Checkpoints
Create test data for the Firestore Database
/ 50
Import test data into the Firestore Database
/ 50
Como importar dados para um banco de dados do Firestore
GSP642


Informações gerais
Nos laboratórios da Quest Google Cloud Serverless Workshop: Pet Theory, você terá acesso a um cenário de negócios fictício e vai ajudar os personagens com o plano deles de migração sem servidor.
Há 12 anos, Lilian fundou a rede de clínicas veterinárias Pet Theory. A Pet Theory teve rápida expansão nos últimos anos. Entretanto, o antigo sistema de agendamento de consultas não consegue dar conta do aumento da demanda. Por isso, Lilian está pedindo para você criar um sistema baseado na nuvem com uma escalonabilidade melhor do que a oferecida pela solução legada.
A equipe de operações da Pet Theory é formada por apenas uma pessoa, o Pedro. Assim, o cliente precisa de uma solução que não exija muita manutenção contínua. A equipe optou pela tecnologia sem servidor.
Ruby foi contratada como consultora para ajudar a Pet Theory a fazer a transição para um ambiente sem servidor. Depois de comparar as opções de banco de dados sem servidor, a equipe decide adotar o Cloud Firestore. Como o Firestore opera sem servidor, não é necessário provisionar capacidade previamente, e isso implica que não há risco de ultrapassar os limites de armazenamento ou de operações. O Firestore mantém os dados sincronizados em todos os apps cliente por meio de listeners em tempo real e oferece suporte off-line para dispositivos móveis e Web, de modo que seja possível criar apps responsivos que funcionem de maneira independente da latência da rede ou da conectividade com a internet.
Neste laboratório, você ajudará Pedro a fazer upload dos dados atuais da Pet Theory para um banco de dados do Cloud Firestore. Para realizar essa tarefa, ele trabalhará lado a lado com Ruby.
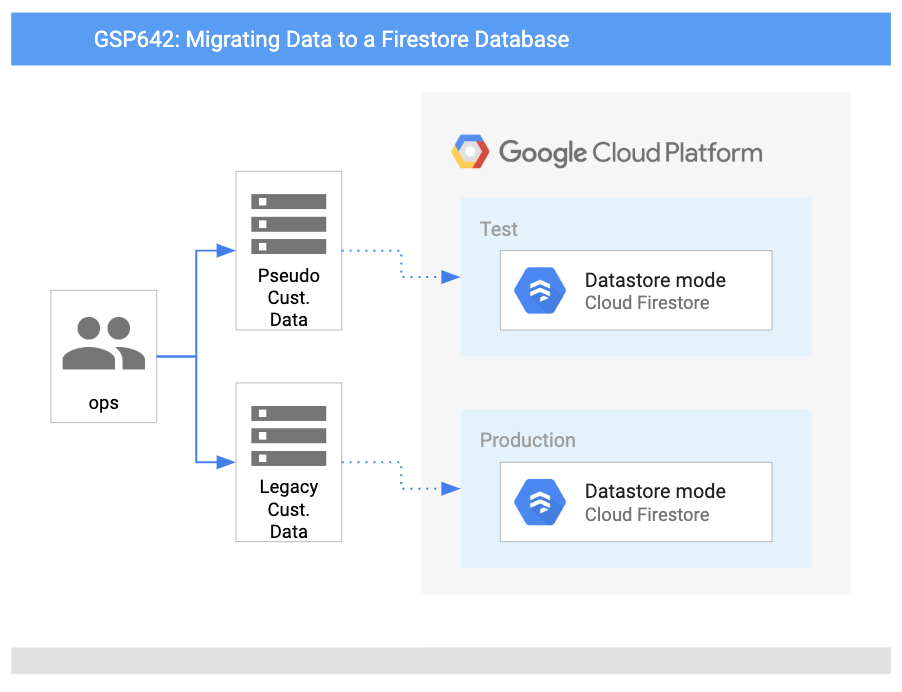
Arquitetura
Este diagrama mostra uma visão geral dos serviços que você vai usar e como eles se conectam:
O que você vai aprender
Neste laboratório, você vai aprender a:
- Configurar o Firestore no Google Cloud
- Criar um código de importação de banco de dados
- Gerar uma coleção de dados dos clientes para teste
- Importar os dados de teste dos clientes para o Firestore
Pré-requisitos
Este é um laboratório de nível fundamental que pressupõe experiência com o console do Cloud e os ambientes shell. A experiência com o Firebase será útil, mas não é obrigatória.
Você também precisa estar familiarizado com a edição de arquivos. Use seu editor de texto favorito (como o nano, o vi etc.) ou inicie o editor de código do Cloud Shell, disponível na barra de cima:

Quando estiver tudo pronto, role a tela para baixo e siga as etapas para configurar o ambiente do laboratório.
