Points de contrôle
Create test data for the Firestore Database
/ 50
Import test data into the Firestore Database
/ 50
Importer des données dans une base de données Firestore
GSP642


Présentation
Dans les ateliers de la quête Google Cloud Serverless Workshop: Pet Theory, vous allez découvrir un scénario métier fondé sur une entreprise fictive et aider les protagonistes à migrer vers une technologie sans serveur.
Il y a 12 ans, Lily a créé une chaîne de cliniques vétérinaires appelée Pet Theory. Pet Theory a connu une expansion rapide ces dernières années. Toutefois, son ancien système de prise de rendez-vous n'étant plus en mesure de gérer l'augmentation de la charge de travail, Lily vous demande de concevoir un système plus évolutif basé sur le cloud.
L'équipe opérationnelle de Pet Theory est composée d'une seule personne, Patrick. La solution ne doit donc pas nécessiter beaucoup de maintenance. L'équipe a opté pour une technologie sans serveur.
Ruby a été engagée comme consultante pour aider Pet Theory à faire la transition vers la solution sans serveur. Après avoir comparé les différentes options de base de données sans serveur, l'équipe a choisi Cloud Firestore. Étant donné que Firestore est sans serveur, il n'est pas nécessaire de provisionner à l'avance la capacité, ce qui signifie qu'il n'y a pas de risque d'avoir des limites de stockage ou d'opérations. Firestore permet de synchroniser les données entre les applications clientes grâce à des écouteurs en temps réel, et peut fonctionner hors connexion pour le mobile et le Web. Il est ainsi possible de créer une application réactive qui fonctionne indépendamment de la latence du réseau ou de la connectivité Internet.
Dans cet atelier, vous allez aider Patrick à télécharger les données existantes de Pet Theory dans une base de données Cloud Firestore. À cet effet, il travaillera en étroite collaboration avec Ruby.
Architecture
Ce schéma présente les services que vous allez utiliser et la manière dont ils se connectent les uns aux autres :
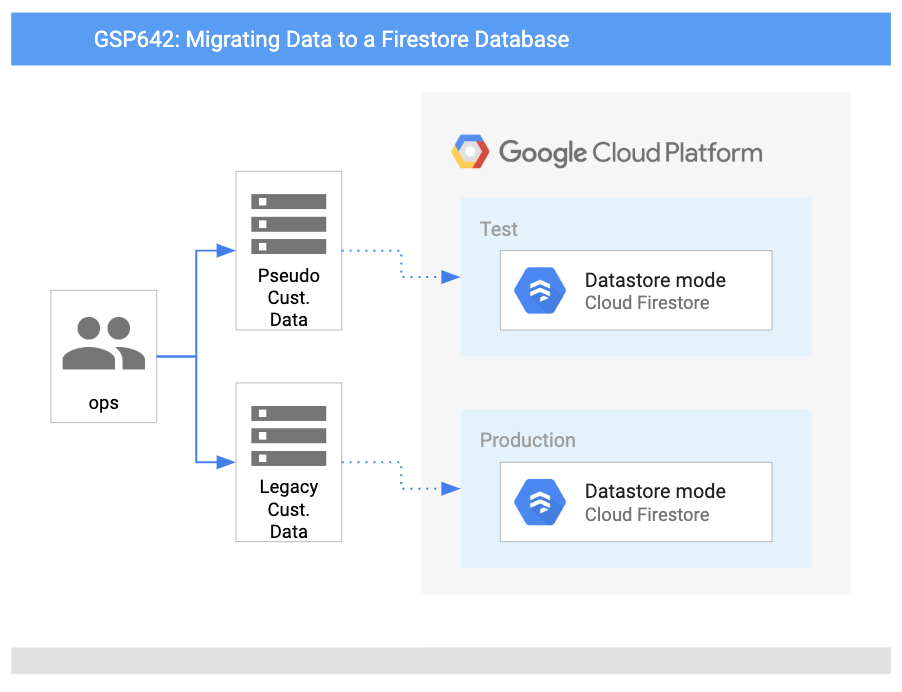
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Configurer Firestore dans Google Cloud
- Rédiger le code d'importation de la base de données
- Générer une collection de données client pour les tests
- Importer des données client de test dans Firestore
Prérequis
Cet atelier s'adresse aux utilisateurs de niveau intermédiaire qui maîtrisent déjà la console Cloud et les environnements de shell. Connaître Firebase peut être utile, mais ce n'est pas requis.
