Checkpoints
List the genai models with their descriptions
/ 20
Generate text using Gemini directly with Python SDK
/ 20
Generate text for Basic LLM chain using Gemini with LangChain
/ 20
Generate text for Basic Multi chain
/ 20
Generate text for a more complicated Chain - RAG
/ 20
Enhance Text Generation with RAG, LangChain, and Vertex AI
GSP1234

Overview
Gemini is a family of generative AI models developed by Google DeepMind that is designed for multimodal use cases. The Gemini API gives you access to the Gemini Pro Vision and Gemini Pro models.
LangChain is a powerful open-source Python framework designed to make the development of applications leveraging large language models (LLMs) easier and more efficient.
Retrieval Augmented Generation (RAG) is a technique that allows language models to access and utilize external knowledge sources (commonly a vector database) when generating text, making their responses more accurate and informed.
The benefits of using the RAG technique are the following:
- Improved Factual Accuracy: RAG helps language models stay grounded in real-world information, mitigating hallucinations (incorrect/fabricated statements) and ensuring outputs align with external sources
- Enhanced Reasoning: By accessing relevant knowledge, RAG improves the ability of language models to understand complex topics and generate more insightful responses.
- Adaptability to Changing Information: Since knowledge is actively retrieved from external sources, RAG facilitates updates and helps the language model stay current.
In this lab, you use a LangChain Chain to orchestrate steps required to query a vector database and submit the results of the query to Gemini to obtain results based on the knowledge base.
This is known as grounding and uses the results of the database query as context in addition to a query supplied by an end user when submitting a prompt to a large language model.
For the purposes of this lab, you use DocArray as the vector database which conveniently has a library available in LangChain making it simple to add to any LangChain application.
A local vector database can be useful during development cycles to iterate quickly on the generation of embeddings for a private knowledge base. In a real world scenario it is highly recommended to use a scalable, enterprise-grade vector database such as Vertex AI Vector Search.
Objectives
In this lab, you learn how to:
- Leverage the Gemini python SDK to generate content without LangChain
- Prepare a private knowledge base using DocArray to index embeddings of documents
-
Generate embeddings with Gemini. Use Gemini's
embedding-001model to create representations of text as vector data - Create a query-based retrieval system: retrieve relevant documents from the knowledge base based on an input query
-
Implement RAG with Gemini: Provide relevant context with a query submitted to a LLM, in this case, the
gemini-promodel to enhance generated results
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Retrieval Augmentation Generation (RAG) Overview