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Tarefa 1: configurar o Firestore no Google Cloud
A tarefa de Pedro é fazer o upload dos dados da Pet Theory para um banco de dados do Cloud Firestore. Para alcançar esta meta, ele trabalhará lado a lado com Ruby. Ruby recebe uma mensagem de Pedro na TI...
|
Pedro, administrador de TI |
Oi, Ruby O primeiro passo na transição para um ambiente sem servidor é criar um banco de dados do Firestore com o Google Cloud. Você pode me ajudar com essa tarefa? Não sei muito bem como fazer essa configuração. Pedro |
|
Ruby, consultora de software |
Olá, Pedro, Claro, é um prazer ajudar você com isso. Vou enviar alguns recursos para você começar. Voltamos a conversar sobre isso assim que você terminar a criação do banco de dados. Ruby |


Ajude Pedro a configurar um banco de dados do Firestore usando o console do Cloud.
-
No console do Cloud, acesse o menu de navegação e selecione Firestore.
-
Clique no botão Selecionar Modo nativo.
- O Modo Nativo é útil para permitir que vários usuários acessem simultaneamente os mesmos dados. Além disso, ele tem recursos como atualizações em tempo real e conexão direta entre seu banco de dados e um cliente da Web/para dispositivos móveis.
- O Modo Datastore destaca a alta capacidade de processamento (grande quantidade de leituras e gravações).
- No menu suspenso Selecionar um local, selecione a região
e clique em Criar banco de dados.
Depois de concluir a tarefa, Ruby envia um e-mail a Pedro...
|
Ruby, consultora de software |
Olá, Pedro, Excelente trabalho de configuração do banco de dados do Firestore! Para gerenciar o acesso ao banco de dados, usaremos uma conta de serviço que tenha sido criada automaticamente com os privilégios necessários. Agora estamos prontos para migrar do banco de dados antigo para o Firestore. Ruby |
|
Pedro, administrador de TI |
Olá, Ruby, Obrigado pela ajuda. Configurar o banco de dados do Firestore foi simples. Espero que o processo de importação do banco de dados seja mais fácil do que foi com o banco de dados legado, que é bastante complexo e exige a realização de muitas etapas. Pedro |

Tarefa 2: criar um código de importação de banco de dados
O novo banco de dados do Cloud Firestore está pronto para uso, mas está vazio. Os dados dos clientes da Pet Theory ainda estão apenas no banco de dados antigo.
Pedro envia uma mensagem a Ruby...
|
Pedro, administrador de TI |
Oi, Ruby, Meu gerente quer começar a migrar os dados de clientes para o novo banco de dados do Firestore. Eu exportei um arquivo CSV do banco de dados legado, mas não está claro para mim como fazer para exportar estes dados para o Firestore. Você pode me dar uma mão? Pedro |
|
Ruby, consultora de software |
Olá, Pedro, Claro. Vamos marcar uma reunião para discutir o que precisa ser feito. Ruby |

Como Pedro disse, os dados de cliente estarão disponíveis em um arquivo CSV. Ajude Pedro a criar um aplicativo que lê os registros dos clientes de um arquivo CSV e grava esses registros no Firestore. Como Pedro conhece o JavaScript, crie esse aplicativo com o ambiente de execução JavaScript Node.js.
- No Cloud Shell, execute o comando a seguir para clonar o repositório da Pet Theory:
- Use o editor de código do Cloud Shell (ou o editor da sua preferência) para alterar os arquivos. Na barra de cima da sessão do Cloud Shell, clique em Abrir editor. Uma nova guia será aberta. Se uma mensagem aparecer, clique em Abrir em uma nova janela para abrir o editor de código:
- Em seguida, troque o diretório de trabalho atual por
lab01:
No diretório, é possível conferir o package.json de Pedro. Este arquivo lista os pacotes que são dependências do projeto Node.js. Com ele, é possível reproduzir a build e compartilhá-la com outras pessoas.
Mostramos abaixo um exemplo de package.json:
Agora que Pedro já importou o código-fonte, ele entra em contato com Ruby para saber quais pacotes são necessários para a migração.
|
Pedro, administrador de TI |
Oi, Ruby, O código que usei para o banco de dados legado é bem básico, ele apenas cria um arquivo CSV pronto para o processo de importação. Preciso fazer o download de algo antes de começar? Pedro |
|
Ruby, consultora de software |
Oi, Pedro, Eu sugiro usar um dos muitos pacotes do nó de @google-cloud para interagir com o Firestore. Então, devemos fazer apenas pequenas alterações ao código, já que o trabalho pesado já foi feito. Ruby |
Para que o código de Pedro grave no banco de dados do Firestore, você precisa instalar algumas dependências de pares.
