Points de contrôle
Build simple a REST API
/ 20
Create a Revision for Cloud Run
/ 20
Create two cloud storage buckets
/ 10
Create a Pub/Sub topic for receiving notification from storage bucket
/ 10
Create a Pub/Sub subscription
/ 10
Create another build for REST API
/ 15
Create a new Revision
/ 15
Créer une application sans serveur qui permet de produire des fichiers PDF à l'aide de Cloud Run
- GSP644
- Présentation
- Préparation
- Tâche 1 : Comprendre la tâche
- Tâche 2 : Activer l'API Cloud Run
- Tâche 3 : Déployer un service Cloud Run simple
- Tâche 4 : Déclencher votre service Cloud Run lorsqu'un nouveau fichier est importé
- Tâche 5 : Vérifier si le service Cloud Run est déclenché lorsque les fichiers sont importés dans Cloud Storage
- Tâche 6 : Conteneurs Docker
- Tâche 7 : Tester le service de convertisseur PDF
- Félicitations !
GSP644


Présentation
Dans le cadre des ateliers de la quête Google Cloud Serverless Workshop: Pet Theory, vous allez découvrir un scénario métier fondé sur une entreprise fictive et aider les protagonistes à migrer vers une technologie sans serveur.
Il y a 12 ans, Lily a créé une chaîne de cliniques vétérinaires appelée Pet Theory. Actuellement, Pet Theory envoie des factures au format DOCX à ses clients, mais de nombreux clients se sont plaints de ne pas pouvoir les ouvrir. Afin d'améliorer la satisfaction client, Lily a demandé à Patrick, du service informatique, d'étudier une alternative pour améliorer la situation actuelle.
L'équipe de développement de Pet Theory étant composée d'une seule personne, elle est désireuse d'investir dans une solution rentable qui ne nécessite pas beaucoup de maintenance. Après avoir analysé les différentes options de traitement, Patrick décide d'utiliser Cloud Run.
Cloud Run est sans serveur, ce qui permet d'éliminer toute la gestion de l'infrastructure et de se concentrer sur la création de l'application sans se soucier des coûts. En tant que produit Google sans serveur, il peut faire l'objet d'un scaling à zéro instance, ce qui signifie qu'il n'entraîne aucuns frais lorsqu'il n'est pas utilisé. Il vous permet également d'utiliser des packages binaires personnalisés basés sur des conteneurs, ce qui signifie qu'il est désormais possible de créer des artefacts isolés et cohérents.
Dans cet atelier, vous allez créer une application Web de conversion en PDF sur Cloud Run, qui convertit automatiquement les fichiers stockés dans Cloud Storage en PDF stockés dans des dossiers séparés.
Architecture
Ce schéma présente les services que vous allez utiliser et la manière dont ils se connectent les uns aux autres :