Retrieval-augmented generation (RAG) is a technique that combines the generative power of large language models (LLMs) with real-time fact retrieval from external knowledge sources to produce more accurate and informative text responses.
Why use RAG?
Using Retrieval Augmentation Generation (RAG) to overcome the limitations of standard LLMs, which can sometimes generate incorrect or misleading information due to gaps in their training data, and to ensure responses are grounded in the most up-to-date knowledge. The workflow looks similar to the diagram below.
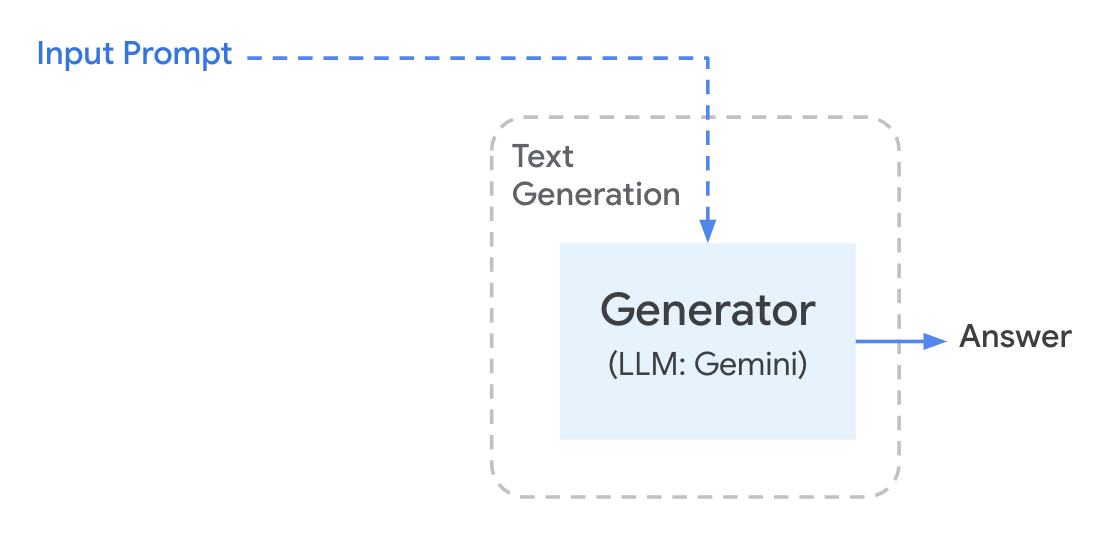
The issue with directly querying a Large Language Model is that they do not:
- know your business proprietary or domain specific data
- have real-time information once trained
- always provide accurate citation
To solve this issue retrieval augmentation generation, as very descriptly named, uses a private knowledge base to supplement contextual information with the submission of a prompt to a large language model in an effort to produce more factual resutls based on private data. The workflow looks similar to the diagram below.
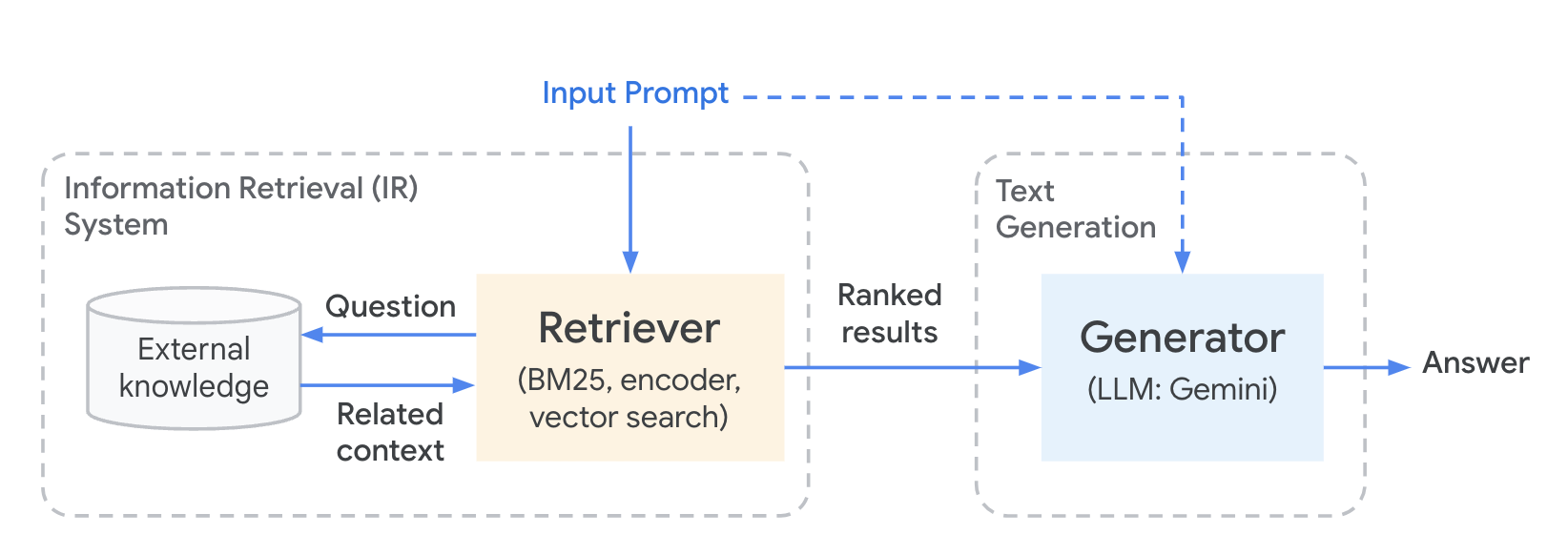
This effectively can have the following benefits over fine-tuning an existing ML model (Large Language Models, in particular, can be expensive to train):
- Utilizing RAG is cheaper than fine tuning an ML model
- The LLM model can be switched to different versions with the same knowledge base
- Document ingestion can happen on-demand, providing more real time data to use when generating content
- Answers provided by the LLM can be grounded using specific information cited from the document source
Task 1. Vertex AI Workbench
In your Google Cloud project, navigate to Vertex AI Workbench. In the top search bar, enter Vertex AI Workbench of the Google Cloud console.

- Go to User-managed-notebooks.
- Click Open JupyterLab for
generative-ai-jupyterlab. - The JupyterLab run in a new tab.

Task 2. Open the Jupyter Notebook
You use a pre-installed Jupyter notebook to run the steps of this lab.
- Click on the
gemini_langchain_rag.ipynbfile in the left file explorer. - Follow the steps in the notebook and run each cell one at a time.
Click Check my progress to verify the objectives of each step.
Using Gemini directly with Python SDK
Basic LLM Chain
Basic Multi Chain
A more complicated Chain - RAG
Congratulations!
Congratulations! You successfully integrated a private knowledge base with Gemini (LLM) using retrieval-augmented generation techniques, employing LangChain to coordinate knowledge retrieval and provide context-rich prompts to the LLM.
Next steps / learn more
- Check out the Generative AI on Vertex AI documentation.
- Learn more about Generative AI on the Google Cloud Tech YouTube channel.
- Google Cloud Generative AI official repo
- Example Gemini notebooks
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated April 3, 2024
Lab Last Tested April 3, 2024
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.