- Para isso, execute o seguinte comando:
- Para que o app possa gravar registros no Cloud Logging, instale mais um módulo:
Após a conclusão do comando, o package.json será automaticamente atualizado para incluir as novas dependências de pares e será semelhante à sequência abaixo.
Agora é hora de dar uma olhada no script que lê o arquivo CSV de clientes e grava um registro no Firestore para cada linha do arquivo CSV. O aplicativo original de Pedro é mostrado abaixo:
Ele importa a resposta do arquivo CSV de entrada para o banco de dados legado. A seguir, atualize este código para gravar no Firestore.
- Abra o arquivo
pet-theory/lab01/importTestData.js.
Para fazer referência à API Firestore por meio do aplicativo, é preciso adicionar a dependência de pares à base de código.
- Adicione a dependência do Firestore a seguir na linha 4 do arquivo:
O início do arquivo precisa ter este código:
A integração com o banco de dados do Firestore pode ser feita com algumas linhas de código. Exatamente com esse objetivo, Ruby compartilhou um código de modelo com você e Pedro.
- Adicione o código a seguir abaixo da linha 9 ou a condicional
if (process.argv.length < 3):
O snippet de código acima declara um novo objeto de banco de dados, que faz referência ao banco de dados criado anteriormente no laboratório. A função usa um processamento em lote no qual cada um dos registros é processado, um de cada vez, e define uma referência de documento com base no identificador adicionado. No final da função, o conteúdo do lote é gravado no banco de dados.
- Por último, você precisa adicionar uma chamada para a nova função. Na função
importCsv, adicione a chamada a writeToFirestore e remova a chamada a writeToDatabase. O código vai ficar assim:
- A seguir, adicione a geração de registros para o aplicativo. Para fazer referência à API Logging por meio do aplicativo, adicione a dependência de pares à base de código. Adicione a linha a seguir logo abaixo das outras instruções "require", no início do arquivo:
O início do arquivo precisa ter este código:
- Adicione algumas variáveis constantes e inicialize o cliente do Logging. Adicione essas constantes logo abaixo das linhas acima no arquivo (em torno da linha 5), da seguinte maneira:
- Adicione o código para gravar os registros na função
importCsvlogo abaixo da linha "console.log(Wrote ${records.length} records);", que deve ser semelhante ao seguinte:
Depois dessas mudanças, o bloco de código da função importCsv deve ficar assim:
Agora, quando o código do aplicativo for executado, o banco de dados do Firestore será atualizado com o conteúdo do arquivo CSV. A função importCsv recebe um nome de arquivo e analisa o conteúdo linha a linha. Cada linha processada é agora enviada para a função do Firestore writeToFirestore, em que cada novo registro é gravado no banco de dados de "clientes".
Tarefa 3. criar dados de teste
Está na hora de importar alguns dados! Pedro entra em contato com Ruby para falar sobre uma preocupação dele com a execução de um teste com dados reais de clientes...
|
Pedro, administrador de TI |
Oi, Ruby, Acho que seria melhor não usarmos os dados de clientes para os testes. Precisamos preservar a privacidade do cliente, mas também precisamos estar seguros de que nosso script de importação de dados funciona corretamente. Você consegue pensar em um método de teste alternativo? Pedro |
|
Ruby, consultora de software |
Olá, Pedro, Bem lembrado, Pedro. Essa é uma questão complicada, já que os dados do cliente podem incluir informações pessoais identificáveis, também chamadas de PII. Vou compartilhar com você um código inicial para criar dados de um pseudocliente. Poderemos usar esses dados para testar o script de importação. Ruby |

Ajude Pedro a instalar e colocar em operação esse gerador de dados pseudoaleatórios.
- Em primeiro lugar, instale a biblioteca "faker", que será usada pelo script que gera os dados de clientes fictícios. Execute o comando a seguir para atualizar a dependência em
package.json:
- Agora abra o arquivo chamado createTestData.js com o editor de código e inspecione o código. Ele deve ser semelhante a:
- Adicione o Logging para a base de código. Na linha 3, adicione a seguinte referência ao módulo da API Logging do código do aplicativo:
O início do arquivo deve ficar assim:
- Agora adicione algumas variáveis constantes e inicialize o cliente do Logging. Adicione este código logo abaixo das instruções
const:
- Adicione o código para gravar os registros na função createTestData logo abaixo da linha "console.log(
Created file ${fileName} containing ${recordCount} records.);" que será semelhante a:
- Depois da atualização, o bloco de código da função
createTestDatadeve ser semelhante ao seguinte:
- Execute o comando abaixo para configurar o ID do seu projeto no Cloud Shell. Substitua PROJECT_ID pelo ID do seu projeto do Qwiklabs:
- Agora defina o ID do projeto como uma variável de ambiente:
- Execute o comando a seguir no Cloud Shell para criar o arquivo
customers_1000.csv, que conterá mil registros de dados de teste:
A saída ficará assim:
- Abra o arquivo
customers_1000.csve verifique se os dados de teste foram criados.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você tiver criado com êxito dados de teste de amostra para o banco de dados do Firestore, verá uma pontuação de avaliação.