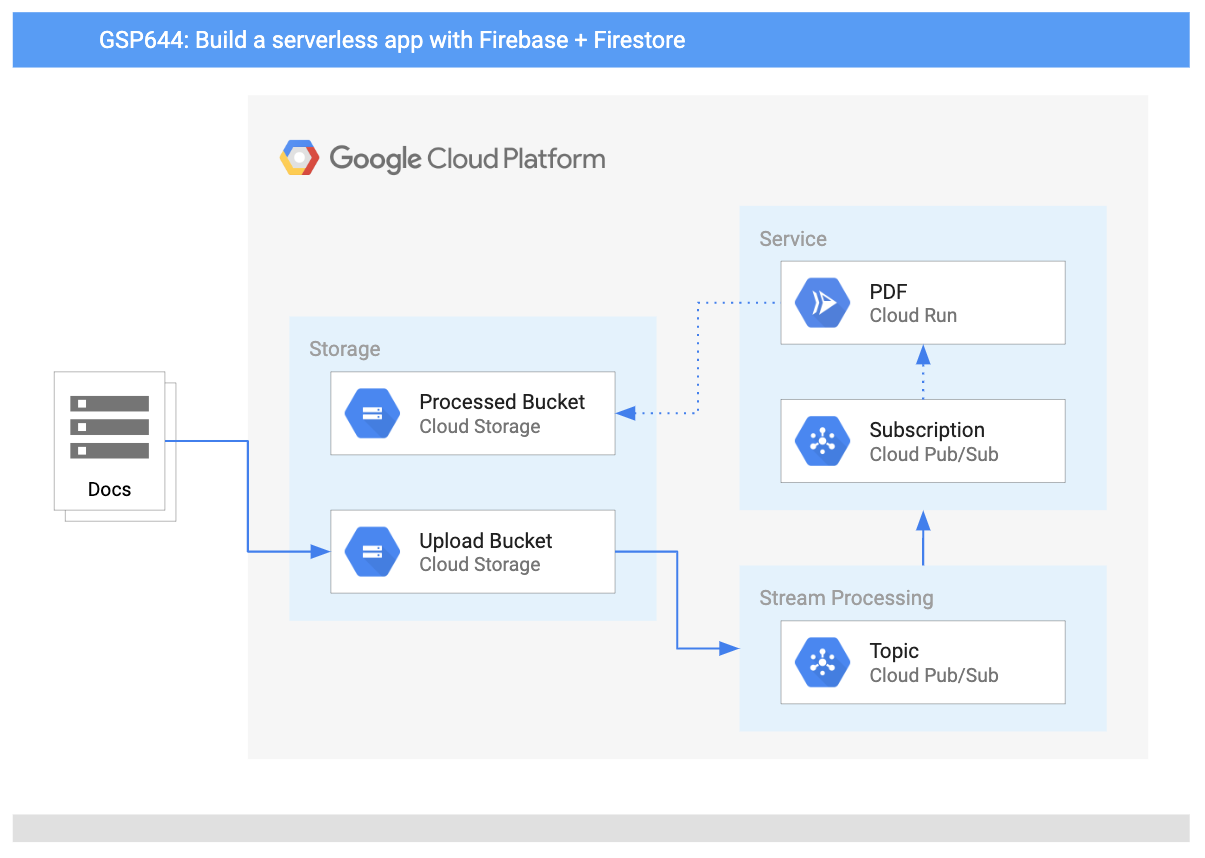
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Convertir une application Node.js vers un conteneur
- Créer des conteneurs avec Google Cloud Build
- Créer un service Cloud Run qui convertit des fichiers en PDF dans le cloud
- Utiliser le traitement des événements avec Cloud Storage
Prérequis
Cet atelier s'adresse aux utilisateurs de niveau intermédiaire qui maîtrisent déjà la console et les environnements shell. Connaître Firebase est utile, mais n'est pas obligatoire. Avant de commencer cet atelier, il est recommandé d'avoir suivi les ateliers Google Cloud Skills Boost suivants :
- Importer des données dans une base de données Firestore
- Créer une application Web sans serveur à l'aide de Firebase
Vous devez également savoir modifier des fichiers. Vous pouvez utiliser votre éditeur de texte préféré (comme nano, vi, etc.) ou lancer l'éditeur de code de Cloud Shell, qui se trouve dans le ruban supérieur :
Lorsque vous êtes prêt, faites défiler la page vers le bas et suivez les indications pour passer à la configuration de l'environnement de votre atelier.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Comprendre la tâche
Pet Theory voudrait convertir ses factures en PDF pour que les clients puissent les ouvrir de manière fiable. L'équipe veut réaliser cette conversion automatiquement pour minimiser la charge de travail de Lisa, la responsable des services administratifs.
Ruby, la consultante en informatique de Pet Theory, reçoit un message de Patrick, du service informatique...
|
Patrick, Administrateur informatique |
Bonjour Ruby, J'ai fait quelques recherches et j'ai trouvé que LibreOffice est efficace pour convertir de nombreux formats de fichiers différents en PDF. Serait-il possible de faire fonctionner LibreOffice dans le cloud sans avoir à entretenir les serveurs ? Patrick |
|
|
Bonjour Patrick, Je pense que j'ai ce qu'il faut pour ce genre de situation. Je viens de regarder sur YouTube une vidéo très intéressante de Next 2019 sur Cloud Run. Il semble que nous puissions faire fonctionner LibreOffice dans un environnement sans serveur avec Cloud Run. Aucune maintenance du serveur n'est nécessaire ! Je vais vous envoyer des ressources qui vous aideront à le mettre en place. Ruby |

 Ruby, Consultante en logiciels
Ruby, Consultante en logicielsAidez Patrick à mettre en place et à déployer Cloud Run.
Tâche 2 : Activer l'API Cloud Run
-
Ouvrez le menu de navigation (
), puis cliquez sur API et services > Bibliothèque. Dans la barre de recherche, saisissez "Cloud Run" et sélectionnez l'API Cloud Run dans la liste des résultats.