Vous devez également savoir modifier des fichiers. Vous pouvez utiliser votre éditeur de texte préféré (comme nano, vi, etc.) ou lancer l'éditeur de code de Cloud Shell, qui se trouve dans le ruban supérieur :

Lorsque vous êtes prêt, faites défiler la page vers le bas et suivez les indications pour passer à la configuration de l'environnement de votre atelier.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Configurer Firestore dans Google Cloud
La tâche de Patrick consiste à télécharger les données existantes de Pet Theory dans une base de données Cloud Firestore. Il travaillera en étroite collaboration avec Ruby dans ce but. Ruby reçoit un message de Patrick du service informatique...
|
Patrick, Administrateur informatique |
Bonjour Ruby, La première étape pour passer au mode sans serveur consiste à créer une base de données Firestore avec Google Cloud. Pouvez-vous m'aider ? Je n'ai pas beaucoup d'expérience avec ce type de configuration. Patrick |
|
Ruby, Consultante en logiciels |
Bonjour Patrick, Bien sûr, je serais ravie de vous aider. Je vous enverrai quelques ressources pour commencer, puis nous prendrons contact une fois que vous aurez créé la base de données. Ruby |


Aidez Patrick à configurer une base de données Firestore à l'aide de la console Cloud.
-
Dans la console Cloud, accédez au menu de navigation et sélectionnez Firestore.
-
Cliquez sur le bouton Sélectionner "Mode natif".
- Le mode natif permet à un grand nombre d'utilisateurs d'accéder aux mêmes données en même temps. De plus, il offre des fonctionnalités telles que les mises à jour en temps réel et une connexion directe entre votre base de données et un client Web/mobile.
- Le mode Datastore met l'accent sur le haut débit (beaucoup de lectures et d'écritures).
- Dans le menu déroulant Sélectionnez un lieu, sélectionnez
, puis cliquez sur Créer une base de données.
Une fois la tâche accomplie, Ruby envoie un e-mail à Patrick...
|
Ruby, Consultante en logiciels |
Bonjour Patrick, Félicitations pour la configuration de la base de données Firestore ! Pour gérer l'accès à la base de données, nous allons utiliser un compte de service qui a été créé automatiquement avec les droits nécessaires. Nous sommes maintenant prêts à migrer de l'ancienne base de données à Firestore. Ruby |
|
Patrick, Administrateur informatique |
Bonjour Ruby, Merci pour votre aide, la configuration de la base de données Firestore a été simple. J'espère que l'importation dans cette nouvelle base sera moins complexe que l'ancien processus, qui nécessitait de nombreuses étapes. Patrick |

Tâche 2 : Écrire le code d'importation de la base de données
La nouvelle base de données Cloud Firestore est en place, mais elle est vide. Les données relatives aux clients de Pet Theory n'existent toujours que dans l'ancienne base de données.
Patrick envoie un message à Ruby...
|
Patrick, Administrateur informatique |
Bonjour Ruby, Mon responsable souhaiterait commencer à migrer les données des clients vers la nouvelle base de données Firestore. J'ai exporté un fichier CSV depuis l'ancienne base de données, mais je ne sais pas comment importer ces données dans Firestore. Pouvez-vous me donner un coup de main ? Patrick |
|
Ruby, Consultante en logiciels |
Bonjour Patrick, Bien sûr, organisons une réunion pour discuter de la procédure à suivre. Ruby |

Comme l'explique Patrick, les données client seront disponibles dans un fichier CSV. Aidez-le à créer une application qui lit les données clients à partir d'un fichier CSV et les écrit dans Firestore. Puisque Patrick connaît bien JavaScript, créez cette application à l'aide de l'environnement d'exécution JavaScript Node.js.