Tarefa 4: importar os dados de teste dos clientes
- Para testar a capacidade de importação, use o script de importação e os dados de teste criados previamente:
A saída ficará assim:
- Se você receber uma mensagem de erro que se assemelhe ao seguinte:
Execute o comando a seguir para adicionar o pacote csv-parse ao seu ambiente:
- Em seguida, execute o comando novamente. Você vai receber esta saída:
- Nesse ponto, se você quiser mostrar um pouco de ousadia, fique à vontade para criar um arquivo de teste maior e importar esse arquivo para o banco de dados do Firestore:
A saída ficará assim:
Nas últimas seções, você observou como Pedro e Ruby criaram dados de teste e um script para importar dados para o Firestore. Pedro agora está mais confiante para carregar dados de cliente no banco de dados do Firestore.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você importou com êxito os dados de teste de amostra para o banco de dados do Firestore, verá uma pontuação de avaliação.
Tarefa 5: inspecionar os dados no Firestore
Com sua ajuda e com a ajuda da Ruby, Pedro agora migrou os dados de teste para o banco de dados do Firestore. Abra o Firestore e confira os resultados!
- Volte à guia do console do Cloud. No Menu de navegação, clique em Firestore. Em seguida, clique no ícone de lápis.
-
Digite
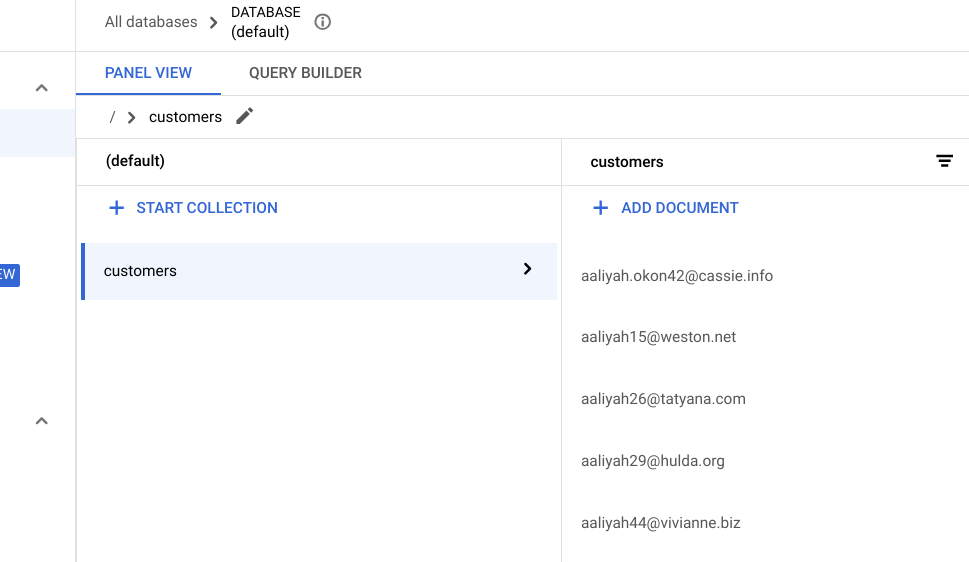
/customerse pressione Enter. -
Atualize a guia do navegador. A seguinte lista de clientes migrados será exibida:
Parabéns!
Durante este laboratório, você recebeu treinamento prático com o Firestore. Depois de gerar uma coleção de dados de clientes para teste, você executou um script que importou os dados para o Firestore. Você aprendeu a lidar com dados no Firestore por meio do console do Cloud.
Termine a Quest
Este laboratório autoguiado faz parte das Quests Google Cloud Run Serverless Workshop e Build Apps & Websites with Firebase. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. É possível publicar os selos e incluir um link para eles no seu currículo on-line ou nas redes sociais. Inscreva-se em qualquer Quest que tenha este laboratório para receber os créditos de conclusão na mesma hora. Consulte o catálogo do Google Cloud Ensina para ver todas as Quests disponíveis.
Comece o próximo laboratório
Continue aprendendo com o próximo laboratório na série, Criar um app da Web sem servidor com Firebase.
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 5 de dezembro de 2023
Laboratório testado em 5 de dezembro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.