-
Cliquez sur Activer, puis appuyez deux fois sur le bouton "Retour" de votre navigateur. La page doit se présenter comme suit :
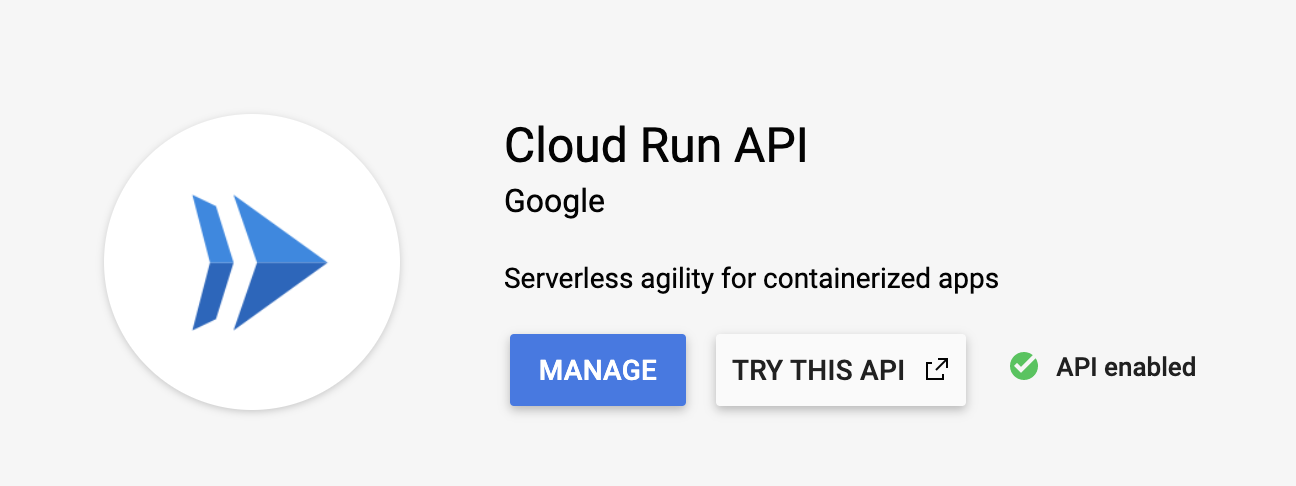
Tâche 3 : Déployer un service Cloud Run simple
Ruby a développé un prototype de Cloud Run et aimerait que Patrick le déploie sur Google Cloud. Aidez maintenant Patrick à mettre en place le service PDF Cloud Run pour Pet Theory.
- Ouvrez une nouvelle session Cloud Shell et exécutez la commande suivante pour cloner le dépôt de Pet Theory :
- Changez ensuite votre répertoire de travail actuel en lab03 :
- Modifiez
package.jsonavec l'éditeur de code Cloud Shell ou votre éditeur de texte préféré. Dans la section "scripts", ajoutez"start": "node index.js",, comme indiqué ci-dessous :
- Exécutez maintenant les commandes suivantes dans Cloud Shell pour installer les packages que votre script de conversion utilisera :
- Ouvrez maintenant le fichier
lab03/index.jset vérifiez le code.
L'application sera déployée comme un service Cloud Run qui accepte les POST HTTP. Si la requête POST est une notification Pub/Sub concernant un fichier importé, le service écrit les détails du fichier dans le journal. Sinon, le service renvoie simplement la chaîne "OK".
- Examinez le fichier nommé
lab03/Dockerfile.
Le fichier ci-dessus est appelé un manifeste et fournit une recette pour la commande Docker pour construire une image. Chaque ligne commence par une commande qui indique à Docker comment traiter les informations suivantes :
- La première ligne indique que l'image de base doit utiliser le nœud v12 comme modèle pour l'image à créer.
- La dernière ligne indique la commande à exécuter, qui dans ce cas fait référence à "npm start".
- Pour construire et déployer l'API REST, utilisez Google Cloud Build. Exécutez cette commande pour lancer le processus de compilation :
La commande construit un conteneur avec votre code et le place dans le Container Registry de votre projet.