- Dans Cloud Shell, exécutez la commande suivante pour cloner le dépôt Pet Theory :
- Utilisez l'éditeur de code Cloud Shell (ou votre éditeur préféré) pour modifier les fichiers. Dans le ruban supérieur de votre session Cloud Shell, cliquez sur Ouvrir l'éditeur pour faire apparaître un nouvel onglet. Si vous y êtes invité, cliquez sur Ouvrir dans une nouvelle fenêtre pour lancer l'éditeur de code :
- Passez de votre répertoire de travail actuel au répertoire
lab01:
Dans ce répertoire, vous verrez le fichier package.json de Patrick. Ce fichier répertorie les packages dont dépend votre projet Node.js et rend votre version reproductible, et donc plus facile à partager avec les autres.
Voici un exemple de fichier package.json :
Maintenant que Patrick a importé son code source, il contacte Ruby pour connaître les packages dont il a besoin pour que la migration fonctionne.
|
Patrick, Administrateur informatique |
Bonjour Ruby, Le code que j'utilise pour l'ancienne base de données est assez basique, il crée simplement un fichier CSV à utiliser pour l'importation. Dois-je télécharger quelque chose avant de commencer ? Patrick |
|
Ruby, Consultante en logiciels |
Bonjour Patrick, Je vous conseille d'utiliser l'un des nombreux packages @google-cloud Node pour interagir avec Firestore. Il suffira alors d'apporter de petites modifications au code existant puisque le gros du travail a été fait. Ruby |
Pour permettre au code de Patrick d'écrire dans la base de données Firestore, vous devez installer des dépendances supplémentaires entre pairs.
- Pour ce faire, exécutez la commande suivante :
- Pour permettre à l'application d'écrire des journaux dans Cloud Logging, installez un module supplémentaire :
Une fois la commande terminée, le fichier package.json sera automatiquement mis à jour pour inclure les nouvelles dépendances de pairs, et se présentera comme suit :
Il est maintenant temps d'examiner le script qui lit le fichier CSV des clients et écrit un enregistrement dans Firestore pour chaque ligne du fichier CSV. L'application initiale de Patrick se présente comme suit :
Elle prend le résultat du fichier CSV d'entrée et l'importe dans l'ancienne base de données. Mettez maintenant à jour ce code pour écrire dans Firestore.
- Ouvrez le fichier
pet-theory/lab01/importTestData.js.
Pour référencer l'API Firestore via l'application, vous devez ajouter la dépendance des pairs au codebase existant.
- Ajoutez la dépendance Firestore suivante à la ligne 4 du fichier :
Assurez-vous que le haut du fichier se présente comme suit :
L'intégration avec la base de données Firestore peut se faire grâce à quelques lignes de code. Ruby vous a justement envoyé, à Patrick et à vous, des modèles de code dans ce but.
- Ajoutez la condition
if (process.argv.length < 3)ou le code suivant sous la ligne 9 :
L'extrait de code ci-dessus déclare un nouvel objet de base de données, qui fait référence à la base de données créée plus tôt dans l'atelier. La fonction utilise un traitement par lot. Chaque donnée du lot est traitée à tour de rôle et construit un document de référence basé sur l'identifiant ajouté. À la fin de la fonction, le contenu du lot est écrit dans la base de données.
