next Steps
- For more information about Cloud Composer, see Cloud Composer Documentation
- For more information about Apache Airflow, see Apache Airflow Documentation.
- For more information about Cloud Dataproc, see Cloud Dataproc documentation.
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated March 11, 2024
Lab Last Tested March 11, 2024
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.