- Revenez à la console Cloud, ouvrez le menu de navigation et sélectionnez Container Registry > Images. Vous devriez voir votre conteneur hébergé :
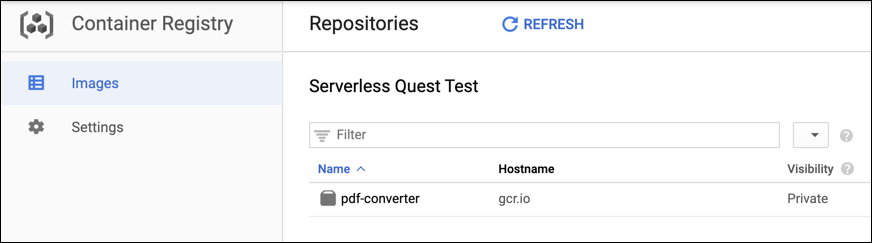
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
- Retournez à votre onglet d'éditeur de code et dans Cloud Shell, exécutez la commande suivante pour déployer votre application :
- Une fois le déploiement terminé, un message de ce type s'affiche :
- Créez la variable d'environnement
$SERVICE_URLpour l'application afin de pouvoir y accéder facilement :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
- Effectuez une requête POST anonyme à votre nouveau service :
Cela entraînera un message d'erreur indiquant "Your client does not have permission to get the URL" ("Votre client n'a pas la permission d'obtenir l'URL"). En effet, vous ne voulez pas que le service puisse être appelé par des utilisateurs anonymes.
- Essayez maintenant d'appeler le service en tant qu'utilisateur autorisé :
Si vous obtenez la réponse "OK", vous avez correctement déployé un service Cloud Run. Félicitations !
Tâche 4 : Déclencher votre service Cloud Run lorsqu'un nouveau fichier est importé
Maintenant que le service Cloud Run a été correctement déployé, Ruby aimerait que Patrick crée une zone de préproduction pour les données à convertir. Le bucket Cloud Storage va utiliser un déclencheur d'événement pour notifier l'application lorsqu'un fichier a été téléchargé et doit être traité.
- Exécutez la commande suivante pour créer un bucket dans Cloud Storage pour les documents importés :
- Et un autre bucket pour les PDF traités :
- Revenez maintenant à l'onglet de la console Cloud, ouvrez le menu de navigation et sélectionnez Cloud Storage. Vérifiez que les buckets ont été créés (il y aura également d'autres buckets utilisés par la plate-forme).
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
- Dans Cloud Shell, exécutez la commande suivante pour indiquer à Cloud Storage d'envoyer une notification Pub/Sub chaque fois qu'un nouveau fichier a fini d'être importé dans le bucket docs :
Les notifications seront étiquetées avec le sujet "new-doc".
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
- Créez ensuite un nouveau compte de service que Pub/Sub utilisera pour déclencher les services Cloud Run :
- Donnez au nouveau compte de service l'autorisation d'appeler le service de convertisseur PDF :
- Trouvez votre numéro de projet en exécutant cette commande :
Cherchez le projet dont le nom commence par "qwiklabs-gcp-". Vous utiliserez la valeur du numéro de projet dans la prochaine commande.

- Créez une variable d'environnement
PROJECT_NUMBER, en remplaçant [numéro de projet] par le numéro de projet de la dernière commande :
- Ensuite, activez votre projet pour créer des jetons d'authentification Cloud Pub/Sub :
Service account does not exist (Aucun compte de service n'existe.) lors de l'exécution de la commande ci-dessus : activez l'API Cloud Pub/Sub, et si elle est déjà activée, commencez par la désactiver, puis réactivez-la. Ensuite, exécutez à nouveau la commande ci-dessus.
- Enfin, créez un abonnement Pub/Sub pour que le convertisseur PDF puisse fonctionner à chaque fois qu'un message est publié sur le thème "new-doc".
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
Tâche 5 : Vérifier si le service Cloud Run est déclenché lorsque les fichiers sont importés dans Cloud Storage
Pour vérifier que l'application fonctionne comme prévu, Ruby demande à Patrick d'importer quelques données de test dans le bucket de stockage nommé, puis d'accéder à Cloud Logging.
- Copiez quelques fichiers de test dans votre bucket d'importation :
-
Une fois l'importation terminé, revenez à l'onglet de la console Cloud, ouvrez le menu de navigation et sélectionnez Logging dans la section "Opérations".