- Enfin, vous devez ajouter un appel à la nouvelle fonction. Mettez à jour la fonction
importCsvpour ajouter l'appel de fonction writeToFirestore et retirer l'appel de fonction writeToDatabase. Votre écran devrait ressembler à ceci :
- Maintenant, ajoutez Logging à l'application. Pour référencer l'API Logging via l'application, ajoutez la dépendance des pairs au codebase existant. Ajoutez la ligne suivante juste en dessous des autres instructions "require" en haut du fichier :
Assurez-vous que le haut du fichier se présente comme suit :
- Ajoutez quelques variables constantes et initialisez le client Logging. Ajoutez-les juste en dessous des lignes ci-dessus dans le fichier (~ligne 5), comme ceci :
- Ajoutez du code pour écrire les journaux dans la fonction
importCsvsituée juste en dessous de la ligne "console.log(Wrote ${records.length} records);" qui doit se présenter comme suit :
Après ces mises à jour, votre bloc de code de la fonction importCsv devrait ressembler à ce qui suit :
Une fois le code d'application exécuté, la base de données Firestore sera mise à jour avec le contenu du fichier CSV. La fonction importCsv prend un nom de fichier et analyse le contenu ligne par ligne. Chaque ligne traitée est maintenant envoyée à la fonction writeToFirestore, où chaque nouvelle donnée est écrite dans la base de données "client".
Tâche 3 : Créer des données de test
Il est temps d'importer des données. Patrick contacte Ruby pour lui faire part de ses inquiétudes concernant l'utilisation de données réelles de clients pour son test...
|
Patrick, Administrateur informatique |
Bonjour Ruby, Je pense qu'il serait préférable que nous n'utilisions pas les données clients réelles pour les tests. Nous devons protéger la vie privée de nos clients, mais nous devons également être sûrs du bon fonctionnement de notre script d'importation de données. Auriez-vous une autre solution à proposer ? Patrick |
|
Ruby, Consultante en logiciels |
Bonjour Patrick, Bien vu. C'est un sujet délicat, car les données client peuvent comporter des informations personnelles. Je vais vous envoyer un code de démarrage pour créer des pseudo-données clients. Nous pourrons ensuite utiliser ces données pour tester le script d'importation. Ruby |

Aidez Patrick à mettre en place ce générateur de données pseudo-aléatoires.
- Tout d'abord, installez la bibliothèque "faker", qui sera utilisée par le script générant les fausses données clients. Exécutez la commande suivante pour mettre à jour la dépendance dans le fichier
package.json:
- Ouvrez maintenant le fichier nommé createTestData.js à l'aide de l'éditeur de code et examinez le code. Assurez-vous qu'il ressemble à ce qui suit :
- Ajoutez Logging pour le codebase. Sur la troisième ligne, ajoutez la référence suivante pour le module de l'API Logging à partir du code d'application :
Le haut du fichier devrait maintenant se présenter comme suit :
- Ajoutez maintenant quelques variables constantes et initialisez le client Logging. Ajoutez ces variables juste en dessous des instructions de
const:
- Ajoutez du code pour écrire les journaux dans la fonction createTestData située juste en dessous de la ligne "console.log(
Created file ${fileName} containing ${recordCount} records.);" qui doit se présenter comme suit :
- Après la mise à jour, le bloc de code de la fonction
createTestDatadevrait ressembler à ce qui suit :
- Exécutez la commande suivante pour configurer l'ID de votre projet dans Cloud Shell, en remplaçant PROJECT_ID par l'ID de votre projet Qwiklabs :
- Définissez maintenant l'ID du projet en tant que variable d'environnement :
- Exécutez la commande suivante dans Cloud Shell pour créer le fichier
customers_1000.csv, qui contiendra 1 000 enregistrements de données de test :
Vous devez obtenir un résultat semblable à celui-ci :
- Ouvrez le fichier
customers_1000.csvet vérifiez que les données de test ont bien été créées.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si vous avez réussi à créer un échantillon de données de test pour la base de données Firestore, vous verrez une note d'évaluation s'afficher.