-
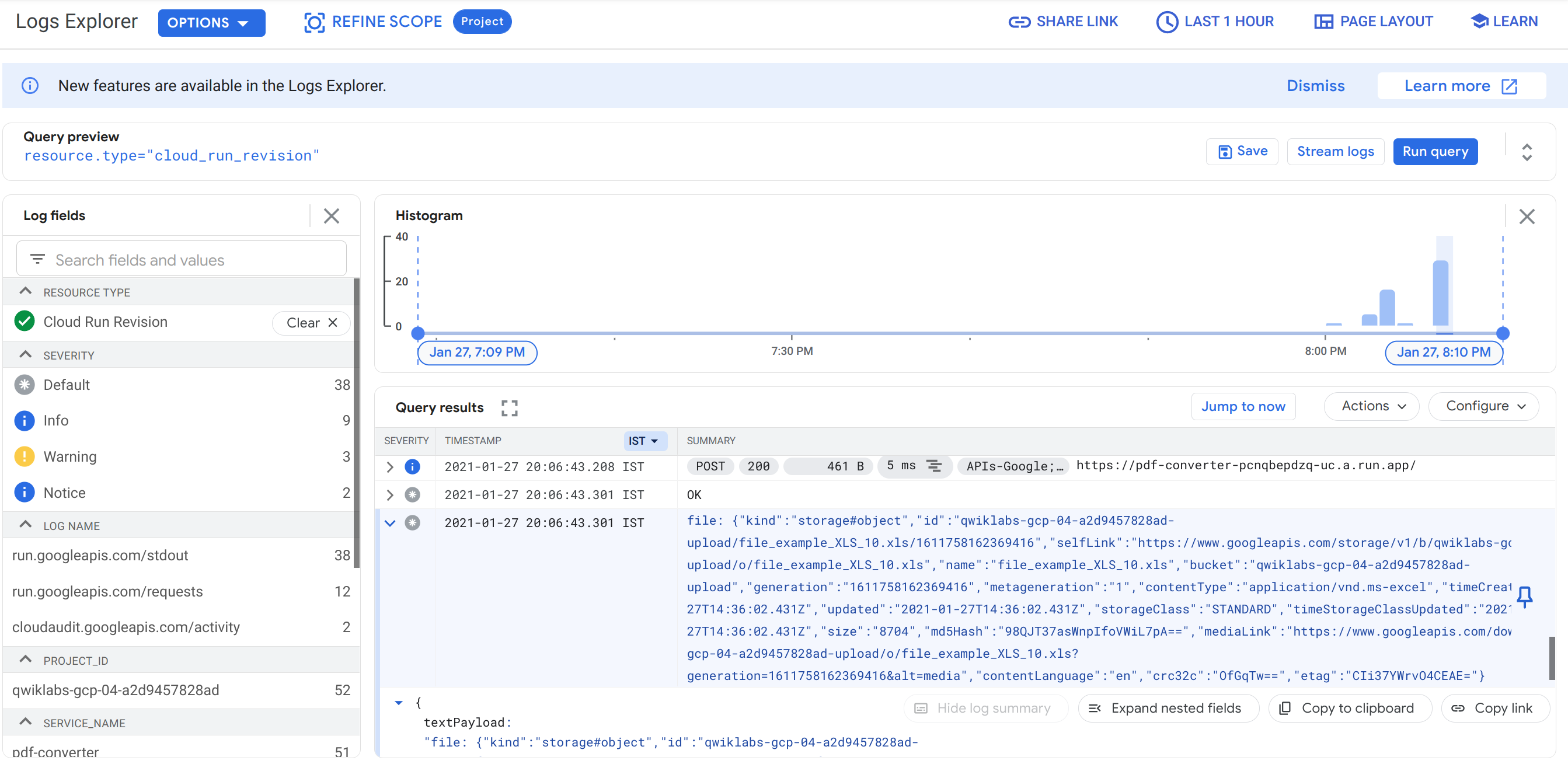
Dans le menu déroulant Ressource, appliquez le filtre Révision dans Cloud Run, puis cliquez sur Appliquer. Cliquez ensuite sur Exécuter la requête.
-
Dans les résultats de la requête, recherchez une entrée de journal qui commence par
file:, puis cliquez dessus. Elle affiche un vidage des données du fichier que Pub/Sub envoie à votre service Cloud Run lorsqu'un nouveau fichier est importé. -
Pouvez-vous trouver le nom du fichier que vous avez importé dans cet objet ?