Tâche 4 : Importer des données client de test
- Pour tester la capacité d'importation, utilisez le script d'importation et les données de test créées précédemment :
Vous devez obtenir un résultat semblable à celui-ci :
- Si vous obtenez une erreur du type :
Exécutez la commande suivante pour ajouter le package csv-parse à votre environnement :
- Puis, exécutez à nouveau la commande. Vous devez obtenir le résultat suivant :
- À ce stade, si vous avez l'esprit aventurier, n'hésitez pas à créer un fichier de données de test plus volumineux et à l'importer dans la base de données Firestore :
Vous devez obtenir un résultat semblable à celui-ci :
Dans les deux précédentes sections, vous avez vu comment Patrick et Ruby ont créé des données de test et un script pour importer des données dans Firestore. Patrick est maintenant plus à l'aise avec le chargement des données client dans la base de données Firestore.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si vous avez réussi à importer des échantillons de données de test dans la base de données Firestore, vous verrez un score d'évaluation s'afficher.
Tâche 5 : Examiner les données dans Firestore
Grâce à votre aide et à celle de Ruby, Patrick a maintenant réussi à migrer les données de test vers la base de données Firestore. Ouvrez Firestore et consultez les résultats.
- Revenez à l'onglet de la console Cloud. Dans le menu de navigation, cliquez sur Firestore. Cliquez ensuite sur l'icône en forme de crayon.
-
Saisissez
/customerset appuyez sur Entrée. -
Actualisez l'onglet de votre navigateur et la liste suivante de clients ayant migré doit s'afficher :
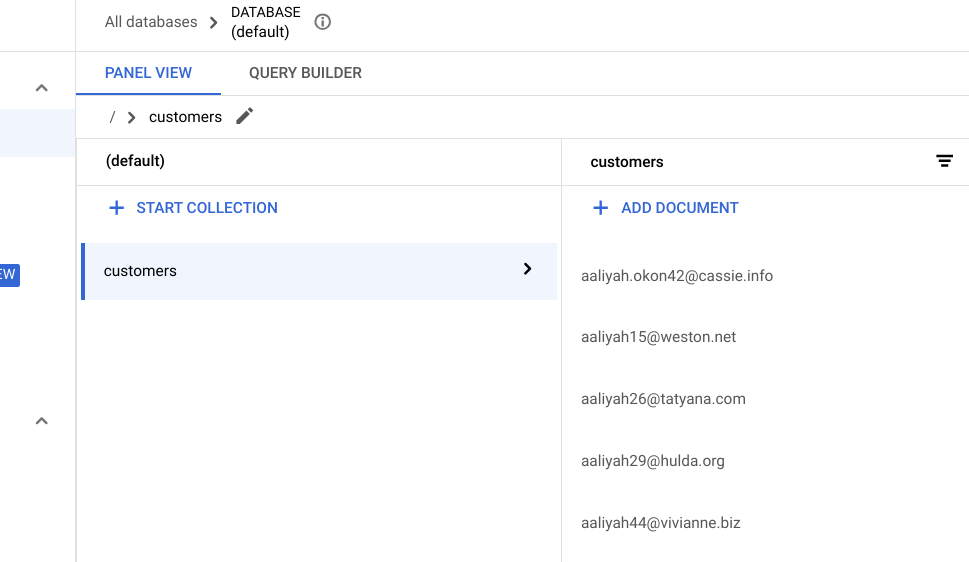
Félicitations !
Dans cet atelier, vous avez reçu une formation pratique à l'utilisation de Firestore. Après avoir généré un ensemble de données client pour les tests, vous avez exécuté un script qui a importé les données dans Firestore. Vous avez ensuite appris à manipuler les données dans Firestore à l'aide de la console Cloud.
Terminer votre quête
Cet atelier d'auto-formation fait partie des quêtes Google Cloud Run Serverless Workshop et Build Apps & Websites with Firebase. Une quête est une série d'ateliers associés qui constituent un parcours de formation. Si vous terminez une quête, vous obtenez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à n'importe quelle quête contenant cet atelier pour obtenir immédiatement les crédits associés. Découvrez toutes les quêtes disponibles dans le catalogue Google Cloud Skills Boost.
Atelier suivant
Continuez votre quête avec le prochain atelier de cette série, intitulé Créer une application Web sans serveur à l'aide de Firebase.
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 5 décembre 2023
Dernier test de l'atelier : 5 décembre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.