- Retournez ensuite à l'onglet de l'éditeur de code et exécutez la commande suivante dans Cloud Shell pour nettoyer votre répertoire
uploaden supprimant les fichiers qu'il contient :
Tâche 6 : Conteneurs Docker
Patrick doit convertir des factures en attente en PDF pour que tous les clients puissent les ouvrir. Il envoie un e-mail à Ruby pour obtenir de l'aide...
|
Patrick, Administrateur informatique |
Bonjour Ruby Sur la base de tes conclusions, je pense que nous pouvons automatiser ce processus et passer à l'utilisation du format PDF comme format de facture. J'ai passé un peu de temps hier à coder une solution et j'ai construit un script Node.js pour faire ce dont nous avons besoin. Pourrais-tu y jeter un coup d'œil ? Patrick |

Patrick envoie à Ruby le fragment de code qu'il a écrit pour produire un PDF à partir d'un fichier :
Ruby répond à Patrick...
|
Ruby, Consultante en logiciels |
Bonjour Patrick Cloud Run utilise des conteneurs, nous devons donc fournir ton application dans ce format. Pour l'étape suivante, nous devons créer un manifeste Dockerfile pour l'application. Ton code utilise LibreOffice. Pourrais-tu m'envoyer la commande d'installation de ce logiciel ? Je vais devoir l'inclure dans le conteneur. Ruby |
|
Patrick, Administrateur informatique |
Bonjour Ruby Génial, voici comment j'installe habituellement LibreOffice sur les serveurs du bureau :
N'hésite pas à me contacter si tu as d'autres questions. Patrick |
La construction du conteneur nécessitera l'intégration d'un certain nombre de composants :
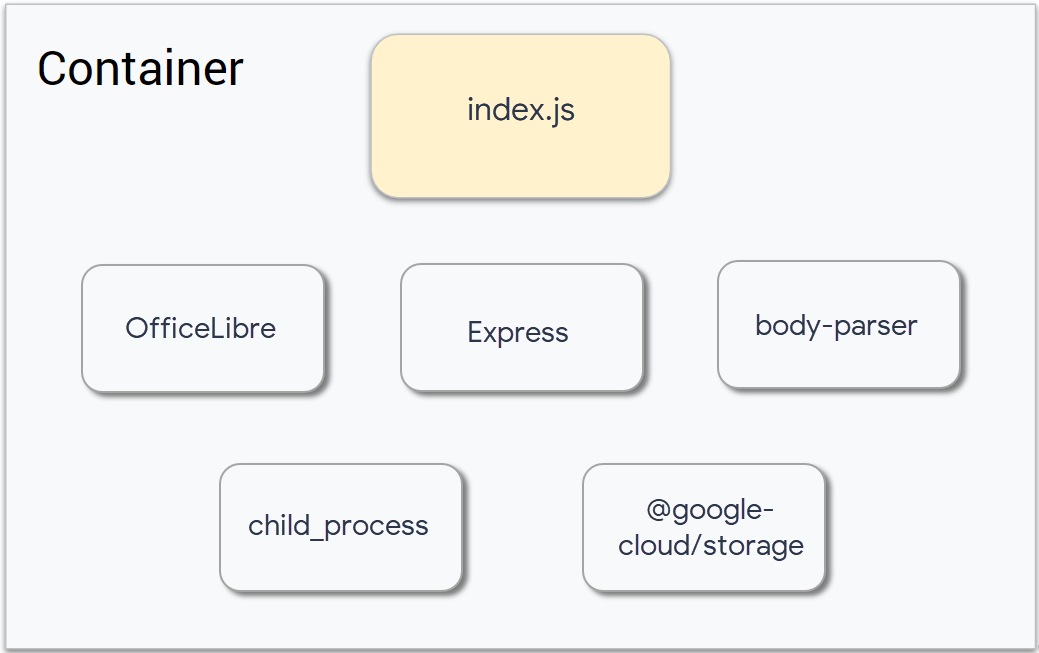
Mettre à jour le conteneur Docker
Une fois tous les fichiers identifiés, le Dockerfile peut maintenant être créé. Aidez Ruby à mettre en place et à déployer le conteneur.
Le package pour LibreOffice n'était pas inclus dans le conteneur auparavant, ce qui signifie qu'il doit maintenant être ajouté. Patrick a déjà fourni les commandes qu'il utilise pour construire son application, Ruby les ajoutera en tant que commande RUN dans le Dockerfile.
- Ouvrez le manifeste
Dockerfileet ajoutez la ligne commandeRUN apt-get update -y && apt-get install -y libreoffice && apt-get cleancomme indiqué ci-dessous :
Déployer la nouvelle version du service de convertisseur PDF
- Ouvrez le fichier
index.jset ajoutez les exigences de package suivantes en haut du fichier :
-
Remplacez
app.post('/', async (req, res)par le code suivant :
- Ajoutez maintenant le code suivant qui traite les documents LibreOffice au bas du fichier :
- Assurez-vous que votre fichier
index.jsressemble à ce qui suit :
index.js par cet exemple de code.
- La logique principale est hébergée dans ces fonctions :
Chaque fois qu'un fichier a été importé, ce service est déclenché. Il effectue ces tâches, une par ligne de la fonction ci-dessus :
- Il extrait les détails du fichier de la notification Pub/Sub.
- Il télécharge le fichier du Cloud Storage sur le disque dur local. Il ne s'agit pas d'un disque physique, mais d'une section de mémoire virtuelle qui se comporte comme un disque.
- Il convertit le fichier téléchargé en PDF.
- Il importe le fichier PDF sur Cloud Storage. La variable d'environnement
process.env.PDF_BUCKETcontient le nom du bucket Cloud Storage dans lequel enregistrer des PDF. Vous attribuerez une valeur à cette variable lorsque vous déploierez le service ci-dessous. - Il supprime le fichier original de Cloud Storage.
Le reste du fichier index.js implémente les fonctions appelées par ce code de haut niveau.
Il est temps de déployer le service, et de définir la variable d'environnement PDF_BUCKET. Il est aussi conseillé d'octroyer à LibreOffice 2 Go de RAM pour travailler (consultez la ligne avec l'option --memory).
- Exécutez la commande suivante pour créer le conteneur :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour vérifier que vous avez correctement effectué la tâche ci-dessus.
- Déployez maintenant la dernière version de votre application :
Avec la partie LibreOffice du conteneur, cette compilation prendra plus de temps que la précédente. C'est le bon moment pour marquer une pause.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 7 : Tester le service de convertisseur PDF
- Une fois les commandes de déploiement terminées, assurez-vous que le service a été déployé correctement en exécutant :
-
Si vous obtenez la réponse
"OK", vous avez réussi à déployer le service Cloud Run mis à jour. LibreOffice peut convertir de nombreux types de fichiers en PDF : DOCX, XLSX, JPG, PNG, GIF, etc. -
Exécutez la commande suivante pour télécharger quelques fichiers d'exemple :
-
Revenez à la console Cloud, ouvrez le menu de navigation, puis cliquez sur Cloud Storage. Ouvrez le bucket
-uploadet cliquez sur le bouton Actualiser plusieurs fois pour voir comment les fichiers sont supprimés, un par un, au fur et à mesure qu'ils sont convertis en PDF. -
Cliquez ensuite sur Buckets dans le menu de gauche, et sur le bucket dont le nom se termine par "-processed". Il doit contenir les versions PDF de tous les fichiers. N'hésitez pas à ouvrir les fichiers PDF pour vous assurer qu'ils ont été correctement convertis :
-processed, réexécutez la commande.
Félicitations !
Pet Theory dispose désormais d'un système pour convertir ses archives d'anciens fichiers en PDF. En important simplement les anciens fichiers dans le bucket "upload", le service de convertisseur PDF les convertit et les enregistre en PDF dans le bucket "processed".
Terminer votre quête
Cet atelier d'auto-formation fait partie de la quête Serverless Cloud Run Development. Une quête est une série d'ateliers associés qui constituent un parcours de formation. Si vous terminez cette quête, vous obtenez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à cette quête pour obtenir immédiatement les crédits associés. Découvrez toutes les quêtes disponibles dans le catalogue Google Cloud Skills Boost.
Atelier suivant
Continuez sur votre lancée en suivant le prochain atelier de la série, intitulé Créer un système résilient et asynchrone à l'aide de Cloud Run et de Pub/Sub.
Étapes suivantes et informations supplémentaires
En savoir plus sur les conteneurs sans serveur : Vidéo Next 2019 sur YouTube
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 26 octobre 2023
Dernier test de l'atelier : 27 octobre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.